









该系列仅在原课程基础上部分知识点添加个人学习笔记,或相关推导补充等。如有错误,还请批评指教。在学习了 Andrew Ng 课程的基础上,为了更方便的查阅复习,将其整理成文字。因本人一直在学习英语,所以该系列以英文为主,同时也建议读者以英文为主,中文辅助,以便后期进阶时,为学习相关领域的学术论文做铺垫。- ZJ
转载请注明作者和出处:ZJ 微信公众号-「SelfImprovementLab」
知乎:https://zhuanlan.zhihu.com/c_147249273
CSDN:http://blog.csdn.net/JUNJUN_ZHAO/article/details/78953208
2.18 (选修)logistic 损失函数的解释
Explanation of logistic Regression cost function
(字幕来源:网易云课堂)

In an earlier video, I’ve written down a form for the cost function for logistic al regression.In this optional video, I want to give you a quick justification for why we like to use that cost function for logistic regression.To quickly recap, in logistic regression,we have that the prediction y hat is sigmoid of w transpose x + b,where sigmoid is this familiar function.And we said that we want to interpret y hat as the p( y = 1 | x).So we want our algorithm to output y hat as the chance that y = 1 for a given set of input features x.So another way to say this is that if y is equal to 1 then the chance of y given x is equal to y hat.And conversely if y is equal to 0 then the chance that y was 0 was 1- y hat, right?
在前面的视频中 我已经写出了,
logistic
回归的成本函数的表达式,在这节选修视频中 我将给出一个简洁的证明,来说明
logistic
回归成本函数的表达式为什么是这种形式,回想一下 在
logistic
回归中,需要预测的结果
y^
可以表示为
sigmoid(wT∗x+b)
,
sigmoid
是我们熟悉的函数,我们约定
y^
=p(y = 1 | x),
y^=p(y=1|x)
即算法的输出
y^
,是给定训练样本
x
条件下

So if y hat was a chance, that y = 1,then 1-y hat is the chance that y = 0.So, let me take these last two equations and just copy them to the next slide.So what I’m going to do is take these two equations which basically define p(y|x) for the two cases of y = 0 or y = 1.And then take these two equations and summarize them into a single equation.And just to point out y has to be either 0 or 1 because when binary cost equations,so y = 0 or 1 are the only two possible cases, all right.When someone take these two equations and summarize them as follows.Let me just write out what it looks like,then we’ll explain why it looks like that.So (1 – y hat) to the power of (1 – y).So it turns out this one line summarizes the two equations on top.
因此
y^
表示的是
y=1
的概率,那么
1−y^
就是
y=0
的概率,接下来 我们把这两个式子,复制放到下一张幻灯片,对于这两个式子,
y=0
和
y=1
条件下 定义了
P(y|x)
,我们可以将这两个公式 合并成一个公式,需要指出的是 我们讨论的是,二分分类问题的成本函数,因此
y
的取值只能是 0 或者 1,上述的两个条件概率公式 可以合并成下面这样,接下来 我会解释为什么,可以合并成 这种形式的表达式,即

Let me explain why.So in the first case, suppose y = 1, right?So if y = 1 then this term ends up being y hat,because that’s y hat to the power of 1.This term ends up being 1- y hat to the power of 1- 1, so that’s the power of 0.But, anything to the power of 0 is equal to 1, so that goes away.And so, this equation, just as P(y|x) = y hat, when y = 1.So that’s exactly what we wanted.Now how about the second case, what if y = 0?If y = 0, then this equation above is P(y|x) = y hat to the 0,but anything to the power of 0 is equal to 1, so that’s just equal to 1 times 1- y hat to the power of 1- y.So 1- y is 1- 0, so this is just 1.And so this is equal to 1 times (1- y hat) = 1- y hat.And so here we have that the y = 0, P(y|x) = 1- y hat,which is exactly what we wanted above.
