







 本文探讨了GPU在视频转码中的应用,包括基于CPU和GPU的转码方案,如CUDA和OpenCL。分析了CPU与GPU在计算任务上的优缺点,并在三网融合背景下研究了自适应编码技术,特别是H.264/SVC编码。同时,指出了GPU在视频编解码中的挑战,如运动估计和补偿的并行计算。
本文探讨了GPU在视频转码中的应用,包括基于CPU和GPU的转码方案,如CUDA和OpenCL。分析了CPU与GPU在计算任务上的优缺点,并在三网融合背景下研究了自适应编码技术,特别是H.264/SVC编码。同时,指出了GPU在视频编解码中的挑战,如运动估计和补偿的并行计算。
GPU在视频转码中的应用研究进展
已有的视频转码软件
目前,市场上已经出现了几款优秀的利用GPU进行辅助视频转码的软件,典型的代表包括nVidia的Badaboom,AMD的ATIAvivo,Cyberlink的MediaShow和免费软件MediaCoder。其中,前三者均为商业软件,只有MediaCoder是免费软件。MediaCoder在2008年仍是基于GPL协议的开源软件,后来作者封闭了源代码,不再开源,但仍可以获得免费版本。
网上已有这几款软件的评测文章,比如网易09年的这篇文章。此文的结论简言之,便是nVidia的Badaboom充分发挥了GPU的性能,将计算任务最大地交给GPU来做;而MediaCoder则将部分计算任务放到GPU中,CPU的负载也很重,更容易使CPU和GPU同时满负载。
基于CPU的视频转码方案—以ffmpeg为例
-
识别文件格式,打开视频文件容器,得到video_stream
-
使用解码器(如libavcodec)把video_stream解码成原始的frame数据
-
利用编码器将frame数据编码成指定格式(如H.264)
-
存放到指定格式的容器中(如mp4或者mkv)
过程1的速度很快,没有必要使用GPU更改,可以使用已有的代码。
过程2和过程3需要对每一帧进行编解码处理,计算量大,计算任务可并行的程度高,因此可以使用GPU进行优化。
过程4与过程1类似。
基于GPU的并行计算技术的选择,CUDAvs OpenCL
目前,GPGPU的编程框架主要有两种,一种是nVidia公司推出的CUDA(ComputeUnified DeviceArchitecture,统一计算架构),目前只能在nVidia公司的显卡中使用;另一种是由非盈利性技术组织KhronosGroup掌管的OpenCL。OpenCL最初由苹果公司提交,后来获得了包括nVidia和AMD在内的工业界领袖的支持,正式成为国际标准。OpenCL不仅可以在nVidia公司的显卡中使用,还可以在AMD(ATI)的显卡中使用,是一种可以在异构GPU平台中使用的技术选择。
CUDA
CUDA目前最新的版本是4.0,已经发展了多年,技术上比较成熟。CUDA是一个技术框架,同时提供OpenCL和CUDAC语言的编译器。虽然也有人编写了针对Java或者Python等语言的包装器(Wrapper),但目前使用最多的并且最稳定的是使用CUDAC语言来进行GPU编程。
CUDAC语言是通过对C语言进行扩展实现的。在CUDA的架构下,一个程序分为两个部份:host端和device端。Host端是指在CPU上执行的部份,而device端则是在显示芯片上执行的部份。CUDAC与ANSIC最大的不同之处就是在device端中运行的C程序里加入了一些关键字,从而使得这些程序可以由CUDAC编译器,生成PTX码。
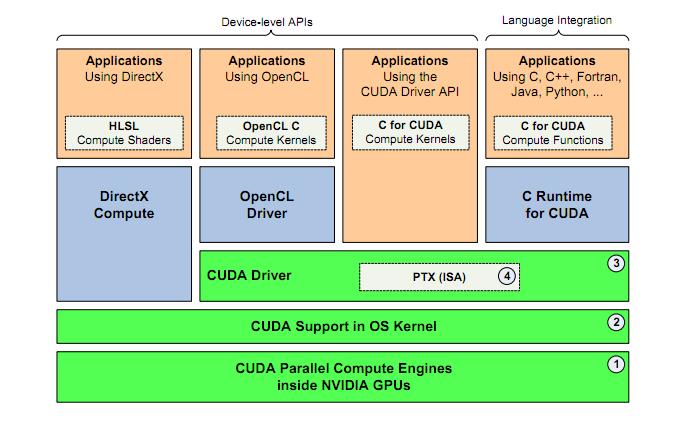
OpenCL
OpenCL目前最新的版本是1.1,由于OpenCL是一个国际标准,因此其更新升级不如CUDA快。为了能在异构的硬件环境中使用,OpenCL的封装层次较低,高层次的抽象Brook本质上是基于上一代GPU的,缺乏良好的编程模型。
对于面向nVidia的GPU编程,短期看CUDA C无疑是最好的选择,不仅因为CUDAC的发展快,技术较为成熟,更重要的是CUDAC编程有丰富的资料和论坛支持,从而更容易上手和解决问题。但对于一个长期项目,在未来的硬件平台不能确定的情况下,使用OpenCL的效果会更好一些。
CPU和GPU计算的优缺点分析
