






原文地址:http://www.codeproject.com/KB/IP/bipbuffer.aspx
继续上一篇的内容。。。
7 Characteristics of the Bip-Buffer BipBuffer的特点
The upshot of all of this is that on average, the buffer always has the maximal amount of free space available to be used, while not requiring any data copying or reallocation to free up space at the end of the buffer.
在绝大多数场合下,BipBuffer都可以充分利用全部缓冲区资源,而且即使到了缓冲区的末尾,也不需要任何数据拷贝或重新分配存储空间来实现循环利用缓冲区。
The biggest difference from an implementation standpoint between a regular circular buffer and the Bip Buffer is the fact that it only returns contiguous blocks. With a circular buffer, you need to worry about wrapping at the end of the buffer area - which is why for example if you look at Larry Antram's Fast Ring Buffer implementation, you'll see that you pass data into the buffer as a pointer and a length, the data from which is then copied byte by byte into the buffer to take into account the wrapping at the edges.
BipBuffer与常规的循环缓冲区相比较,最大的区别在于它可以返回连续的存储区。使用常规的循环缓冲区,需要考虑如何对缓冲区的末尾进行封装。这也是当看到Larry Antram's Fast Ring Buffer文章中对于循环缓冲区实现的时候,会发现需要传入数据缓冲区的指针以及数据的长度,然后数据会一个字节一个字节地拷贝到循环缓冲区中去(当然他的这种实现是需要考虑缓冲区的边界问题的。)
Another possibility which was brought up in the bulletin board (and the person who brought it up shall remain nameless, if just because they... erm... are nameless) was that of just splitting the calls across wraps. Well, this is one way of working around the wrapping problem, but it has the unfortunate side-effect that as your buffer fills, the amount of free space which you pass out to any calls always decreases to 1 byte at the minimum - even if you've got another 128kb of free space at the beginning of your buffer, at the end of it you're still going to have to deal with ever shrinking block sizes. The Bip-Buffer neatly sidesteps this issue by just leaving that space alone if the amount you request is larger than the remaining space at the end of the buffer. When writing networking code, this is very useful; you always want to try to receive as much data as possible, but you never can guarantee how much you're going to get. (For most optimal results, I'd recommend allocating a buffer which is some multiple of your MTU size).
Yes, you are going to lose some of what would have been free space at the end of the buffer. It's a small price to pay for playing nicely with the API.
Use of this buffer does require that one checks twice to see if the buffer has been emptied; as one has to deal with the possibility that there are two regions currently in use. However, the flexibility and performance gains outweigh this minor inconvenience.
class BipBuffer
{
private:
BYTE* pBuffer;
int ixa, sza, ixb, szb, buflen, ixResrv, szResrv;
public:
BipBuffer();
The constructor initializes the internal variables for tracking regions, and memory pointers to null; it does not allocate any memory for the buffer, in case one needs to use the class in an environment where exception handling cannot be used.
~BipBuffer();
The destructor simply frees any memory which has been allocated to the buffer.
bool AllocateBuffer(int buffersize = 4096);
AllocateBuffer allocates a buffer from virtual memory. The size of the buffer is rounded up to the nearest full page size. The function returns true if successful, or false if the buffer cannot be allocated.
void FreeBuffer();
FreeBuffer frees any memory allocated to the buffer by the call to AllocateBuffer, and releases any regions allocated within the Bip-Buffer.
bool IsInitialized() const;
IsInitialized returns true if the buffer has had memory allocated to it (by calling AllocateBuffer), or false if there is no memory allocated to the buffer.
int GetBufferSize() const;
GetBufferSize returns the total size (in bytes) of the buffer. This may be greater than the value passed into AllocateBuffer, if that value was not a multiple of the system's page size.
void Clear();
Clear ... well... clears the buffer. It does not free any memory allocated to the buffer; it merely resets the region pointers back to null, making the full buffer usable for new data again.