我来解释一下,第一种情况 假设 y=1 ,由于 y=1 那么这一项结果就是 y^ ,因为 y^ 的1次方 等于 y^ ,而这一项就等于 (1−y^)(1−1) 所以是 ^0,由于任何数的 0 次方都是 1 那个项就消失了,所以这个方程 当 y=1 时 P(y|x)=y^ ,这就是我们要的,第二种情况 当 y=0 时 P(y|x) 等于多少呢?假设 y=0 那么上面这个式子 P(y|x) = y^ ^0,任何数的0次方都等于 1,所以这就等于 1∗(1−y^)(1−y) ,前面假设 y=0 因此 1−y 就等于 1,所以 P(y|x) 就等于 1∗(1−y^)=1−y^ ,因此在这里当 y=0 时 P(y|x) =1- y^ ,这正好是上面这里的式子。
So what we’ve just shown is that this equation is a correct definition for p(ylx).Now, finally because the log function is a strictly monotonically increasing function,you’re maximizing log( P(y|x) ) give you similar result that is optimizing P(y|x) and if you compute log of P(y|x) , that’s equal to log of y hat r of y 1- y at sub par of 1- y.And so that simplifies to y log y hat + 1-y times log 1- y hat, right?And so this is actually negative of the loss function that we had to find previously.And there’s a negative sign there because usually if you’re training a learning algorithm,you want to make probabilities large whereas in logistic regression we’re expressing this. We want to minimize the loss function.So minimizing the loss corresponds to maximizing the log of the probability.
因此 刚才的推导表明这个式子,就是 P(y|x) 的正确定义,由于 log 函数是,严格单调递增的函数,最大化 log(P(y|x) ) 等价于,最大化 P(y|x) 计算 log(p(y|x)) ,就等于 log((y^)y∗(1−y^)(1−y)) ,可以化简成 ylogy^+(1−y)∗log(1−y^) ,而这就是我们前面提到的成本函数的负值,前面有一个负号的原因是,当你训练学习算法时,希望算法输出值的概率是最大的,然而在 logistic 回归中 我们需要最小化损失函数,因此最小化损失函数就是最大化 log(p(y|x)) 。
So this is what the loss function on a single example looks like.How about the cost function,the overall cost function on the entire training set on m examples?So, the probability of all the labels In the training set.Let’s figure that out.Writing this a little bit informally.If you assume that the training examples I’ve drawn independently or drawn IID,identically independently distributed,then the probability of the example is the product of probabilities.The product from i = 1 through m p(y(i) ) given x(i).And so if you want to carry out maximum likelihood estimation, right,then you want to maximize the, find the parameters that maximizes the chance of your observations in the training set.But maximizing this is the same as maximizing the log,so we just put logs on both sides.So log of the probability of the labels in the training set is equal to,log of a product is the sum of the log.
因此这就是 单个训练样本的损失函数表达式,那么成本函数呢?,m 个训练样本的总体成本函数如何表示?,让我们一起来探讨一下,整个训练集中标签的概率,更正式地来写一下,假设所有的训练样本,服从同一分布且相互独立,也即 独立同分布的,所有这些样本的联合概率 就是每个样本概率的乘积,从 1 到 m的 p(y(i)|x(i)) 的概率乘积,如果你想做最大似然估计,需要寻找一组参数 使得,给定样本的观测值概率最大,但令这个概率最大化 等价于令其对数最大化,在等式两边取对数,训练集的标签出现概率的对数等于..,对乘积求对数 就等于对数之和。
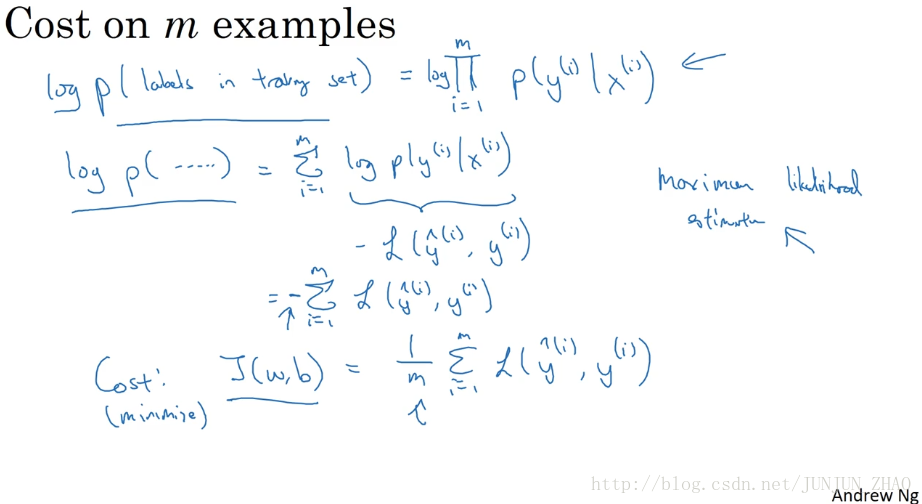
So that’s sum from i=1 through m of log p(y(i)) given x(i).And we have previously figured out on the previous slidethat this is negative L of y hat i, y i.And so in statistics, there’s a principlecalled the principle of maximum likelihood estimation,which just means to choose the parameters that maximizes this thing.Or in other words, that maximizes this thing.Negative sum from i = 1 through m L(y hat i ,yi)and just move the negative sign outside the summation.So this justifies the cost we had for logistic regression which is J(w,b) of this.And because we now want to minimize the cost instead of maximizing likelihood,we’ve got to rid of the minus sign.And then finally for convenience,we make sure that our quantities are better scale,we just add a 1 over m extra scaling factor there.
