







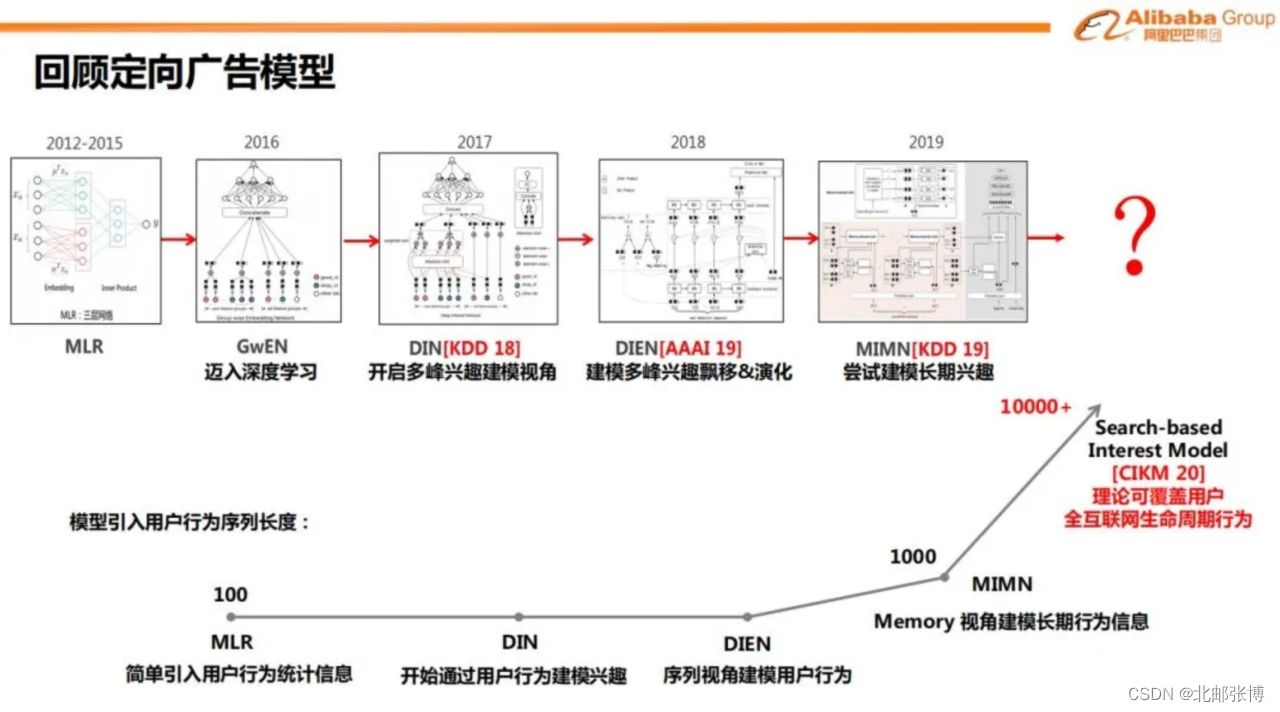
 文章探讨了阿里巴巴在用户兴趣建模上的演进,从DIN模型的多峰兴趣提取,到DINE引入GRU处理行为序列,再到MIMN解决长序列兴趣建模的存储和时延问题,以及SIM的多阶段过滤方法和DSIN的session兴趣分析。这些技术方案展示了如何通过深度学习优化广告精排,考虑用户兴趣的多样性和时间间隔对用户行为的影响。
文章探讨了阿里巴巴在用户兴趣建模上的演进,从DIN模型的多峰兴趣提取,到DINE引入GRU处理行为序列,再到MIMN解决长序列兴趣建模的存储和时延问题,以及SIM的多阶段过滤方法和DSIN的session兴趣分析。这些技术方案展示了如何通过深度学习优化广告精排,考虑用户兴趣的多样性和时间间隔对用户行为的影响。
目录
一、背景
阿里巴巴的精排模型从传统lr,到深度学习,再到对用户长历史序列进行建模的演变。传统的深度模型(如GwEN),一般采用Embedding&MLP的形式,它会将用户的所有兴趣信息转化为一个定长的向量。但用户的兴趣是多样的,定长的向量可能不足以表达。而且评估用户对于不同资源的兴趣时,应该使用不同的行为(判断用户是否喜欢衣服,应该关注用户对衣服的历史行为与兴趣程度;判断用户是否喜欢包包,则关注用户对包包的历史行为)。
因此盖坤团队提出DIN,从用户行为中提取与目标商品相关的多峰兴趣;DIN模型更多是从挖掘多峰兴趣角度出发,没有考虑行为的序列信息,兴趣的变化也能给模型提供信息,因此有了DIEN;这两个模型后,用户兴趣建模划分出了2个研究分支,一个是用户长期兴趣建模(MIMN、SIM),该分支依然是盖坤团队主导的;另一个分支则是从session的角度,对行为做进一步划分(DSIN)
二、技术方案
2.1 DIN
简介
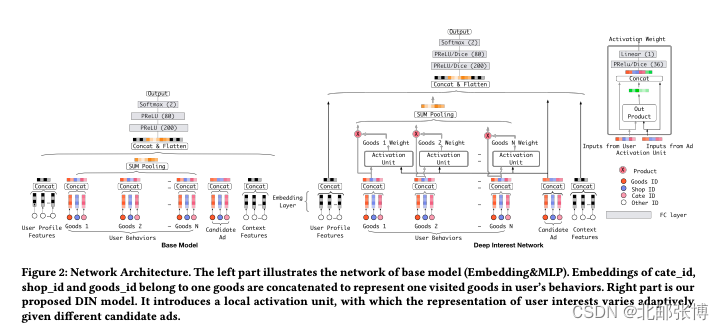
如上左图是传统的Embedding&MLP模型,处理行为数据采用sum-pooling得到定长的embedding。