CPU和GPU都是具有运算能力的芯片,CPU更像“通才”——指令运算(执行)为重+数值运算,GPU更像“专才”——图形类数值计算为核心。在不同类型的运算方面的速度也就决定了它们的能力——“擅长和不擅长”。芯片的速度主要取决于三个方面:微架构,主频和IPC(每个时钟周期执行的指令数)。
-
微架构
CPU微架构的设计是面向指令执行高效率而设计的,因而CPU是计算机中设计最复杂的芯片。和GPU相比,CPU核心的重复设计部分不多,这种复杂性不能仅以晶体管的多寡来衡量,这种复杂性来自于实现:如程序分支预测,推测执行,多重嵌套分支执行,并行执行时候的指令相关性和数据相关性,多核协同处理时候的数据一致性等等复杂逻辑。
GPU其实是由硬件实现的一组图形函数的集合,这些函数主要用于绘制各种图形所需要的运算。这些和像素,光影处理,3D坐标变换等相关的运算由GPU硬件加速来实现。图形运算的特点是大量同类型数据的密集运算——如图形数据的矩阵运算,GPU的微架构就是面向适合于矩阵类型的数值计算而设计的,大量重复设计的计算单元,这类计算可以分成众多独立的数值计算——大量数值运算的线程,而且数据之间没有像程序执行的那种逻辑关联性。
因此从微架构上看,CPU擅长的是像操作系统、系统软件和通用应用程序这类拥有复杂指令调度、循环、分支、逻辑判断以及执行等的程序任务。它的并行优势是程序执行层面的,程序逻辑的复杂度也限定了程序执行的指令并行性,上百个并行程序执行的线程基本看不到。GPU擅长的是图形类的或者是非图形类的高度并行数值计算,GPU可以容纳上千个没有逻辑关系的数值计算线程,它的优势是无逻辑关系数据的并行计算。
-
主频
GPU执行每个数值计算的速度并没有比CPU快,从目前主流CPU和GPU的主频就可以看出了,CPU的主频都超过了2GHz,甚至3GHz,而GPU的主频最高还不到2GHz,主流的也就1GHz。所以GPU在执行少量线程的数值计算时速度并不能超过CPU。
目前GPU数值计算的优势主要是浮点运算,它执行浮点运算快是靠大量并行,但是这种数值运算的并行性在面对程序的逻辑执行时毫无用处。
-
IPC(每个时钟周期执行的指令数)
这个方面,CPU和GPU无法比较,因为GPU大多数指令都是面向数值计算的,少量的控制指令也无法被操作系统和软件直接使用。如果比较数据指令的IPC,GPU显然要高过CPU,因为并行的原因。但是,如果比较控制指令的IPC,自然是CPU的要高的多。原因很简单,CPU着重的是指令执行的并行性。
另外,目前有些GPU也能够支持比较复杂的控制指令,比如条件转移、分支、循环和子程序调用等,但是GPU程序控制这方面的增加,和支持操作系统所需要的能力CPU相比还是天壤之别,而且指令执行的效率也无法和CPU相提并论。
总结一下:
CPU更适合处理逻辑控制密集的计算任务,而GPU适合处理数据密集的计算任务。并且由于现代CPU的发展,使得CPU与计算机主存的交换速度要远远大于GPU与计算机主存的交换速度,因此GPU更适合处理SIMD(SingleInstruction MultiData,单数据多指令)的运算,即将数据放到显存中进行多次计算的计算任务。
目前比较流行CPU+GPU的协同计算模型,在这个模型中,CPU与CPU协同工作,各司其职。CPU负责进行逻辑性强的事物处理和串行计算,GPU则专注于执行高度线程化的并行处理任务。CPU、GPU各自拥有相互独立的存储器地址空间:主机端的内存和设备端的显存。
三网融合下自适应编码技术的研究
在三网融合业务发展中,信息服务将覆盖文字、语音
数据、图像、视频等多种媒体信息综合服务形式,同时用户使用的终端也将呈现多样化。为了达到用户体验的一致,又能适合各种不同终端处理、不同网络传输的目标,需要多种自适应、自适配的机制和技术,而自适应编码技术就是解决关键的视频数据信息处理和传输的方法和环节之一。
自适应编码技术
H.264/SVC(可扩展视频编码)在进行视频信号编码时,将图像压缩信号的输出分成多个不同的层。当网络条件较差、带宽不足时,网络和终端只对基本层的码流数据进行传输和编码;而当带宽条件改善,则可以进一步传输和解码增强层的码流,提高视频图像质量。
SVC于2007年7月成为H.264标准的一部分。当前大部分的研究和试验都是基于
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 457
457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









