







作者: 大树先生
博客: http://blog.csdn.net/koala_tree
GitHub:https://github.com/KoalaTree
2017 年 09 月 20 日
以下为在Coursera上吴恩达老师的DeepLearning.ai课程项目中,第一部分《神经网络和深度学习》第二周课程部分关键点的笔记。笔记并不包含全部小视频课程的记录,如需学习笔记中舍弃的内容请至Coursera 或者 网易云课堂。同时在阅读以下笔记之前,强烈建议先学习吴恩达老师的视频课程。
同时我在知乎上开设了关于机器学习深度学习的专栏收录下面的笔记,方便在移动端的学习。欢迎关注我的知乎:大树先生。一起学习一起进步呀!^_^
神经网络和深度学习—神经网络基础
1. 二分类问题
对于二分类问题,大牛给出了一个小的Notation。
- 样本: (x,y) ,训练样本包含 m 个;
- 其中
x∈Rnx ,表示样本 x 包含nx 个特征; - y∈0,1 ,目标值属于0、1分类;
- 训练数据: { (x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m))}
输入神经网络时样本数据的形状:
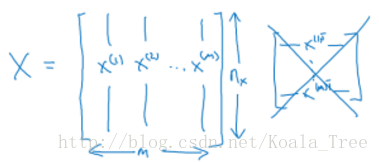
X.shape=(nx,m)
目标数据的形状:
Y=[y(1),y(2),⋯,y(m)]
Y.shape=(1,m)
2. logistic Regression
逻辑回归中,预测值:
其表示为1的概率,取值范围在 [0,1] 之间。
引入Sigmoid函数,预测值:
注意点:函数的一阶导数可以用其自身表示,
这里可以解释梯度消失的问题,当 z=0 时,导数最大,但是导数最大为 σ′(0)=σ(0)(1−σ(0))=0.5(1−0.5)=0.25 ,这里导数仅为原函数值的0.25倍。
参数梯度下降公式的不断更新, σ′(z) 会变得越来越小,每次迭代参数更新的步伐越来越小,最终接近于0,产生梯度消失的现象。
3. logistic回归 损失函数
Loss function
一般经验来说,使用平方错误(squared error)来衡量Loss Function:
但是,对于logistic regression 来说,一般不适用平方错误来作为Loss Function,这是因为上面的平方错误损失函数一般是非凸函数(non-convex),其在使用低度下降算法的时候,容易得到局部最优解,而不是全局最优解。因此要选择凸函数。
逻辑回归的Loss Function:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









