









背景建模与前景检测(Background Generation And Foreground Detection)
http://www.cnblogs.com/xrwang/archive/2010/02/21/ForegroundDetection.html
作者:王先荣
前言
在很多情况下,我们需要从一段视频或者一系列图片中找到感兴趣的目标,比如说当人进入已经打烊的超市时发出警报。为了达到这个目的,我们首先需要“学习”背景模型,然后将背景模型和当前图像进行比较,从而得到前景目标。

背景建模
背景与前景都是相对的概念,以高速公路为例:有时我们对高速公路上来来往往的汽车感兴趣,这时汽车是前景,而路面以及周围的环境是背景;有时我们仅仅对闯入高速公路的行人感兴趣,这时闯入者是前景,而包括汽车之类的其他东西又成了背景。背景建模的方式很多,或高级或简单。不过各种背景模型都有自己适用的场合,即使是高级的背景模型也不能适用于任何场合。下面我将逐一介绍OpenCv中已经实现,或者在《学习OpenCv》这本书中介绍的背景建模方法。
1.帧差
帧差可说是最简单的一种背景模型,指定视频中的一幅图像为背景,用当前帧与背景进行比较,根据需要过滤较小的差异,得到的结果就是前景了。OpenCv中为我们提供了一种动态计算阀值,然后用帧差进行前景检测的函数——cvChangeDetection(注:EmguCv中没有封装 cvChangeDetection,我将其声明到OpenCvInvoke类中,具体实现见文末代码)。而通过对两幅图像使用减法运算,然后再用指定阀值过滤的方法在《学习OpenCv》一书中有详细的介绍。它们的实现代码如下:
 帧差
帧差

[DllImport(
"
cvaux200.dll
"
)]
public
static
extern
void
cvChangeDetection(IntPtr prev_frame, IntPtr curr_frame, IntPtr change_mask);
//
backgroundMask为背景,imageBackgroundModel为背景模型,currentFrame为当前帧
if
(backgroundMask
==
null
)
backgroundMask
=
new
Image
<
Gray,
byte
>
(imageBackgroundModel.Size);
if
(threshold
==
0d)
//
如果阀值为0,使用OpenCv中的自适应动态背景检测
OpenCvInvoke.cvChangeDetection(imageBackgroundModel.Ptr, currentFrame.Ptr, backgroundMask.Ptr);
else
{
//
如果设置了阀值,使用帧差
Image
<
TColor, Byte
>
imageTemp
=
imageBackgroundModel.AbsDiff(currentFrame);
Image
<
Gray, Byte
>
[] images
=
imageTemp.Split();
backgroundMask.SetValue(0d);
foreach
(Image
<
Gray, Byte
>
image
in
images)
backgroundMask._Or(image.ThresholdBinary(
new
Gray(threshold),
new
Gray(255d)));
}
backgroundMask._Not();
对于类似无人值守的仓库防盗之类的场合,使用帧差效果估计很好。
2.背景统计模型
背景统计模型是:对一段时间的背景进行统计,然后计算其统计数据(例如平均值、平均差分、标准差、均值漂移值等等),将统计数据作为背景的方法。 OpenCv中并未实现简单的背景统计模型,不过在《学习OpenCv》中对其中的平均背景统计模型有很详细的介绍。在模仿该算法的基础上,我实现了一系列的背景统计模型,包括:平均背景、均值漂移、标准差和标准协方差。对这些统计概念我其实不明白,在维基百科上看了好半天 -_-
调用背景统计模型很简单,只需4步而已:
// (1)初始化对象 BackgroundStatModelBase < Bgr > bgModel = new BackgroundStatModelBase < Bgr > (BackgroundStatModelType.AccAvg); // (2)更新一段时间的背景图像,视情况反复调用(2) bgModel.Update(image); // (3)设置当前帧 bgModel.CurrentFrame = currentFrame; // (4)得到背景或者前景 Image < Gray,Byte > imageForeground = bgModel.ForegroundMask;
背景统计模型的实现代码如下:
 实现背景统计模型
实现背景统计模型
3.编码本背景模型
编码本的基本思路是这样的:针对每个像素在时间轴上的变动,建立多个(或者一个)包容近期所有变化的Box(变动范围);在检测时,用当前像素与Box去比较,如果当前像素落在任何Box的范围内,则为背景。
在OpenCv中已经实现了编码本背景模型,不过实现方式与《学习OpenCv》中提到的方式略有不同,主要有:(1)使用单向链表来容纳Code Element;(2)清除消极的Code Element时,并未重置t。OpenCv中的以下函数与编码本背景模型相关:
cvCreateBGCodeBookModel 建立背景模型
cvBGCodeBookUpdate 更新背景模型
cvBGCodeBookClearStale 清除消极的Code Element
cvBGCodeBookDiff 计算得到背景与前景(注意:该函数仅仅设置背景像素为0,而对前景像素未处理,因此在调用前需要将所有的像素先置为前景)
cvReleaseBGCodeBookModel 释放资源
在EmguCv中只实现了一部分编码本背景模型,在类BGCodeBookModel<TColor>中,可惜它把cvBGCodeBookDiff给搞忘记了 -_-
下面的代码演示了如果使用编码本背景模型:
编码本模型
//
(1)初始化对象
if
(rbCodeBook.Checked)
{
if
(bgCodeBookModel
!=
null
)
{
bgCodeBookModel.Dispose();
bgCodeBookModel
=
null
;
}
bgCodeBookModel
=
new
BGCodeBookModel
<
Bgr
>
();
}
//
(2)背景建模或者前景检测
bool
stop
=
false
;
while
(
!
stop)
{
Image
<
Bgr, Byte
>
image
=
capture.QueryFrame().Clone();
//
当前帧
bool
isBgModeling, isFgDetecting;
//
是否正在建模,是否正在前景检测
lock
(lockObject)
{
stop
=
!