BYTE* Reserve(int size, OUT int& reserved);
Now to the nitty-gritty. Allocating data in the Bip-Buffer is a two-phase operation. First an area is reserved by calling the Reserve function; then, that area is Committed by calling the Commit function. This allows one to, say, reserve memory for an IO call, and when that IO call fails, pretend it never happened. Or alternatively, in a call to an overlapped WSARecv() function, it allows one to advertise how much memory is available to the network stack to use for incoming data, and then adjust the amount of space used based on how much data was actually read in (which may be less than the requested amount).
To use Reserve, pass in the size of block requested. The function will return the size of the largest free block available which is less than or equal to size in length in the reserved parameter you passed in. It will also return a BYTE* pointer to the area of the buffer which you have reserved.
In the case where the buffer has no space available, Reserve will return a NULL pointer, and reserved will be set to zero.
Note: you cannot nest calls to Reserve and Commit; after calling Reserve you must call Commit before calling Reserve again.
void Commit(int size);
Here's the other half of the allocation. Commit takes a size parameter, which is the number of bytes (starting at the BYTE* you were passed back from Reserve) which you have actually used and want to keep in the buffer. If you pass in zero for this size, the reservation will be completely released, as if you had never reserved any space at all. Alternatively, in a debug build, if one passes in a value greater than the original reservation, an assert will fire. (In a release build, the original reservation size will be used, and no one will be any the wiser). Committing data to the buffer makes it available for routines which take data back out of the buffer.
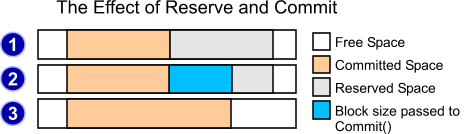
The diagram above shows how Reserve and Commit work. When you call Reserve, it will return a pointer to the beginning of the gray area above (fig. 1). Say you then only use as much of that buffer as the blue section (fig 2). It'd be a shame to leave this area allocated and going to waste, so you can call Commit with only as much data as you used, which gives you fig. 3 - namely, the committed space extends to fill just the part you needed, leaving the rest free.
int GetReservationSize() const;
If at any time you need to find out if you have a pending reservation, or need to find out that reservation's size, you can call GetReservationSize to find the amount reserved. No reservation? You'll get a zero back.
BYTE* GetContiguousBlock(OUT int& size);
Well, after all this work to put stuff into the buffer, we'd better have a way of getting it out again.
First of all, what if you need to work out how much data (total) is available to be read from the buffer?
int GetCommittedSize() const;
One method is to call GetCommittedSize, which will return the total length of data in the buffer - that's the total size of both regions combined. I would not recommend relying on this number, because it's very easy to forget that you have two regions in the Bip-Buffer if you do. And that would be a bad thing (as several weeks of painful debugging experience has proved to me). As an alternative, you can call:
BYTE* GetContiguousBlock(OUT int& size);
... which will return a BYTE* pointer to the first (as in FIFO, not left-most) contiguous region of committed data in the buffer. The size parameter is also updated with the length of the block. If no data is available, the function returns NULL (and the size parameter is set to zero).
In order to fully empty the buffer, you may wish to loop around, calling GetContiguousBlock until it returns NULL. If you're feeling miserly, you can call it only twice. However, I'd recommend the former; it means you can forget that there's two regions, and just remember that there's more than one.
void DecommitBlock(int size);
So what do you do after you've consumed data from the buffer? Well, in keeping with the spirit of the aforementioned Reserve and Commit calls, you then call DecommitBlock to release data from it. Data is released in FIFO order, from the first contiguous block only - so if you're going to call DecommitBlock, you should do it pretty shortly after calling GetContiguousBlock. If you pass in a size of greater than the length of the contiguous block, then the entire block is released - but none of the other block (if present) is released at all. This is a deliberate design choice to remind you that there is more than one block and you should act accordingly. (If you really need to be able to discard data from blocks you've not read yet, it's not too difficult to copy the DecommitBlock function and modify it so that it operates on both blocks; just unwrap the if statement, and adjust the size parameter after the first clause. Implementation of this is left as the dreaded youknowwhat).
And that's the Bip-Buffer implementation done. A short example of how to use it is provided below.














 9199
9199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









