







ChatScript是最近在搜对话系统资料的时候搜到的,貌似现在用得人并不多,能搜到的使用经验很少,不像AIML那样被大家熟知。
浅浅的了解了ChatScript(后面简称CS)之后,发现这个对话框架做得挺好的,于是决定用一用它。
CS对话框架的底层程序是由c语言实现的,而对话内容、对话逻辑的控制则通过脚本来完成。这样的话,开发新的bot时,可以只编写对话脚本,而不需要改动底层的代码。
CS支持多种欧洲语言,但最大的缺憾是,不支持中文,或许是中文的结构和句法也英文差异太大了,作者没有考虑它吧。但是,它支持UTF-8格式的词典和文本,是不是有关了一道门,却开了一扇窗的感觉。
好了,开始用它做一个简单的中文对话bot吧。
一. 下载
下载地址:https://github.com/bwilcox-1234/ChatScript,下载后解压后得到ChatScript文件夹。目前CS已经更新到7.4.2版本。
感谢何云超的博客提供的Chatscript的部分使用资料,一开始,这些资料给了我很大的帮助。并且何同学在github上开源了他的中文版多轮对话系统,在https://github.com/candlewill/Bots。
二. 加入中文分词器
由于中文不像英文一样,中文句子词语并没有严格分开,因此,需要将中文分词器添加到CS里面,并在主调程序中加入分词接口调用。
跟着何同学的做法,下载结巴分词c++版本。下载解压后将cppjieba文件夹,如果想先试用一下结巴分词,看看效果的话,可以跟着README做如下操作:

结果如下图,
执行build里面的demo即可。Cppjieba的核心程序都在include中的.hpp文件中,其他有用程序在deps里面。
实际在CS里面是用jieba,并不需要先make jieba,将cppjie整个文件放入ChatScript文件夹中即可。后续整个系统一起make。
CS的源程序在SRC目录下:
CS预制的bot是Harry。整个系统的主调程序为mainSystem.cpp。mainSystem各程序间的调用关系如下:
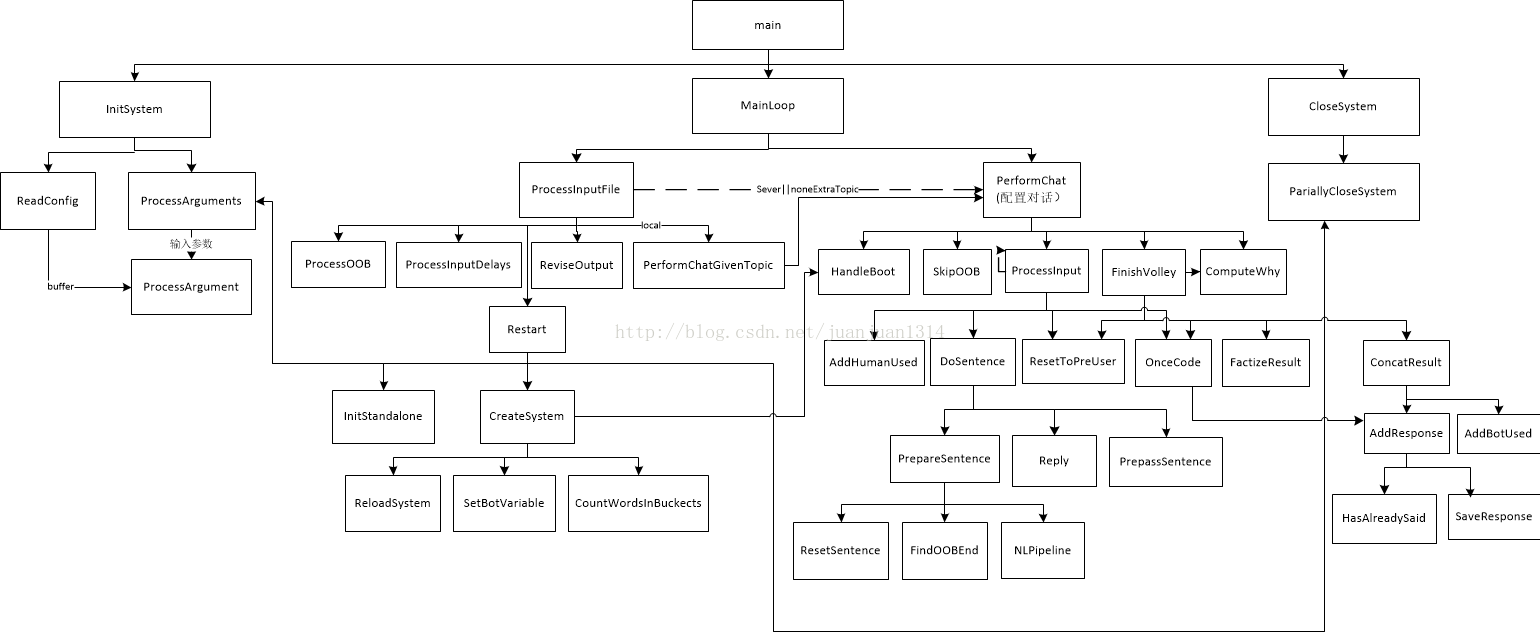