isVideoCapturing;
isBgModeling
=
isBackgroundModeling;
isFgDetecting
=
isForegroundDetecting;
}
//
得到设置的参数
SettingParam param
=
(SettingParam)
this
.Invoke(
new
GetSettingParamDelegate(GetSettingParam));
//
code book
if
(param.ForegroundDetectType
==
ForegroundDetectType.CodeBook)
{
if
(bgCodeBookModel
!=
null
)
{
//
背景建模
if
(isBgModeling)
{
bgCodeBookModel.Update(image);
//
背景建模一段时间之后,清理陈旧的条目 (因为清理操作不会重置t,所以这里用求余数的办法来决定清理的时机)
if
(backgroundModelFrameCount
%
CodeBookClearPeriod
==
CodeBookClearPeriod
-
1
)
bgCodeBookModel.ClearStale(CodeBookStaleThresh, Rectangle.Empty,
null
);
backgroundModelFrameCount
++
;
pbBackgroundModel.Image
=
bgCodeBookModel.BackgroundMask.Bitmap;
//
如果达到最大背景建模次数,停止背景建模
if
(param.MaxBackgroundModelFrameCount
!=
0
&&
backgroundModelFrameCount
>
param.MaxBackgroundModelFrameCount)
this
.Invoke(
new
NoParamAndReturnDelegate(StopBackgroundModel));
}
//
前景检测
if
(isFgDetecting)
{
Image
<
Gray, Byte
>
imageFg
=
new
Image
<
Gray,
byte
>
(image.Size);
imageFg.SetValue(255d);
//
CodeBook在得出前景时,仅仅将背景像素置零,所以这里需要先将所有的像素都假设为前景
CvInvoke.cvBGCodeBookDiff(bgCodeBookModel.Ptr, image.Ptr, imageFg.Ptr, Rectangle.Empty);
pbBackgroundModel.Image
=
imageFg.Bitmap;
}
}
}
//
更新视频图像
pbVideo.Image
=
image.Bitmap;
}
//
(3)释放对象
if
(bgCodeBookModel
!=
null
)
{
try
{
bgCodeBookModel.Dispose();
}
catch
{ }
}
4.高级背景统计模型
在OpenCv还实现了两种高级的背景统计模型,它们为别是:(1)FGD——复杂背景下的前景物体检测(Foreground object detection from videos containing complex background);(2)MOG——高斯混合模型(Mixture Of Gauss)。包括以下函数:
CvCreateFGDetectorBase 建立前景检测对象
CvFGDetectorProcess 更新前景检测对象
CvFGDetectorGetMask 获取前景
CvFGDetectorRelease 释放资源
EmguCv将其封装到类FGDetector<TColor>中。我个人觉得OpenCv在实现这个模型的时候做得不太好,因为它将背景建模和前景检测糅合到一起了,无论你是否愿意,在建模的过程中也会检测前景,而只希望前景检测的时候,同时也会建模。我比较喜欢将背景建模和前景检测进行分离的设计。
调用的过程很简单,代码如下:
高级背景统计模型
前景检测
在建立好背景模型之后,通过对当前图像及背景的某种比较,我们可以得出前景。在上面的介绍中,已经包含了对前景的代码,在此不再重复。一般情况下,得到的前景包含了很多噪声,为了消除噪声,我们可以对前景图像进行开运算及闭运算,然后再丢弃比较小的轮廓。
本文的代码
本文代码
using
System;
using
System.Collections.Generic;
using
System.ComponentModel;
using
System.Data;
using
System.Drawing;
using
System.Linq;
using
System.Text;
using
System.Windows.Forms;
using
System.Diagnostics;
using
System.Runtime.InteropServices;
using
System.Threading;
using
Emgu.CV;
using
Emgu.CV.CvEnum;
using
Emgu.CV.Structure;
using
Emgu.CV.UI;
using
Emgu.CV.VideoSurveillance;
namespace
ImageProcessLearn
{
public
partial
class
FormForegroundDetect : Form
{
//
成员变量
Capture capture
=
null
;
//
视频捕获对象
Thread captureThread
=
null
;
//
视频捕获线程
private
bool
isVideoCapturing
=
true
;
//
是否正在捕获视频
private
bool
isBackgroundModeling
=
false
;
//
是否正在背景建模
private
int
backgroundModelFrameCount
=
0
;
//
已经建模的视频帧数
private
bool
isForegroundDetecting
=
false
;
//
是否正在进行前景检测
private
object
lockObject
=
new
object
();
//
用于锁定的对象
//
各种前景检测方法对应的对象
BGCodeBookModel
<
Bgr
>
bgCodeBookModel
=
null
;
//
编码本前景检测
private
const
int
CodeBookClearPeriod
=
40
;
//
编码本的清理周期,更新这么多次背景之后,清理掉很少使用的陈旧条目
private
const
int
CodeBookStaleThresh
=
20
;
//
在清理编码本时,使用的阀值(stale大于该阀值的条目将被删除)
FGDetector
<
Bgr
>
fgDetector
=
null
;
//
Mog或者Fgd检测
BackgroundStatModelFrameDiff
<
Bgr
>
bgModelFrameDiff
=
null
;
//
帧差
BackgroundStatModelAccAvg
<
Bgr
>
bgModelAccAvg
=
null
;
//
平均背景
BackgroundStatModelRunningAvg
<
Bgr
>
bgModelRunningAvg
=
null
;
//
均值漂移
BackgroundStatModelSquareAcc
<
Bgr
>
bgModelSquareAcc
=
null
;
//
标准方差
BackgroundStatModelMultiplyAcc
<
Bgr
>
bgModelMultiplyAcc
=
null
;
//
标准协方差
public
FormForegroundDetect()
{
InitializeComponent();
}
//
窗体加载时
private
void
FormForegroundDetect_Load(
object
sender, EventArgs e)
{
//
设置Tooltip
toolTip.Active
=
true
;
toolTip.SetToolTip(rbMog,
"
高斯混合模型(Mixture Of Gauss)
"
);
toolTip.SetToolTip(rbFgd,
"
复杂背景下的前景物体检测(Foreground object detection from videos containing complex background)
"
);
toolTip.SetToolTip(txtMaxBackgroundModelFrameCount,
"
在背景建模时,使用的最大帧数,超出该值之后,将自动停止背景建模。\r\n对于帧差,总是只捕捉当前帧作为背景。\r\n如果设为零,背景检测将不会自动停止。
"
);
//
打开摄像头视频捕获线程
capture
=
new
Capture(
0
);
captureThread
=
new
Thread(
new
ParameterizedThreadStart(CaptureWithEmguCv));
captureThread.Start(
null
);
}
//
窗体关闭前
private
void
FormForegroundDetect_FormClosing(
object
sender, FormClosingEventArgs e)
{
//
终止视频捕获
isVideoCapturing
=
false
;
if
(captureThread
!=
null
)
captureThread.Abort();
if
(capture
!=
null
)
capture.Dispose();
//
释放对象
if
(bgCodeBookModel
!=
null
)
{
try
{
bgCodeBookModel.Dispose();
}
catch
{ }
}
if
(fgDetector
!=
null
)
{
try
{
fgDetector.Dispose();
}
catch
{ }
}
if
(bgModelFrameDiff
!=
null
)
bgModelFrameDiff.Dispose();
if
(bgModelAccAvg
!=
null
)
bgModelAccAvg.Dispose();
if
(bgModelRunningAvg
!=
null
)
bgModelRunningAvg.Dispose();
if
(bgModelSquareAcc
!=
null
)
bgModelSquareAcc.Dispose();
if
(bgModelMultiplyAcc
!=
null
)
bgModelMultiplyAcc.Dispose();
}
//
EmguCv视频捕获
private
void
CaptureWithEmguCv(
object
objParam)
{
if
(capture
==
null
)
return
;
bool
stop
=
false
;
while
(
!
stop)
{
Image
<
Bgr, Byte
>
image
=
capture.QueryFrame().Clone();
//
当前帧
bool
isBgModeling, isFgDetecting;
//
是否正在建模,是否正在前景检测
lock
(lockObject)
{
stop
=
!