也即从1到m对 log(p(y(i)|x(i))) 求和,在前面视频中我们讲过,这就等于 −L((y^)i,y(i)) ,在统计学里面 有一个方法,叫做最大似然估计,即 求出一组参数 使这个式子取最大值,也就是说 使得这个式子取最大值,负 1 乘以从 1到 m 对 L((y^)i,y(i)) 求和,可以将负号移到求和符号的外面,这样我们就推导出了前面给出的 logistic 回归的 成本函数 J(w,b) ,由于训练模型时 目标是让成本函数最小化,所以我们不是直接用最大似然概率,要去掉这里的负号,最后为了方便,可以对成本函数进行适当的缩放,我们就在前面加一个额外的常数因子 (1/m) 。
But so to summarize, by minimizing this cost function J(w,b) ,we’re really carrying out maximum likelihood estimation with the logistic regression model.Under the assumption that our training examples were IID,or identically independently distributed.So thank you for watching this video, even though this is optional.I hope this gives you a sense of why we use the cost function we do for logistic regression.And with that, I hope you go on to the exercises,the pre exercise and the quiz questions of this week.And best of luck with both the quizzes, and the following exercise.
总结一下 为了最小化成本函数 J(w,b) ,最大似然估计的角度出发,我们从 logistic 回归模型的,假设训练集中的样本都是独立同分布的条件下,独立同分布的条件下的,尽管这节课是选修性质的 但还是感谢观看本节视频,我希望通过本节课,你可以明白为什么我们的 logistic 回归的成本函数是那种形式,掌握了这个之后 希望你能继续完成课程的练习,以及本周的测验,祝你做小测时顺顺利利。
重点总结:
logistic regression 代价函数的解释:
Cost function的由来:
预测输出y^的表达式:
y^=σ(wTx+b)
其中,
σ(z)=11+e−z
y^可以看作预测输出为正类(+1)的概率:
y^=P(y=1|x)
当 y=1 时, P(y|x)=y^ ;当 y=0 时, P(y|x)=1−y^ 。
将两种情况整合到一个式子中,可得:
P(y|x)=y^y(1−y^)(1−y)
对上式进行 log 处理(这里是因为 log 函数是单调函数,不会改变原函数的单调性):
logP(y|x)=log[y^y(1−y^)(1−y)]=ylogy^+(1−y)log(1−y^)
概率 P(y|x) 越大越好,即判断正确的概率越大越好。这里对上式加上负号,则转化成了单个样本的 Loss function,我们期望其值越小越好:
L(y^,y)=−(ylogy^+(1−y)log(1−y^))
对于 m 个训练样本来说,假设样本之间是独立同分布的,我们总是希望训练样本判断正确的概率越大越好,则有:
max∏i=1mP(y(i)|x(i))
同样引入 log 函数,加负号,则可以得到 Cost function:
J(w,b)=1m∑mi=1L(y^(i),y(i))=−1m∑mi=1[y(i)logy^(i)+(1−y(i))log(1−y^(i))]
参考文献:
[1]. 大树先生.吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-2)– 神经网络基础
PS: 欢迎扫码关注公众号:「SelfImprovementLab」!专注「深度学习」,「机器学习」,「人工智能」。以及 「早起」,「阅读」,「运动」,「英语 」「其他」不定期建群 打卡互助活动。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