中文分词的调用函数就加在manSystem.cpp中。分词调用函数CutWords()可仿照cppjieba/test/demo.cpp来写。当然,得先将cppjieba/include/Jieba.hpp include到mainSystem.cpp中。
对话过程由mainSystem中的PerformChat()函数完成。因此,CutWords()在performChat中被调用。
以上完成后,接下来开始修改SRC/Makefile文件。打开文件,添加黄色部分:

至此,分词所有的修改完成。
三. 加入中文词典
将jieba分词的词典(cppjieba/dict/jieba.dict.utf8)加入到CS的词典中。CS缺省的语言是ENGLIS,在入门阶段,我们暂时不直接添加一门语言(这样做还是比较复杂的,后面再弄吧),而是,直接把中文词典添加到ENGLISH文件夹中。由于底层程序读词典时,只读0.txt-9.txt,以及a.txt-z.txt,所以,中文词只能粘贴到其中一个文件中。
本笨妞觉得CS的词典很好的地方是除了词性外,还给词语标了很详细的标签,同时,非人名、地名的词还标注了意思,这样,后续做语义理解应该会有帮助(个人觉得)。
由于中文词语的词性和英文词性差异较大,且7.4.2版本CS读词性时要读一级词性和二级词性,本笨妞采用了何同学介绍的办法,将所有词的词性标注为(NOUN NOUN_NUMBER)(当然,这并不是长久之计哦,只是为了跑通程序,暂时应付的。)如图,将中文词加入0.txt中:
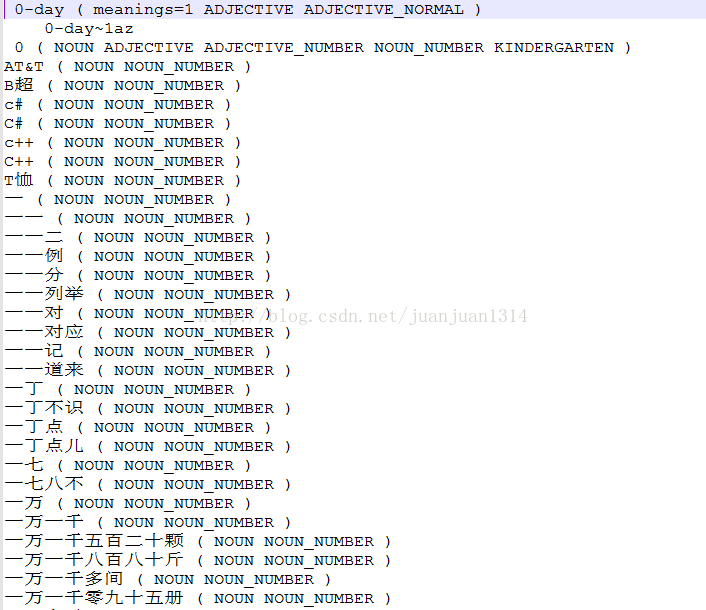
CS初始化系统加载词典的机制是如果存在dict.bin文件,则直接加载dict.bin文件,反之,如果该文件不存在,则读0.txt-9.txt、a.txt-z.txt文件,生成dict.bin。因此,我们添加了中文词之后,要把原来的dict.bin删除,不然,中文词语没有办法被加载到词典中。