isVideoCapturing;
isBgModeling
=
isBackgroundModeling;
isFgDetecting
=
isForegroundDetecting;
}
//
得到设置的参数
SettingParam param
=
(SettingParam)
this
.Invoke(
new
GetSettingParamDelegate(GetSettingParam));
//
code book
if
(param.ForegroundDetectType
==
ForegroundDetectType.CodeBook)
{
if
(bgCodeBookModel
!=
null
&&
(isBgModeling
||
isFgDetecting))
{
//
背景建模
if
(isBgModeling)
{
bgCodeBookModel.Update(image);
//
背景建模一段时间之后,清理陈旧的条目
if
(backgroundModelFrameCount
%
CodeBookClearPeriod
==
CodeBookClearPeriod
-
1
)
bgCodeBookModel.ClearStale(CodeBookStaleThresh, Rectangle.Empty,
null
);
backgroundModelFrameCount
++
;
pbBackgroundModel.Image
=
bgCodeBookModel.BackgroundMask.Bitmap;
//
如果达到最大背景建模次数,停止背景建模
if
(param.MaxBackgroundModelFrameCount
!=
0
&&
backgroundModelFrameCount
>
param.MaxBackgroundModelFrameCount)
this
.Invoke(
new
NoParamAndReturnDelegate(StopBackgroundModel));
}
//
前景检测
if
(isFgDetecting)
{
Image
<
Gray, Byte
>
imageFg
=
new
Image
<
Gray,
byte
>
(image.Size);
imageFg.SetValue(255d);
//
CodeBook在得出前景时,仅仅将背景像素置零,所以这里需要先将所有的像素都假设为前景
CvInvoke.cvBGCodeBookDiff(bgCodeBookModel.Ptr, image.Ptr, imageFg.Ptr, Rectangle.Empty);
pbBackgroundModel.Image
=
imageFg.Bitmap;
}
}
}
//
fgd or mog
else
if
(param.ForegroundDetectType
==
ForegroundDetectType.Fgd
||
param.ForegroundDetectType
==
ForegroundDetectType.Mog)
{
if
(fgDetector
!=
null
&&
(isBgModeling
||
isFgDetecting))
{
//
背景建模
fgDetector.Update(image);
backgroundModelFrameCount
++
;
pbBackgroundModel.Image
=
fgDetector.BackgroundMask.Bitmap;
//
如果达到最大背景建模次数,停止背景建模
if
(param.MaxBackgroundModelFrameCount
!=
0
&&
backgroundModelFrameCount
>
param.MaxBackgroundModelFrameCount)
this
.Invoke(
new
NoParamAndReturnDelegate(StopBackgroundModel));
//
前景检测
if
(isFgDetecting)
{
pbBackgroundModel.Image
=
fgDetector.ForgroundMask.Bitmap;
}
}
}
//
帧差
else
if
(param.ForegroundDetectType
==
ForegroundDetectType.FrameDiff)
{
if
(bgModelFrameDiff
!=
null
)
{
//
背景建模
if
(isBgModeling)
{
bgModelFrameDiff.Update(image);
backgroundModelFrameCount
++
;
this
.Invoke(
new
NoParamAndReturnDelegate(StopBackgroundModel));
//
对于帧差,只需要捕获当前帧作为背景即可
}
//
前景检测
if
(isFgDetecting)
{
bgModelFrameDiff.Threshold
=
param.Threshold;
bgModelFrameDiff.CurrentFrame
=
image;
pbBackgroundModel.Image
=
bgModelFrameDiff.ForegroundMask.Bitmap;
}
}
}
//
平均背景
else
if
(param.ForegroundDetectType
==
ForegroundDetectType.AccAvg)
{
if
(bgModelAccAvg
!=
null
)
{
//
背景建模
if
(isBgModeling)
{
bgModelAccAvg.Update(image);
backgroundModelFrameCount
++
;
//
如果达到最大背景建模次数,停止背景建模
if
(param.MaxBackgroundModelFrameCount
!=
0
&&
backgroundModelFrameCount
>
param.MaxBackgroundModelFrameCount)
this
.Invoke(
new
NoParamAndReturnDelegate(StopBackgroundModel));
}
//
前景检测
if
(isFgDetecting)
{
bgModelAccAvg.CurrentFrame
=
image;
pbBackgroundModel.Image
=
bgModelAccAvg.ForegroundMask.Bitmap;
}
}
}
//
均值漂移
else
if
(param.ForegroundDetectType
==
ForegroundDetectType.RunningAvg)
{
if
(bgModelRunningAvg
!=
null
)
{
//
背景建模
if
(isBgModeling)
{
bgModelRunningAvg.Update(image);
backgroundModelFrameCount
++
;
//
如果达到最大背景建模次数,停止背景建模
if
(param.MaxBackgroundModelFrameCount
!=
0
&&
backgroundModelFrameCount
>
param.MaxBackgroundModelFrameCount)
this
.Invoke(
new
NoParamAndReturnDelegate(StopBackgroundModel));
}
//
前景检测
if
(isFgDetecting)
{
bgModelRunningAvg.CurrentFrame
=
image;
pbBackgroundModel.Image
=
bgModelRunningAvg.ForegroundMask.Bitmap;
}
}
}
//
计算方差
else
if
(param.ForegroundDetectType
==
ForegroundDetectType.SquareAcc)
{
if
(bgModelSquareAcc
!=
null
)
{
//
背景建模
if
(isBgModeling)
{
bgModelSquareAcc.Update(image);
backgroundModelFrameCount
++
;
//
如果达到最大背景建模次数,停止背景建模
if
(param.MaxBackgroundModelFrameCount
!=
0
&&
backgroundModelFrameCount
>
param.MaxBackgroundModelFrameCount)
this
.Invoke(
new
NoParamAndReturnDelegate(StopBackgroundModel));
}
//
前景检测
if
(isFgDetecting)
{
bgModelSquareAcc.CurrentFrame
=
image;
pbBackgroundModel.Image
=
bgModelSquareAcc.ForegroundMask.Bitmap;
}
}
}
//
协方差
else
if
(param.ForegroundDetectType
==
ForegroundDetectType.MultiplyAcc)
{
if
(bgModelMultiplyAcc
!=
null
)
{
//
背景建模
if
(isBgModeling)
{
bgModelMultiplyAcc.Update(image);
backgroundModelFrameCount