这里行为的定义可以是广告点击、商品购买、加购物车等,每个行为节点由3个embedding拼接组成(商品ID、商品类别ID、商铺ID)
右图是DIN的模型结构,作者将每个行为节点与候选节点做交叉得到权重(即途中的activation unit),再通过weighted-sum-pooling的模型得到行为的embedding,这样,对于每个候选商品,提取的用户行为embedding是不同的。
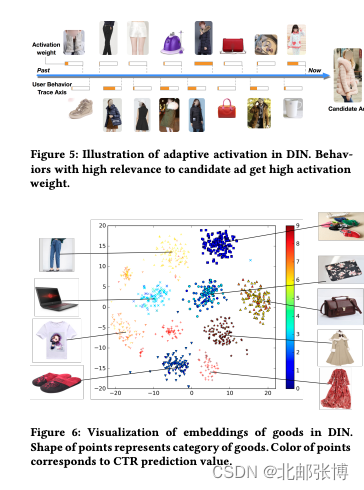
作者在实验部分可视化了activation unit的结果,和候选商品相关的行为节点会贡献较大的权重,符合认知
论文细节
这种行为兴趣的建模方式,在实际应用时会遇到一些问题
1、行为数据的参数量巨大(商品ID可能就百/千万),模型容易过拟合;引入L2正则,参数量大训练缓慢
2、针对不同的候选节点,用户的兴趣embedding不同,波动大会影响MLP部分的模型收敛
解决方案
1、提出Mini-batch Aware Regularization。L2正则缓慢的原因是每个mini-batch会对模型的所有参数做正则,但其实每个minibatch只使用了部分的商品ID。因此更好的做法是,每个mini-batch只对使用到的商品ID计算L2正则。实验证明,通过这种方式,能有效缓解过拟合现象,同时确保训练效率
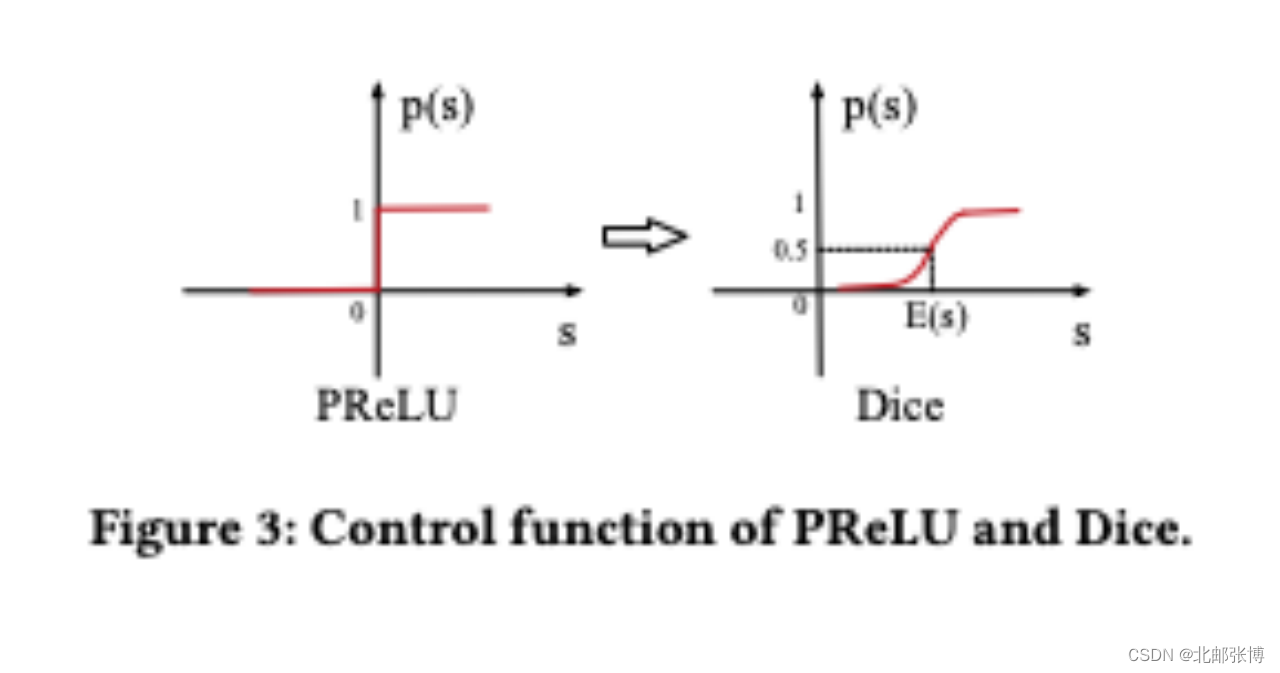
2、作者针对MLP部分的激活函数(PReLU)做优化,提出更具泛化性的Dice,这种激活函数可以根据输入数据的均值和方差,动态调整函数形态。在后续的论文中,模型也延用了这种激活函数
优缺点
1、该模型能动态获取用户的多种兴趣。但没有考虑行为的先后关系(序列)、兴趣的变化过程等
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4092
4092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









