







@author: huangyongye
1. RNN基础
对于RNN,我看到讲得最通俗易懂的应该是Andrej发的博客:
The Unreasonable Effectiveness of Recurrent Neural Networks
这里有它的中文翻译版本:
递归神经网络不可思议的有效性
如果想了解 LSTM 的原理,可以参考这篇文章:(译)理解 LSTM 网络 (Understanding LSTM Networks by colah)。
下面的连接中对RNN还有BPTT(RNN的反向传播算法),LSTM和GRU的原理和实现讲解得也是非常棒:
http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
2.seq2seq
2.1 seq2seq 模型分析
首先介绍几篇比较重要的 seq2seq 相关的论文:
[1] Cho et al., 2014 . Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
[2] Sutskever et al., 2014. Sequence to Sequence Learning with Neural Networks
[3] Bahdanau et al., 2014. Neural Machine Translation by Jointly Learning to Align and Translate
[4] Jean et. al., 2014. On Using Very Large Target Vocabulary for Neural Machine Translation
[5] Vinyals et. al., 2015. A Neural Conversational Model[J]. Computer Science
顾名思义,seq2seq 模型就像一个翻译模型,输入是一个序列(比如一个英文句子),输出也是一个序列(比如该英文句子所对应的法文翻译)。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。
举个栗子
在机器翻译:输入(hello) -> 输出 (你好)。输入是1个英文单词,输出为2个汉字。
在对话机器中:我们提(输入)一个问题,机器会自动生成(输出)回答。这里的输入和输出显然是长度没有确定的序列(sequences).
要知道,在以往的很多模型中,我们一般都说输入特征矩阵,每个样本对应矩阵中的某一行。就是说,无论是第一个样本还是最后一个样本,他们都有一样的特征维度。但是对于翻译这种例子,难道我们要让每一句话都有一样的字数吗,那样的话估计五言律诗和七言绝句又能大火一把了,哈哈。但是这不科学呀,所以就有了 seq2seq 这种结构。
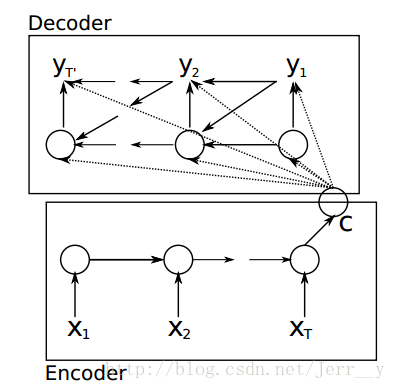
图1. 论文[1] 模型按时间展开的结构
论文[1]Cho et al. 算是比较早提出 Encoder-Decoder 这种结构的,其中 Encoder 部分应该是非常容易理解的,就是一个RNNCell(RNN ,GRU,LSTM 等) 结构。每个 timestep, 我们向 Encoder 中输入一个字/词(一般是表示这个字/词的一个实数向量),直到我们输入这个句子的最后一个字/词 XT ,然后输出整个句子的语义向量 c(一般情况下, c=hXT , XT 是最后一个输入)。因为 RNN 的特点就是把前面每一步的输入信息都考虑进来了,所以理论上这个 c 就能够把整个句子的信息都包含了,我们可以把
论文[1] 中的公式表示如下:
同样,根据 h<t> 我们就能够求出 yt 的条件概率:
这里有两个函数 f 和 g , 一般来说,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









