







机器学习的思想
序
提到机器学习,圈内人首先想到的是神经网络、SVM、梯度下降、逻辑回归等具体的算法,而对圈外人而言,机器学习就等同于机器人、无人驾驶等具体的应用场景。
看了不少机器学习相关的文章,有描述知识点的:讲解算法非常详细,并且给出实现的程序demo。也有描述覆盖面的:泛泛而谈机器学习的典型应用场景,力图使大众易于理解。
但在一个软件工程中,机器学习如何应用,各算法如何衔接,怎么系统地去解决问题,也即怎么把机器学习的一个个知识点连成线,扩展成面,解决实际的一大片问题,鲜有提及。
这一系列的文章力图从软件工程师的视角出发,描述机器学习是什么,各种算法处于一个什么样的位置,指引如何构建一个算法框架,去系统性地用机器学习解决实际的问题。
机器学习的概念
关于机器学习的定义,以下这段英文被广泛的引用:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E
http://www.csdn.net/article/2015-09-08/2825647 给出的翻译如下:
“对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么我们称这个计算机程序在从经验E学习。”
这段话非常正确并且普适,但没有实践过的人绝逼看不懂。
平易近人的机器学习
通常我们所看到的介绍机器学习的文章,举例子时,都是必须要机器学习才能解决的例子,如手写数字识别、人脸检测、欺诈分析、商品推荐等等。它们虽然确实是机器学习的典型应用范例,但容易 让读者将机器学习的应用场景想窄了。
这里举一些有其他解决方案,但也可以用机器学习的例子:
数学
解反函数
如下函数:
y=x3+7x
求其反函数(不考虑复数解)。
解决方案:
一元三次方程的解法是卡尔丹公式。
http://baike.baidu.com/link?url=3vlaDPYokr9bYtH1NTmcujC3lp7MAbLy19e8YJnYmC6tuXARgZ9KIhVfQjaJk2EbQ1NXS_zKFi350x4zk68muK
经过一番推导之后,得出反函数为:
x=y2+y24+7333‾‾‾‾‾‾‾‾√‾‾‾‾‾‾‾‾‾‾‾‾‾‾√3+y2−y24+7333‾‾‾‾‾‾‾‾√‾‾‾‾‾‾‾‾‾‾‾‾‾‾√3
一种机器学习的方案:
解此方程的任务就是T
1.采样计算,创造样本数据
在
x∈[−50,50]
的区间内,以0.1的间隔采一次样,按
y=x3+7x
计算出y的值。
这组数据便是上面所提到的经验E。
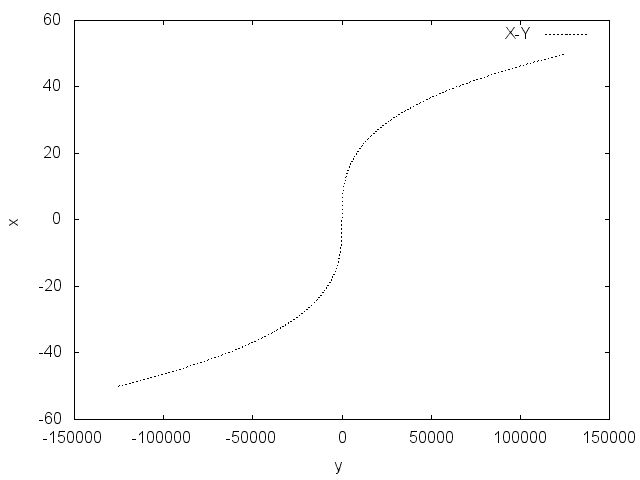
2.根据这组数据值,使用机器学习算法反推
x=f(y)
:
(1)分划这组数据为测试集
α
和训练集
β
(随机抽出100个做个测试用)。
(2)设定评价函数为
∑x,y∈α|y−g′(x)|
,其中g’为机器学习算法在
α
上训练出的函数。这个公式就是P
为得到g’,可以用遗传规划(Genetic-Programming),也可以分段做线性回归,还可以用BP神经网络。
3.当采样密度提高/采样区间扩大时,相应的数据量增多,机器学习出来的效果也将更好。
摇一摇
很多应用都有摇一摇的功能,即摇一下手机,触发某种功能,它的实现是基于手机的加速度传感器数据,如此文所示:
http://blog.csdn.net/xn4545945/article/details/9001097
这篇文章用了一个阈值去判断是否触发摇一摇状态,这个阈值是所谓的经验值,怎么得来的呢:
1.设一个初始阈值 V。
2.对手头上Android手机测试,看是否能正常触发摇一摇,是否过于灵敏。
3.过于灵敏V往上调,难以触发V往下调。
4.最终调节好阈值V。
让我们换一种方法实现:
1.对每台手机,收集两组加速度传感器的数据:
(1)缓慢移动手机,采集加速度传感器在x,y,z三轴方向的数据,这组数据全部保留,作为负样本。
(2)各个方向摇动手机,采集数据,这组数据过滤掉加速度的绝对值较小的50%,作为正样本。
具体采集数据时,可以在应用中打log,然后写个脚本提取日志文件。
2.这样,我们得到了一个数据集(E),基于此,使用C4.5决策树算法,建一个决策树。目标函数设为准确率(P)。
3.在App中,使用该决策树去判断是否触发即可。
当然,需要更准确的话,可以把加速度当一个时间序列,用时间序列预测的方式去分析,不过上面这种方案已经够用了。
睡眠状态检测
有些音乐播放软件会有一个“睡觉时自动关闭”的功能。这个是通过定时检测睡眠状态而实现的。
判定为睡眠的条件如下:
1.夜间(即时间为12:00-5:00)
2.非唤醒状态(即用户不在操作手机)
3.手机不在动
前两个条件非常明确,写代码上if-else就行了,第三个就不那么容易了。简单来做,可以用加速度变化值小于一个阈值,作为手机不动的判断条件,但这样做不太准。
基于机器学习的解决方案和上面一例是类似的,分别在手机静止和运动时收集加速度传感器三方向数据,有所不同的是要建一个时间序列模型。
出行信息
比如华为P8可以智能识别出出行类的短信,并添加提醒。
http://mobile.zol.com.cn/519/5192018.html
以火车出行的提醒为例,一种实现方案如下:
1.使用一组正则表达式去匹配短信,全部匹配存在,则判断它是一条火车出行的提醒短信。如果不是,直接跳过。
2.采用另一组正则表达式,提取短信中的时间/地点/始终站。
3.根据上面提取出来的信息,生成一个闹钟。
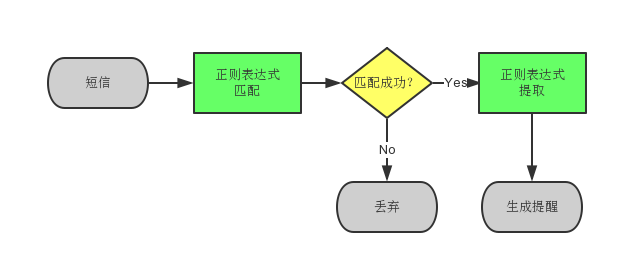
上面的这些正则表达式是程序员去看短信样本,慢慢试出来的。
这个实现方案并不怎么好,下面做一下小许改进:
在第一步中,由于不同类型的车票提醒短信模板不太一样,不一定能找到这样一组正则表达式。需要考虑优化一下判断的方案。
新的方案如下:
1.收集一批火车出行的提醒短信样本和另一批普通的短信样本,打上正负标志。
2.观察正负样本,取一组正则表达式,这些表达式应当尽量不均衡地匹配两类样本(正样本匹配中的多,则负样本匹配中的少,反之亦然)。
3.生成数据集,每条样本,对每个正则表达式,匹配为1,不匹配为0,形成一个向量,所有样本生成的向量合起来就是一个数据矩阵。
4.用SVM算法训练,得到一个SVM模型。
5.套用该模型去预测,用以解决是和否的问题。
上面所举的这些例子,机器学习并不是惟一的解法,有些例子中只是解决方案中的一环。但从机器学习的解法与其他解法的对比中,才能更好地理解机器学习的思想是什么,和我们传统的解决问题的方法有什么不同。
机器学习的思想与其局限
我们传统的解决问题方法,是针对问题发现规律,然后根据规律设计解决方案。在发现规律的过程中,我们不断地尝试,总结一些经验公式。