++
;
//
如果达到最大背景建模次数,停止背景建模
if
(param.MaxBackgroundModelFrameCount
!=
0
&&
backgroundModelFrameCount
>
param.MaxBackgroundModelFrameCount)
this
.Invoke(
new
NoParamAndReturnDelegate(StopBackgroundModel));
}
//
前景检测
if
(isFgDetecting)
{
bgModelMultiplyAcc.CurrentFrame
=
image;
pbBackgroundModel.Image
=
bgModelMultiplyAcc.ForegroundMask.Bitmap;
}
}
}
//
更新视频图像
pbVideo.Image
=
image.Bitmap;
}
}
//
用于在工作线程中更新结果的委托及方法
private
delegate
void
AddResultDelegate(
string
result);
private
void
AddResultMethod(
string
result)
{
//
txtResult.Text += result;
}
//
用于在工作线程中获取设置参数的委托及方法
private
delegate
SettingParam GetSettingParamDelegate();
private
SettingParam GetSettingParam()
{
ForegroundDetectType type
=
ForegroundDetectType.FrameDiff;
if
(rbFrameDiff.Checked)
type
=
ForegroundDetectType.FrameDiff;
else
if
(rbAccAvg.Checked)
type
=
ForegroundDetectType.AccAvg;
else
if
(rbRunningAvg.Checked)
type
=
ForegroundDetectType.RunningAvg;
else
if
(rbMultiplyAcc.Checked)
type
=
ForegroundDetectType.MultiplyAcc;
else
if
(rbSquareAcc.Checked)
type
=
ForegroundDetectType.SquareAcc;
else
if
(rbCodeBook.Checked)
type
=
ForegroundDetectType.CodeBook;
else
if
(rbMog.Checked)
type
=
ForegroundDetectType.Mog;
else
type
=
ForegroundDetectType.Fgd;
int
maxFrameCount
=
0
;
int
.TryParse(txtMaxBackgroundModelFrameCount.Text,
out
maxFrameCount);
double
threshold
=
15d;
double
.TryParse(txtThreshold.Text,
out
threshold);
if
(threshold
<=
0
)
threshold
=
15d;
return
new
SettingParam(type, maxFrameCount, threshold);
}
//
没有参数及返回值的委托
private
delegate
void
NoParamAndReturnDelegate();
//
开始背景建模
private
void
btnStartBackgroundModel_Click(
object
sender, EventArgs e)
{
if
(rbCodeBook.Checked)
{
if
(bgCodeBookModel
!=
null
)
{
bgCodeBookModel.Dispose();
bgCodeBookModel
=
null
;
}
bgCodeBookModel
=
new
BGCodeBookModel
<
Bgr
>
();
}
else
if
(rbMog.Checked)
{
if
(fgDetector
!=
null
)
{
fgDetector.Dispose();
fgDetector
=
null
;
}
fgDetector
=
new
FGDetector
<
Bgr
>
(FORGROUND_DETECTOR_TYPE.FGD);
}
else
if
(rbFgd.Checked)
{
if
(fgDetector
!=
null
)
{
fgDetector.Dispose();
fgDetector
=
null
;
}
fgDetector
=
new
FGDetector
<
Bgr
>
(FORGROUND_DETECTOR_TYPE.MOG);
}
else
if
(rbFrameDiff.Checked)
{
if
(bgModelFrameDiff
!=
null
)
{
bgModelFrameDiff.Dispose();
bgModelFrameDiff
=
null
;
}
bgModelFrameDiff
=
new
BackgroundStatModelFrameDiff
<
Bgr
>
();
}
else
if
(rbAccAvg.Checked)
{
if
(bgModelAccAvg
!=
null
)
{
bgModelAccAvg.Dispose();
bgModelAccAvg
=
null
;
}
bgModelAccAvg
=
new
BackgroundStatModelAccAvg
<
Bgr
>
();
}
else
if
(rbRunningAvg.Checked)
{
if
(bgModelRunningAvg
!=
null
)
{
bgModelRunningAvg.Dispose();
bgModelRunningAvg
=
null
;
}
bgModelRunningAvg
=
new
BackgroundStatModelRunningAvg
<
Bgr
>
();
}
else
if
(rbSquareAcc.Checked)
{
if
(bgModelSquareAcc
!=
null
)
{
bgModelSquareAcc.Dispose();
bgModelSquareAcc
=
null
;
}
bgModelSquareAcc
=
new
BackgroundStatModelSquareAcc
<
Bgr
>
();
}
else
if
(rbMultiplyAcc.Checked)
{
if
(bgModelMultiplyAcc
!=
null
)
{
bgModelMultiplyAcc.Dispose();
bgModelMultiplyAcc
=
null
;
}
bgModelMultiplyAcc
=
new
BackgroundStatModelMultiplyAcc
<
Bgr
>
();
}
backgroundModelFrameCount
=
0
;
isBackgroundModeling
=
true
;
btnStartBackgroundModel.Enabled
=
false
;
btnStopBackgroundModel.Enabled
=
true
;
btnStartForegroundDetect.Enabled
=
false
;
btnStopForegroundDetect.Enabled
=
false
;
}
//
停止背景建模
private
void
btnStopBackgroundModel_Click(
object
sender, EventArgs e)
{
StopBackgroundModel();
}
//
停止背景建模
private
void
StopBackgroundModel()
{
lock
(lockObject)
{
isBackgroundModeling
=
false
;
}
btnStartBackgroundModel.Enabled
=
true
;
btnStopBackgroundModel.Enabled
=
false
;
btnStartForegroundDetect.Enabled
=
true
;
btnStopForegroundDetect.Enabled
=
false
;
}
//
开始前景检测
private
void
btnStartForegroundDetect_Click(
object
sender, EventArgs e)
{
isForegroundDetecting
=
true
;
btnStartBackgroundModel.Enabled
=
false
;
btnStopBackgroundModel.Enabled
=
false
;
btnStartForegroundDetect.Enabled
=
false
;
btnStopForegroundDetect.Enabled
=
true
;
}
//
停止前景检测
private
void
btnStopForegroundDetect_Click(
object
sender, EventArgs e)
{
lock
(lockObject)
{
isForegroundDetecting
=
false