做完以上修改后,在src目录下执行makesever命令,完成编译,编译完成后ChatScript/BINARIES文件夹下多了一个可执行文件ChatScript。此时,执行ChatScript,你将和机器人Harry对话。你可以输入中文,但是,他只能回答英文。要做一个回答中文的对话机器人,要修改对话脚本和控制脚本。
四. 修改和添加脚本
Bot加载的脚本文件在RAWDATA中,脚本的make文件BINARIES目录下的Makefile。
不想用Harry,于是,在RAWDATA下创建自己的文件夹,笨妞给机器人取名为“猫咪”,于是,创建MAOMI目录,并将HARRY文件夹下的simplecontrol.top复制到MAOMI目录下,simplecontrol.top是对话控制脚本,在它下面,可以设定对话的粗粒度规则,如bot的名字,调用话题的规则,以及当bot找不到话题时的回答等。
从HARRY拷贝过来的simplecontorl.top需要修改bot名、显示的名字、调用的话题,以及cs_token变量的赋值。
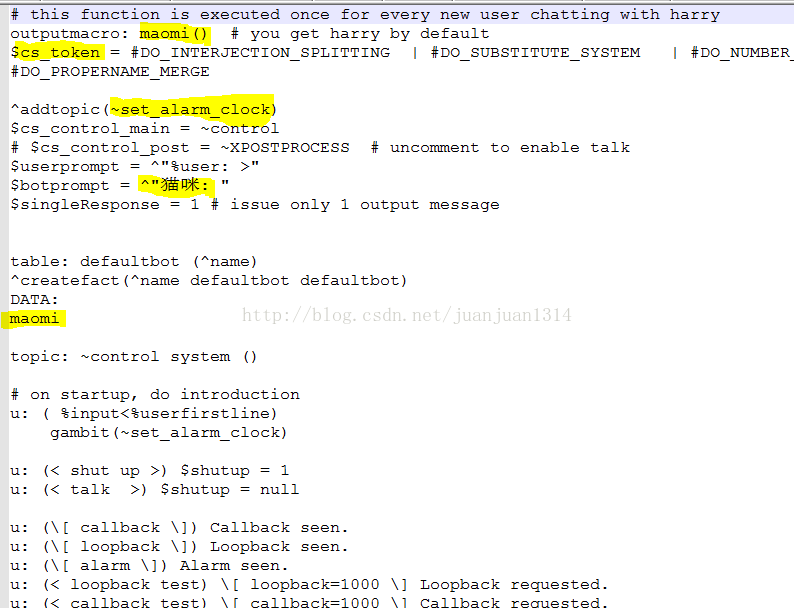
上图黄色部分需要做修改。其中,cs_token定义了底层程序的部分功能(个人这么觉得),由于对话是中文的,按照Harry定义的cs_token,在运行时会报错,因此,下图黄色部分必须删掉。

DO_SPELLCHECK定义了拼写检验,中文会被检验成错误拼写,因此,得删掉;中文的语法和英文不同,DO_PARSE也最好删除。另外,前面添加中文词典时,二级词性定为NOUN_NUMBER,因此,不能做NUMBER_MERGE。
CS对话对话的话题依赖于.top文件,脚本操作基本上也是topic操作。你给Bot添加什么样的topic,bot就跟着topic做相应的理解和回答。添加的topic制定了对话细粒度规则。
如MAOMI下面添加了两个topic,如图
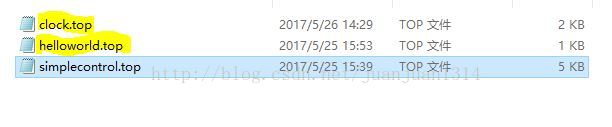
Helloworld.top是欢迎话题,只用到了匹配。clock.top是一个闹钟话题,可以帮助用户设置闹钟,clock.top用变量正则匹配并保存用户说的关键信息,达到多轮对话的效果。
Helloworld.top的内容如图:

Helloworld是topic名,必须唯一,以保证正确的进入话题,topic名前面必须添加“~”符号,猫咪和话题关键词,用“()”。
Topic内容的定义规则入下:
?:MEAT (you like meat) I do
“?:”是Kind;“MEAT”是label;()内是pattern;“I do”是response。
Helloworld.top里面,定义了嵌套对话。其中,u:是一级kind,a:是二级。当用户说的句子中包含“猫咪”这个词时,bot选择~helloworld这个topic,并匹配到(猫咪)这个规则,于是回答“您好,主人。有什么可以帮助您的吗”,如果用户说没有,bot回答“好吧”,如果用户说“有”,bot回答“请讲”,如果用户回答别的,bot会去匹配别的话题。
编写topic的具体资料在https://github.com/bwilcox-1234/ChatScript/blob/master/WIKI/ChatScript-Basic-User-Manual.md
Clock根据多轮对话的规则,将topic分成了三部分:NLU、policy、NLG三部分,clock.top涉及到变量,变量是个很重要,也比较大的话题,在下一篇会介绍。
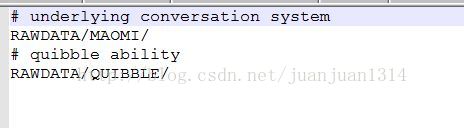
Topic编辑好后,在RAWDATA目录下添加filesmaomi.txt,这个文件定义了运行bot maomi需要的脚本文件的路径,内容如图:
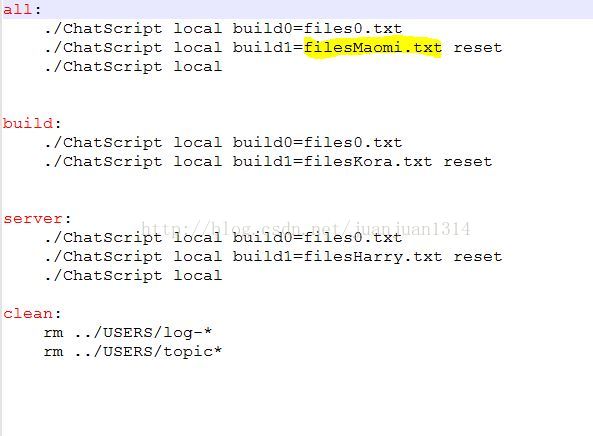
然后,修改BINARIES目录下的Makefile,如下:
接下来在BINARIES目录下执行make all命令即可加载maomi。猫咪的效果如图:
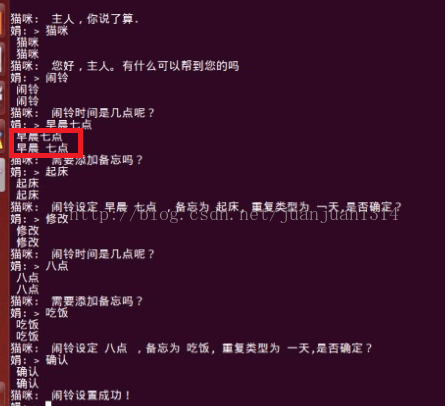
(红色部分是打印的分词器的输入和输出)
五. ChatScript的官方文档














 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