而机器学习,就是将发现规律这一步移交给计算机,为了能让计算机去发现规律,我们需要给计算机提供经验E和评价准则P。
因此,用机器学习解决问题,就是根据问题,先设计解决问题的评价标准,基于此采集足够的参考样本,然后,使用学习算法得出解决问题的方案,最后,使用该方案去解决问题。
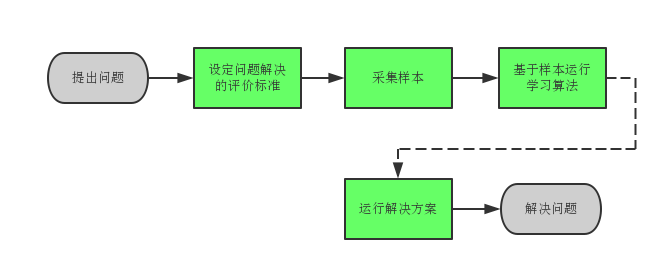
得到解决方案的过程是机器学习的训练过程,而应用解决方案的过程就是预测过程。
值得注意的是,训练过程是模拟人的思维,去探索解决方案,它可以是离线并且不限设备进行的,类似于代码的编译。而预测过程则类似于代码的执行,需要应用到具体的平台设备,考虑稳定/性能等因素。
机器学习适用于规律不容易得到或常变,而样本容易采集的情景,如果本身就是简单或有成熟解法的问题,使用机器学习没有什么优势。















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