;
}
btnStartBackgroundModel.Enabled
=
true
;
btnStopBackgroundModel.Enabled
=
false
;
btnStartForegroundDetect.Enabled
=
true
;
btnStopForegroundDetect.Enabled
=
false
;
}
}
//
前景检测方法枚举
public
enum
ForegroundDetectType
{
FrameDiff,
AccAvg,
RunningAvg,
MultiplyAcc,
SquareAcc,
CodeBook,
Mog,
Fgd
}
//
设置参数
public
struct
SettingParam
{
public
ForegroundDetectType ForegroundDetectType;
public
int
MaxBackgroundModelFrameCount;
public
double
Threshold;
public
SettingParam(ForegroundDetectType foregroundDetectType,
int
maxBackgroundModelFrameCount,
double
threshold)
{
ForegroundDetectType
=
foregroundDetectType;
MaxBackgroundModelFrameCount
=
maxBackgroundModelFrameCount;
Threshold
=
threshold;
}
}
}
另外,细心的读者发现我忘记贴OpenCvInvoke类的实现代码了,这里补上。多谢指正。
OpenCvInvoke实现代码
using
System;
using
System.Collections.Generic;
using
System.Linq;
using
System.Text;
using
System.Drawing;
using
System.Runtime.InteropServices;
using
Emgu.CV.Structure;
using
Emgu.CV.CvEnum;
namespace
ImageProcessLearn
{
///
<summary>
///
声明一些没有包含在EmguCv中的OpenCv函数
///
</summary>
public
static
class
OpenCvInvoke
{
//
自适应动态背景检测
[DllImport(
"
cvaux200.dll
"
)]
public
static
extern
void
cvChangeDetection(IntPtr prev_frame, IntPtr curr_frame, IntPtr change_mask);
//
均值漂移分割
[DllImport(
"
cv200.dll
"
)]
public
static
extern
void
cvPyrMeanShiftFiltering(IntPtr src, IntPtr dst,
double
spatialRadius,
double
colorRadius,
int
max_level, MCvTermCriteria termcrit);
//
开始查找轮廓
[DllImport(
"
cv200.dll
"
)]
public
static
extern
IntPtr cvStartFindContours(IntPtr image, IntPtr storage,
int
header_size, RETR_TYPE mode, CHAIN_APPROX_METHOD method, Point offset);
//
查找下一个轮廓
[DllImport(
"
cv200.dll
"
)]
public
static
extern
IntPtr cvFindNextContour(IntPtr scanner);
//
用新轮廓替换scanner指向的当前轮廓
[DllImport(
"
cv200.dll
"
)]
public
static
extern
void
cvSubstituteContour(IntPtr scanner, IntPtr new_contour);
//
结束轮廓查找
[DllImport(
"
cv200.dll
"
)]
public
static
extern
IntPtr cvEndFindContour(
ref
IntPtr scanner);
}
}
后记
值得注意的是,本文提到的OpenCv函数目前属于CvAux系列,以后也许会加入到正式的图像处理Cv系列,也许以后会消失。最重要的是它们还没有正式的文档。
其实关于背景模型的方法还有很多,比如《Video-object segmentation using multi-sprite background subtraction》可以在摄像机运动的情况下建立背景,《Nonparametric background generation》利用mean-shift算法处理动态的背景模型,如果我的时间和能力允许,也许会去尝试实现它们。另外,《Wallflower: Principles and practice of background maintenance》比较了各种背景建模方式的差异,我希望能够尝试翻译出来。
感谢您耐心看完本文,希望对您有所帮助。
背景建模与前景检测之二(Background Generation And Foreground Detection Phase 2)
作者:王先荣
本文尝试对《学习OpenCV》中推荐的论文《Nonparametric Background Generation》进行翻译。由于我的英文水平很差,断断续续搞了好几天才勉强完成,里面肯定会有诸多错误,欢迎大家指正,并请多多包涵。翻译本文的目的在于学习研究,如果需要用于商业目的,请与原文作者联系。
非参数背景生成
刘亚洲,姚鸿勋,高文,陈熙霖,赵德斌
哈尔滨工业大学
中国科学院计算所
摘要
本文介绍了一种新颖的背景生成方法,该方法基于非参数背景模型,可用于背景减除。我们介绍一种新的名为影响因素描述(effect components description ECD)的模型,用于描述背景的变动;在此基础上,我们可以用潜在分布的局部极值推导出最可靠背景状态(most reliable background mode MRBM)。该方法的基本计算过程采用Mean Shift这一经典的模式识别过程。Mean Shift通过迭代计算,能够在数据的密度分布中找到最近位置的点(译者注:即找到数据最密集的点)。这种方法有三个优点:(1)能从包含混乱运动对象的视频中提取出背景;(2)背景非常清晰;(3)对噪声和小幅度的(摄像机)振动具有鲁棒性。广泛的实验结果证明了上述优点。
关键词:背景减除,背景生成,Mean Shift,影响因素描述,最可靠背景状态,视频监视
1 引言
在许多计算机视觉和视频分析应用中,运动对象的分割是一项基本任务。例如,视频监视,多媒体索引,人物检测和跟踪,有知觉的人机接口,“小精灵”视频编码。精确的对象分割能极大的提高对象跟踪,识别,分类和动态分析的性能。识别运动对象的通用方法有:光流,基于时间差异或背景减除的方法。其中,背景减除最常用。背景模型被计算出,并逐帧进化;然后通过比较当前帧和背景模型间的差异来检测运动对象。这种方法的关键之处在于建立并维持背景模型。尽管文献【1-4】提出了很多有前途的方法,但是运动对象检测的精度这一基本问题仍然难以解决。第一个问题是:背景模型必须尽可能精确的反映真实背景,这样系统才能精确的检测运动对象的外形。第二个问题是:背景模型必须对背景场景的改变足够灵敏,例如对象开始运动及停止运动。如果不能适当的解决上述问题,背景减除会检测出虚假对象,它们通常被称为“幽灵”。
目前已经有了许多用于背景减除的背景建立和维持方法。按背景建模的步骤来分类,我们可以将其分为参数化的和非参数化的方法。参数化的背景建模方法通常假设:单个像素的潜在概率密度函数是高斯或者高斯混合函数,详情请参看文献【5-7】。Stauffer和Grimson在文献【8】中提出了一种自适应的背景减除方法,用于解决运动分割问题。在他们的工作成果中,他们为每个像素建立了高斯混合概率密度函数,然后用即时的近似值更新该模型。文献【9,10】提出了对高斯混合模型的一些改进方法。Toyama等人在文献【2】中提出了一种三层的Wallflower方案,该方案尝试解决背景维持中现存的许多问题,例如灯光打开关闭,前景孔穴等等。Haritaoglu等人在文献【1】中提出的W4方法,该方法为背景建模而对每个像素保留了三个值的方法,包括最大值(M),最小值(N)和最大帧间绝对差值(D)。Kim等人在文献【11】中,将背景值量化到编码本,编码本描述了长视频中背景模型的压缩形式。
另一类经常用到的背景模型方法基于非参数化的技术,例如文献【3,12-16】。Elgammal等人在文献【3】中,通过核密度估计建立了一种非参数化的背景模型。对每个像素,为了估计潜在的概率密度函数而保留了观测强度值,而新强度值的概率能通过该函数计算得出。这种模型具有鲁棒性,能够适应混乱及不完全静止但包含小扰动场合下的背景,例如摆动的树枝和灌木。
