







Twitter-Snowflake算法产生的背景相当简单,为了满足Twitter每秒上万条消息的请求,每条消息都必须分配一条唯一的id,这些id还需要一些大致的顺序(方便客户端排序),并且在分布式系统中不同机器产生的id必须不同。
snowflake生成64的id,刚好使用long来保存,结构如下:
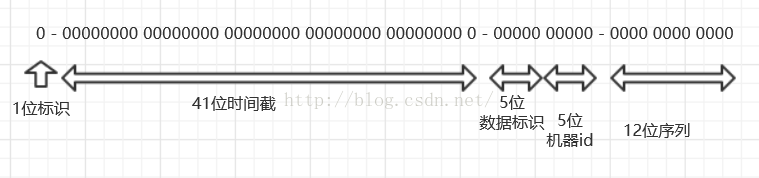
1位标识,由于long基本类型在java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0
41位时间截,注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69
10位的数据机器位,可以部署在1024个节点
12位序列,同一时间截,同一机器,可以生成4096个id
使用java实现:
public class IdWorker {
//开始该类生成ID的时间截
private final long startTime = 1463834116272L;
//机器id所占的位数
private long workerIdBits = 5L;
//数据标识id所占的位数
private long datacenterIdBits = 5L;
//支持的最大机器id
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
//支持的最大数据标识id
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
//序列在id中占的位数
private long sequenceBits = 12L;
//机器id向左移的位数
private long workerIdLeftShift = sequenceBits;
//数据标识id向左移的位数
private long datacenterIdLeftShift = workerIdBits + workerIdLeftShift;
//时间截向左移的位置
private long timestampLeftShift = datacenterIdBits + datacenterIdLeftShift;
//生成序列的掩码
private long sequenceMask = -1 ^ (-1 << sequenceBits);
private long workerId;
private long datacenterId;
//同一个时间截内生成的序列数,初始值是0,从0开始
private long sequence = 0L;
//上次生成id的时间截
private long lastTimestamp = -1L;
public IdWorker(long workerId, long datacenterId){
if(workerId < 0 || workerId > maxWorkerId){
throw new IllegalArgumentException(
String.format("workerId[%d] is less than 0 or greater than maxWorkerId[%d].", workerId, maxWorkerId));
}
if(datacenterId < 0 || datacenterId > maxDatacenterId){
throw new IllegalArgumentException(
String.format("datacenterId[%d] is less than 0 or greater than maxDatacenterId[%d].", datacenterId, maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
//生成id
public synchronized long nextId(){
long timestamp = timeGen();
if(timestamp < lastTimestamp){
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//表示是同一时间截内生成的id
if(timestamp == lastTimestamp){
sequence = (sequence + 1) & sequenceMask;
//说明当前时间生成的序列数已达到最大
if(sequence == 0){
//生成下一个毫秒级的序列
timestamp = tilNextMillis();
//序列从0开始
sequence = 0L;
}
}else{
//新的时间截,则序列从0开始
sequence = 0L;
}
lastTimestamp = timestamp;
return ((timestamp - startTime) << timestampLeftShift) //时间截部分
| (datacenterId << datacenterIdLeftShift) //数据标识id部分
| (workerId << workerIdLeftShift) //机器id部分
| sequence; //序列部分
}
protected long tilNextMillis(){
long timestamp = timeGen();
while(timestamp <= lastTimestamp){
timestamp = timeGen();
}
return timestamp;
}
protected long timeGen(){
return System.currentTimeMillis();
}
//测试
public static void main(String[] args){
IdWorker idWorker = new IdWorker(31, 31);
for(int i = 0; i < 1000; i++){
System.out.println(idWorker.nextId());
}
}
}转自
http://www.lanindex.com/twitter-snowflake%EF%BC%8C64%E4%BD%8D%E8%87%AA%E5%A2%9Eid%E7%AE%97%E6%B3%95%E8%AF%A6%E8%A7%A3/
http://www.devnote.cn/article/420.html















 1515
1515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