与参数化的背景模型方法相比,非参数化的背景模型方法具有以下优点:不需要指定潜在的模型,不需要明确的估计参数【14】。因此,它们能适应任意未知的数据分布。这个特性使非参数化的方法成为许多计算机视觉应用的有力工具。在许多计算机视觉应用中,许多问题牵涉到多元多种形式的密度,数据在特征空间中没有规则的形态,没有遵循标准的参数形式。但是,从时间和空间复杂度这一方面来看,非参数化的方法不如参数化的方法有效。参数化的方法产生简洁的密度描述(例如高斯或高斯混合),得出有效的估计状态。相对的,非参数化的方法在学习阶段几乎不需要计算,然而在评估阶段需要高密度的计算。因此,非参数化方法的主要缺陷是它们的计算量。不过一些革新的工作成果已经被提出,它们能加快非参数化方法的评估速度,例如文献【13】中的快速高斯变换(FGT),文献【17】中的新ball tree算法,核密度估计和K近邻(KNN)分类。
本文专注于非参数化的方法,跟Elagammal在文献【3】中提出的方法有紧密的联系,但是有两点本质上的区别。从基本原理上看,我们用影响因素描述(ECD)来为背景的变化建模,最可靠背景模型(MRBM)对背景场景的估计具有鲁棒性。从计算过程来看,通过使用Mean Shift过程,我们避免了对每个新观测强度值计算概率的核密度估计过程,节约了处理时间。在我们的方法中,仅用帧差即可决定像素的属性。因此能提高背景减除的鲁棒性和效率。
本文余下的部分按以下方式来组织:第二节中提出了影响因素描述,用于反映背景的变化;第三节详细解释了最可靠背景模型;第四节包含了实验结果;第五节讨论了有待扩充的部分。
2 影响因素描述
本节讨论影响因素描述(ECD),我们试图通过它来有效的模拟背景的变化。
背景减除的关键因素在于怎样建立并维持好的背景模型。由于在不同的应用中,摄像机类型、捕获的环境和对象完全不同,背景模型需要足够的自适应能力来适应不同的情况。为了有效的为背景建模,我们从最简单的理想情况开始。在理想情况下,对于视频中的每个空间位置,沿时间轴的强度值为常量C;常量C表示固定摄像机摄录了固定的场景(没有运动对象和系统噪声)。我们将这种情况下的场景称为理想背景场景。但是在实际应用中,很少能遇到这种理想情况。因此,背景像素可以看成是理想背景场景和其他影响部分的组合体。我们将这种方法定义为背景的影响成分描述,包括以下方面:
系统噪声 N-sys:它由图像传感器和其他硬件设备引起。如果环境不太严密,系统噪声不会从根本上影响常量C,仅仅引起适度的偏差。
运动的对象 M-obj:它由实际运动的对象及其阴影引起。大多数时候,它对C有极大的干扰。
运动的背景 M-bgd:它由运动的背景区域引起,例如户外场景中随风摆动的树枝,或者水中的波纹。
光照 S-illum:它表示户外随太阳位置改变而渐变的光照,或者室内灯光的关闭和打开而改变的照明。
摄像机位移 D-cam:它表示摄像机的小幅度位移而引起的像素强度变化。
场景的观测值(记为V-obsv)由理想背景场景C和有效成分组成,如公式(1)所示。
V-obsv = C + N-sys + M-obj + M-bgd + S-illum + D-cam (1)
在这里我们用符号+来表示影响因素的累积效果。
实际上,上述影响因素能进一步分为表1所示的不同属性。首先需要被强调的属性是过程,我们可以按过程将影响因素分为长期影响和短期影响。我们沿时间轴将视频流分成长度相等的块,如图1所示。长期表示影响因素会持续数块或者一直存在,例如N-sys、S-illum和D-cam。而M-obj和M-bgd仅仅偶尔发生,不会长期持续,因此我们称之为短期影响。

图1 将视频流分为等长的块
另一种分类的标准是偏差。我们把S-illum、D-cam、M-bgd看作时间不变的常驻偏差影响。在较长的过程中,这些影响可以看作是对理想背景值C 持久的增加(减少),或者替代。以S-illum为例,如果处于室内场景,并且打开照明,在接下来的帧中S-illum可以看成是对C持久的增加。而N- sys和M-obj在不同时刻有随机的值,我们称之为随时间变化的随机偏差影响。上述分析归纳到了表1中。
表1 影响因素的分类
长期 短期
常驻偏差 S-illum,D-cam M-bgd
随机偏差 N-sys M-obj
在此必须阐明以下两点:(1)上述分类并不绝对,取决于我们选择的块长度;但是它不影响我们接下来的分析;(2)也许某人会指出对S-illum的分类不正确,例如行驶汽车的灯光不是长期影响;这种情况下的光照变化属于短期影响,跟M-obj类似,因此我们不把它单独列为独立的影响因素。
由于S-illum和D-cam对理想背景C有长期持续的偏差,我们将它们合并到理想背景中,得到C' = C + S-illum + D-cam。对这种合并的直接解释是:如果光照发生变化或者摄像机变动位置,我们有理由假设理想背景已经改变。因此将公式(1)表示成:
V-obsv = C' + N-sys + M-obj + M-bgd (2)
到目前为止,观测值V-obsv由新的理想背景值C' 和影响因素(N-sys、M-obj、M-bgd)组成。这些影响因素对C'有不同的影响,归纳成以下两点:
N-sys在整个视频流中存在,并对C'有些许影响。因此,大部分观测值都不会偏离C'太远。
M-obj和M-bgd仅仅偶尔发生,但对C'引起很大的偏差。因此,仅仅小部分观测值显著的不同于C'。
得出以下结论:空间位置的像素值在大部分时间内保持稳定并伴随些许偏差(由于长期存在的随机偏差N-sys);仅仅当运动对象通过该像素时引起显著的偏差(由于短期偏差M-obj和M-bgd)。因此一段时间内,少数显著偏差形成了极值。大部分时间都存在这种属性,不过有时也并非如此。在图2中显示了白色圆心处像素值随时间而变化的图表。图2(a)~(c)节选自一段长达360帧的视频,图2(d)描绘了像素强度的变化。从图2(d)我们可以看出:由系统噪声引起的小幅度偏差占据了大部分时间,仅当有运动对象(及其阴影)经过时引起了显著的偏差。这与影响因素描述是相符的。

图2 显示ECD效果的例子
我们的任务是从观测值序列{V-obsv t}(t=1....T,T指时间长度)中找到理想背景C'的估计值C'^。通过上述分析,我们发现C'^位于多数观测值的中点。从另一方面来看,C'^ 处于潜在分布梯度为0和最密集的地方。这个任务可由Mean Shift过程来完成。我们将C'^称为最可靠背景状态。
3 用于运动对象检测的最可靠背景状态
基于第二节所讲的影响因素描述,我们推知:大部分观测值所处区域的中心是背景的理想估计。我们将这个估计用符号C'^表示,并称为最可靠背景状态(MRBM)。定位MRBM的基本计算方式是Mean Shift。一方面,通过使用MRBM,我们能够为混乱运动对象的视频生成非常清晰的背景图像。另一方面,Mean Shift过程能发现强度分布的一些局部极值,这种信息能从真实的运动对象中区别出运动的背景(例如户外随风摆动的树枝,或者水中的波纹)。
3.1 用于MRBM的Mean Shift
Mean Shift是定位密度极值的简明方式,密度极值处的梯度为0.该理论由Fukunaga在文献【18】中提出,而Mean Shift的平滑性和收敛性由Comaniciu和Meer在文献【19】中证实。近几年它已成为计算机视觉应用的有力工具,并报道了许多有前途的成果。例如基于Mean Shift的图像分割【19-21】和跟踪【22-26】。
在我们的工作成果中,我们用Mean Shift来定位强度分布的极值(注意:可能有多个局部极值)。我们将最大密度状态定义为MRBM。算法的要点如图3所示,包括下列步骤:
样本选择:我们为每个像素选择一组样本S = {xi},i=1,...,n,其中xis是像素沿时间轴的强度值,n是样本数目。我们直接对样本进行Mean Shift运算,以便定位密度的极值。
典型点选择:为了减少计算量,我们从S中选择或者计算出一组典型点(典型点数目为m,m<<n),并将这组典型点记为P = {pi},i=1,...,m。P中的典型点可以是样本的抽样结果,也可以是原始样本点的局部平均值。在我们的实验中,我们选择局部平均值。
Mean Shift过程:从P中的典型样本点开始运用Mean Shift过程,我们可以得到收敛点m。值得注意的是,Mean Shift计算仍然基于整个样本点集S。所以,梯度密度估计的精度并未因为使用典型点而降低。
提取候选背景模型:由于一些收敛点非常接近甚至完全一样,这些收敛点m可以被聚集为q组(q≤m)。我们能够获取q带权重的聚集中心,C = {{ci,wi}},i=1,....,q,其中ci是每个聚集中心的强度值,wi是聚集中心的权重。每组的点数记为li, i=1,....,q,∑i=1qli=m。每组中心的权重定义为:wi = li / m, i=1,....,q。
获取最可靠背景模型:C'^ = ci*,其中i* = argi max{wi},C'^是第二节提到的最可靠背景模型。

图3 MRBM算法的要点
对于每个m典型点,第三步中的Mean Shift实现过程依照以下步骤:
(1)初始化Mean Shift过程的起点:y1=pi。
(2)反复运用Mean Shift过程yt+1 = ....直至收敛。(这里我们选用跟文献【19】一样的Mean Shift过程,函数g(x)是核函数G(x)。)
(3)保存收敛点yconv,用于后续分析。
在对所有像素运用上述步骤之后,我们能用MRBM生成背景场景B。通过上述分析,我们发现背景生成过程的时间复杂度为O(N·m),空间复杂度为O(N·n),其中N是视频的长度。
3.2 运动对象检测与背景模型维持
生成背景模型之后,我们可以将其用于检测场景中的运动区域。为了使我们的背景模型对运动背景具有鲁棒性(例如户外随风摆动的树枝,或者水中的波纹),我们将k个聚集中心选为可能的背景值。我们将这组集合定义为Cb = {{ci,wi} | wi ≥ θ},i=1,....,k,其中Cb⊆C,θ是预定义的阀值。对于每个新的观测强度值x0,我们仅仅计算x0与Cb中元素的最小差值d,其中d = min{(x0-ci) | {ci,wi}∈Cb}。如果差值d大于预定义的阀值t,我们认为新的观测强度值是前景,否则为背景。
背景维持能让我们的背景模型适应长期的背景变化,例如新停泊的汽车或者逐渐改变的光照。当我们观察一个新像素值时,背景模型按下列步骤来更新:
(1)对每个新像素值,我们视其为新典型样本点。因此典型样本点的数目变为:m = m + 1。
(2)如果新像素值属于背景区域,假设其强度值与聚集中心{ci,wi}最近,我们将该中心的权重更新为:wi = (li + 1) / m。
(3)如果新像素值属于前景区域,我们从这点开始运用新的Mean Shift过程,这样可以获取到新的收敛中心{cnew,wnew},其中wnew初始化为:wnew = 1 / m。聚集中心C被扩充成:C = C ∪ {{cnew,wnew}}。
背景减除的时间复杂度是O(N),背景维持的时间复杂度是O(R),其中N是视频的帧数,R是运动对象的数目。
4 实验
我们专注于两类MRBM应用:背景生成和背景减除。我们在合成视频和标准PETS数据库上比较MRBM与其他常用的方法。源代码用C++实现,测试用电脑的配置如下:CPU为Pentium 1.6GHZ,内存512M。
我们自己捕获或者合成的视频尺寸为320×240像素,PETS数据库的视频尺寸为384/360×288像素,帧速率均为25fps。在所有的实验中,我们选择YUV(4:4:4)色彩空间作为特征空间。算法实现的描述见第三节,我们采用了Epanechnikov核,K(t) = 3 / 4 *(1 - t2) 。
理论上,更大的训练集能得到更稳定的背景模型,但是会牺牲适应性。我们的实验表明,当n=100时,能够使背景图像得到最佳的可视质量和适应性。典型点数 m影响训练时间及背景模型的可靠性。在我们的实验中,我们为Mean Shift过程选择m=10个典型点,这时的训练时间与高斯混合模型接近。阀值θ和t影响检测的精度,对不同的数据集可能有不同的θ和t。在我们的实验中当θ=0.3,t=10时,能够得到最大的准确率和最小的错误率。如果没有特别说明,所有实验使用上述设置。
4.1 背景生成
在许多监控和跟踪应用中,期望生成没有运动对象的背景图像,它能为更进一步的分析提供参考信息。但是很多时候,并不容易获得没有运动对象的的视频。我们的算法能从包含混乱运动对象的视频中提取非常清晰的背景图像。图4显示了一些生成的背景。视频共有360帧,我们将前100帧用于生成背景。图中显示了第 1,33,66,99帧图像。图4的底部显示了算法生成的背景。以图4(c)为例,这段视频摄自校园的上下课时间,每帧中都有10名步行的学生。观察图 4(c)最下面的背景图像,我们发现背景非常清晰,所有运动对象都被成功的抹去了。

图4 由MRBM生成的背景图像(每段视频显示了第1,33,66,99帧)
运动对象的移动速度是关键因素,它能显著的影响背景模型,包括我们的背景模型。我们用一段300帧的视频来评估算法,该视频里有一位缓慢走动的女士。第 1,30,60,90,120帧图像分别显示在图5(a)~(e)中。用不同数目的样本图像生成的背景显示于图5(f)~(j)。当保持100帧样本图像时,生成的背景中有一些噪点,但是背景的整体质量得以保证。噪点区域用白色椭圆标出了,如图5(f)所示。当我们将样本数目增加到300时,背景变得非常清晰,如图5(j)所示。

图5 由不同样本数(n=100,150,200,250,300)生成的背景图像(视频中有一位缓慢走动的女士,显示了视频中的第1,30,60,90,120帧图像)
我们也对我们的背景生成方法与其它基本方法做了比较,例如高斯模型具有多个聚集中心的高斯混合模型。为了区分比较结果,我们合成了一段多模态背景分布视频。背景的像素由高斯混合分布生成,pbg(x) = ∑i=12αiGμi,σi(x),其中参数α1=α2=0.5,σ1=σ2=6,μ1=128,μ2=240。前景对象的像素由高斯分布生成,pfg(x) = Gμ,σ(x),其中参数μ=10,σ=6。上述两式中,Gμ,σ(·)代表具有均值μ和标准偏差σ的高斯分布。背景像素及前景像素的强度分布见图6。

图6 视频中的背景像素强度分布(蓝色曲线)及前景像素强度分布(红色曲线)
视频共有120帧,我们用前100帧来生成背景。图7(a)~(e)显示了一些选定的帧,生成的背景图像显示在图7(f)~(i)中,从潜在分布生成的 “地面实况”样本显示于图7(j)中。 对于高斯模型,背景像素的强度值被选为高斯均值,生成的背景图像如图7(f)所示。对于高斯混合模型,我们选择带maxim的高斯混合均值为背景值。图 7(g)显示了2个中心的高斯混合模型,图7(h)显示了3个中心的高斯混合模型。实验所用的高斯混合模型使用OpenCV中的实现,见文献【27】。 MRBM方法得到的结果如图7(i)所示。

图7 由不同模型从合成视频中生成的背景图像。(a)~(e)中显示了第1,20,40,60,80帧图像。(f)~(i)显示了由高斯模型、2中心高斯混合模型、3中心 高斯混合模型及最可靠背景模型生成的背景图像。(j)显示了地面实况样本背景图像。
比较地面实况图像和生成的背景图像,我们发现非参数模型MRBM优于其它方法。凭直觉,在处理多模分布时,MRBM看起来与高斯混合模型类似。但是关键的不同之处在于高斯模型依赖均值和方差。它们的1阶和2阶统计数据对外部点(outliers 远离数据峰值的点)非常敏感。如果对象的运动速度慢,存在足够的前景值导致错误的均值,结果得出错误的背景值。作为对照,MRBM跟分布无关,仅仅使用极值作为可能的背景值,它对外部点更鲁棒。其他参数方法存在类似的问题,当预定义的模型不能描述数据分布时更加明显。
4.2 背景减除
图8显示了我们算法的背景减除结果。图8(a)显示观测到的当前帧,图8(b)显示用MRBM从100帧样本生成的背景图像,图8(c)显示了背景减除的结果图像,我们发现运动对象变得很突出。我们比较了MRBM和其它常用的基本方法,例如文献【1】中的最大最小值法,文献【28,29】中的中值法,文献【8,6】中的高斯混合模型。比较结果显示于图9。由于我们不能修改这些原始工作成果的实现方式,只能按以下方式来管理基础算法:(1)对于W4,我们按原始成果中的建议来设置参数;(2)对于中值法和高斯混合模型,我们调整参数使其达到最好的检测精度。另外,为了使比较尽量公平,我们只做背景减除,没有进行降噪和形态学处理。

图8 背景减除结果
最佳的视频序列选自PETS数据库【30-32】,选定帧如图9(a)所示。对所有的视频序列,我们用100帧来生成背景,用第40帧做背景减除。这些视频序列包含两种主要的场景:缓慢运动的对象(如PETS00和PETS06),多模态背景(如PETS01中摆动的树);这两种场景是背景减除中的不同情况。对于缓慢运动的对象,高斯模型的结果比较差,因为高斯均值对外部点敏感,如图9(d)所示。而MRBM依赖于背景分布的极值,外部点对其影响很小。同样,中值法和最大最小值法不能很好的应对多模态背景,PETS01中摆动的树被误认为前景。跟预期一致,MRBM优于其它三种方法。

图9 不同方法得到的背景减除结果。(a)标准PETS数据库,(b)最大最小值法,(c)中值法,(d)高斯混合模型,(e)最可靠背景模型
4.3 讨论可能的欠缺
尽管MRBM适用于许多应用,仍然存在一些不能应对的场合,图10就是不能应对的例子。在这个实验中,视频共有300帧,我们用前120帧来生成背景。图 10(a)~(g)分别显示了第1,20,40,60,80,100,120帧,背景图像显示在图10(h)中。前景人物的很大一部分被误认为背景。

图10 一个MRBM不能正确处理的例子。分别显示了第1,20,40,60,80,100,120帧图像。
通常,前景和背景的定义从自身来看并不明确。它包含在场景的语义中,在不同的应用中可能不一致。在我们的应用中,我们将运动对象定义为前景,将静止(或者几乎静止)的东西定义为背景,这与大多数视频监控应用的定义一致。通过第二节的分析,我们试图用ECD模型来近似观测值。在图10的实验中,人物在大部分时间保持静止,然后突然运动。这种情况下,大部分观测强度值属于人物,而非背景。对于人物的肩膀部分尤其明显,肩膀部分有相似的颜色,以致于检测不到运动。因此前景人物的大部分被误认为背景。
实际上,这个例子反映了背景模型的根本问题:稳定性与适应性。理论上,如果我们增加用于训练的背景帧数,我们能得到更清晰的背景图像。但是同时,会极大的牺牲背景模型的适应性。当背景改变(例如新停泊的汽车或者突然改变的光照),背景模型需要很长的时间才能适应新情况,将产生大量的错误。
针对该问题,一种有效的解决方案是:将现有的基于像素的方法扩展为基于区域或者基于帧的方法。通过分割图像或者完善像素级的低级分类可以实现它。更进一步,可以同时使用低级对象分割和高级信息(例如跟踪或者事件描述)。因此,我们接下来的工作将专注于如何结合空间和高级信息。
5 结论
本文主要有两点贡献:(1)我们介绍的影响因素描述可用于对变化的背景进行建模;(2)基于ECD,我们开发了一种鲁棒的背景生成方法——最可靠背景模型。应用MRBM,能从包含混乱运动对象的视频序列中生成高质量的背景图像。一些例子显示了这种方法的有效性和鲁棒性。
然而,仍然存在一些有待解决的问题。当前的工作中仅仅考虑了像素的时间信息。怎么结合空间信息来提高本方法的鲁棒性是后续工作的重点。一种直接的扩展是:将当前基于像素的方法修改成熔合了邻域信息基于区域的方法。另外,结合使用低级分割和高级跟踪信息,对我们的工作成果也将有极大的提高。
6 致谢
在此要感谢陈熙霖博士和山世光博士,他们跟作者进行了很有帮助的讨论。这项研究的经费由以下单位赞助:中国自然科学基金会、中国科学院百名人才培养计划、上海银晨智能识别科技有限公司。
背景建模与前景检测之三(Background Generation And Foreground Detection Phase 3)
作者:王先荣
在上一篇文章里,我尝试翻译了《Nonparametric Background Generation》,本文主要介绍以下内容:如何实现该论文的算法,如果利用该算法来进行背景建模及前景检测,最后谈谈我的一些体会。为了使描述更加简便,以下将该论文的算法及实现称为NBGModel。
1 使用示例
NBGModel在使用上非常的简便,您可以仿照下面的代码来使用它:
// 初始化NBGModel对象 NBGModel nbgModel = new NBGModel( 320 , 240 ); // 训练背景模型 nbgModel.TrainBackgroundModel(historyImages); // 前景检测 nbgModel.Update(currentFrame); // 利用结果 pbResult.Image = nbgModel.ForegroundMask.Bitmap; // 释放对象 nbgModel.Dispose();
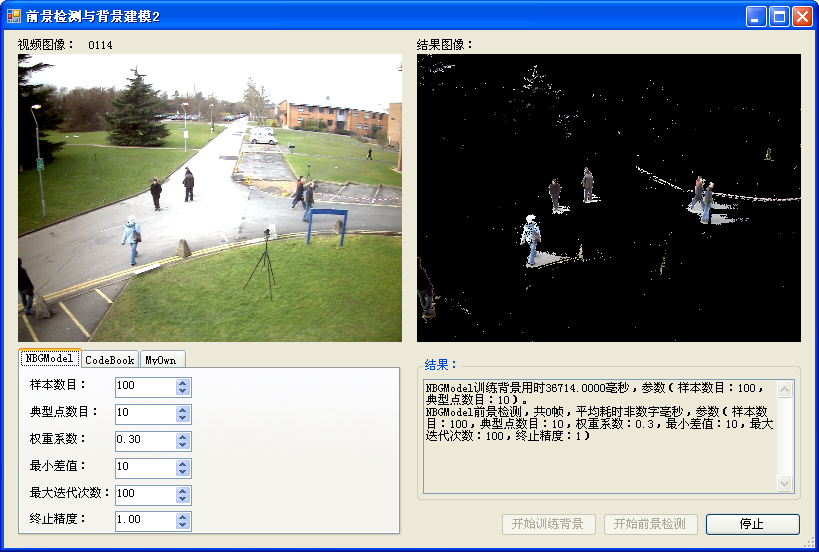
下面是更加完整的示例:
更加完整的示例
2 实现NBGModel
2.1 我在实现NBGModel的时候基本上跟论文中的方式一样,不过有以下两点区别:
(1)论文中的MeanShift计算使用了Epanechnikov核函数,我使用的是矩形窗形式的MeanShift计算。主要是因为我自己不会实现 MeanShift,只能利用OpenCV中提供的cvMeanShift函数。这样做也有一个好处——不再需要计算与保存典型点。
(2)论文中的方法在检测的过程中聚集中心会不断的增加,我模仿CodeBook的实现为其增加了一个清除消极聚集中心的ClearStable方法。这样可以在必要的时候将长期不活跃的聚集中心清除掉。
2.2 NBGModel中用到的数据成员如下所示:
private int width; //图像的宽度
private int height; //图像的高度
private NBGParameter param; //非参数背景模型的参数
private List<Image<Ycc, Byte>> historyImages = null; //历史图像:列表个数为param.n,在更新时如果个数大于等于param.n,删除最早的历史图像,加入最新的历史图像
//由于这里采用矩形窗口方式的MeanShift计算,因此不再需要分组图像的典型点。这跟论文不一样。
//private List<Image<Ycc,Byte>> convergenceImages = null; //收敛图像:列表个数为param.m,仅在背景训练时使用,训练结束即被清空,因此这里不再声明
private Image<Gray, Byte> sampleImage = null; //样本图像:保存历史图像中每个像素在Y通道的值,用于MeanShift计算
private List<ClusterCenter<Ycc>>[,] clusterCenters = null; //聚集中心数据:将收敛点分类之后得到的聚集中心,数组大小为:height x width,列表元素个数不定q(q<=m)。
private Image<Ycc, Byte> mrbm = null; //最可靠背景模型
private Image<Gray, Byte> backgroundMask = null; //背景掩码图像
private double frameCount = 0; //总帧数(不包括训练阶段的帧数n)
其中,NBGParameter结构包含以下成员:
public int n; //样本数目:需要被保留的历史图像数目
public int m; //典型点数目:历史图像需要被分为多少组
public double theta; //权重系数:权重大于该值的聚集中心为候选背景
public double t; //最小差值:观测值与候选背景的最小差值大于该值时,为前景;否则为背景
public MCvTermCriteria criteria; //Mean Shift计算的终止条件:包括最大迭代次数和终止计算的精度
聚集中心ClusterCenter使用类而不是结构,是为了方便更新,它包含以下成员:
public TColor ci; //聚集中心的像素值
public double wi; //聚集中心的权重
public double li; //聚集中心包含的收敛点数目
public double updateFrameNo; //更新该聚集中心时的帧数:用于清除消极的聚集中心
2.3 NBGModel中的关键流程
1.背景建模
(1)将训练用的样本图像添加到历史图像historyImages中;
(2)将历史图像分为m组,以每组所在位置的矩形窗为起点进行MeanShift计算,结果窗的中点为收敛中心,收敛中心的像素值为收敛值,将收敛值添加到收敛图像convergenceImages中;
(3)计算收敛图像的聚集中心:(a)得到收敛中心的最小值Cmin;(b)将[0,Cmin+t]区间中的收敛中心划分为一类;(c)计算已分类收敛中心的平均值,作为聚集中心的值;(d)删除已分类的收敛中心;(e)重复a~d,直到收敛中心全部归类;
(4)得到最可靠背景模型MRBM:在聚集中心中选取wi最大的值作为某个像素的最可靠背景。
2.前景检测
(1)用wi≥theta作为条件选择可能的背景组Cb;
(2)对每个观测值x0,计算x0与Cb的最小差值d;
(3)如果d>t,则该点为前景;否则为背景。
3.背景维持
(1)如果某点为背景,更新最近聚集中心的wi为(li+1)/m;
(2)如果某点为前景:(a)以该点所在的矩形窗为起点进行MeanShift计算,可得到新的收敛中心Cnew(wi=1/m);(b)将Cnew加入到聚集中心clusterCenters;
(3)在必要的时候,清理消极的聚集中心。
2.4 NBGModel的实现代码
值得注意的是:在实现代码中,有好几个以2结尾的私有方法,它们主要用于演示算法流程,实际上并未使用。为了优化性能而增加了不少指针操作之后的代码可读性变得很差。
NBGModel实现代码
3 NBGModel类介绍
3.1 属性
Width——获取图像的宽度
Height——获取图像的高度
Param——获取参数设置
Mrbm——获取最可靠背景模型图像
BackgroundMask——获取背景掩码图像
ForegroundMask——获取前景掩码图像
FrameCount——获取已被检测的帧数
3.2 构造函数
public NBGModel(int width, int height)——用默认的参数初始化NBGModel,等价于NBGModel(width, height, NBGParameter.GetDefaultNBGParameter())
public NBGModel(int width, int height, NBGParameter param)——用指定的参数初始化NBGModel
3.3 方法
AddHistoryImage——添加一幅或者一组历史图像
TrainBackgroundModel——训练背景模型;如果传入了历史图像,则先添加历史图像,然后再训练背景模型
Update——更新背景模型,同时检测前景
ClearStale——清除消极的聚集中心
Dispose——释放资源
4 体会
NBGModel的确非常有效,非常简洁,特别适用于伴随复杂运动对象的背景建模。我特意选取了PETS2009中的素材对其做了一些测试,结果也证明了 NBGModel的优越性。不过需要指出的是,它需要占用大量的内存(主要因为需要保存n幅历史图像);它的计算量比较大。
在使用的过程中,它始终需要在内存中缓存n幅历史图像,1幅最可靠背景模型图像,1幅背景掩码图像,近似m幅图像(聚集中心);而在训练阶段,更需要临时存储m幅收敛图像。
例如:样本数目为100,典型点数目为10,图像尺寸为768x576时,所用的内存接近300M,训练背景需要大约需要33秒,而对每幅图像进行前景检测大约需要600ms。虽然可以使用并行编程来提高性能,但是并不能从根本上解决问题。
(注:测试电脑的CPU为AMD闪龙3200+,内存1.5G。)
看来,有必要研究一种新的方法,目标是检测效果更好,内存占用低,处理更快速。目前的想法是使用《Wallflower: Principles and Practice of Background Manitenance》中的3层架构(时间轴上的像素级处理,像素间的区域处理,帧间处理),但是对每层架构都选用目前流行的处理方式,并对处理方式进行优化。时间轴上的像素级处理打算使用CodeBook方法,但是增加本文的一些思想。像素间的区域处理打算参考《基于区域相关的核函数背景建模算法》中的方法。帧间处理预计会采用全局灰度统计值作为依据。
最后,按照惯例:感谢您耐心看完本文,希望对您有所帮助。
本文所述方法及代码仅用于学习研究,不得用于商业目的。















 2225
2225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









