







必备知识:
什么是哈希表?
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希表hashtable(key,value) 的做法其实很简单,就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位
以上即为哈希表的基础知识。需要指出的是,当数据量过大时,很容易发生碰撞问题,即不同的字符串生成的哈希值,对数据长度取模后得到同样的数组下标。此时必须要进行碰撞处理。
常规的碰撞处理方式有两种,第一种是开放定址法,第二种是拉链寻址法。点击查看详细处理过程。
两种方式均有利弊,简单的说:
- 开放定址法需要找到合适的寻址探测方案,但是不管是线性递增方式还是随机数方式,很容易产生堆积现象,从而导致插入和查询性能下降。
- 拉链寻址法则较为简单,但是当碰撞较多时,需要动态申请额外较多的内存块来构建链表。
本方案结合以上两种方式的特点,分三步建立完成一个哈希表,具体过程如下图所示:
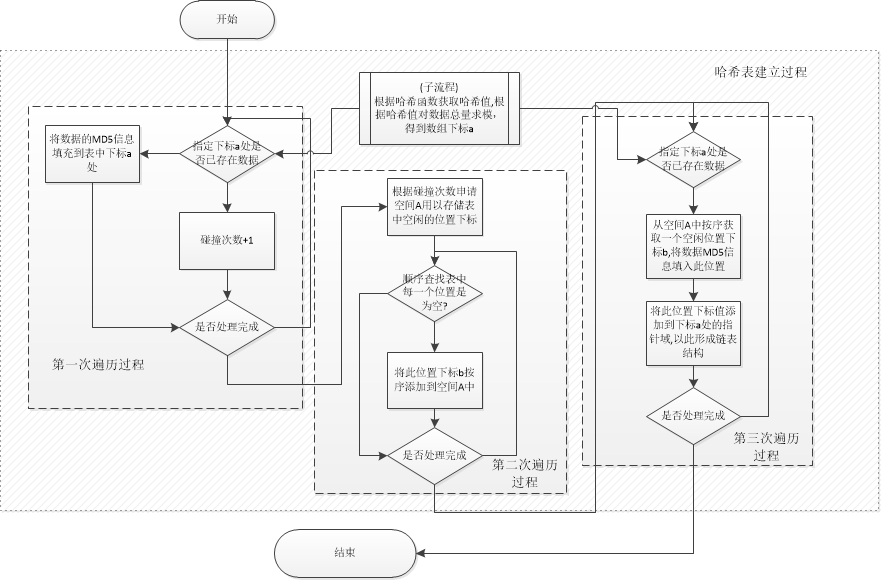
简要说明:
- 第一步:由哈希函数生成的哈希值与总存储量进行求模,所得结果A即为该数据在哈希表中的位置。如果该位置为空,则将该数据的MD5值填入此处,但是由于数据碰撞,不同数据的哈希值可能会得到相同的A值,此时仅将碰撞次数加1,直至循环结束。
- 第二步:根据第一步得到的碰撞次数,申请同等长度的缓存空间Buffer。在第二次循环中,按序循环,依次检查每一处是否为空,如果为空,将此位置下标B记录到缓存空间Buffer中,直至循环结束。
- 进行第三次循环,如果A处已存在数据,则从Buffer中按序摘取一个下标B,将该数据的MD5值与原始文件下标值填入此处,然后再将下标B插入到A处信息的指针域,以此形成链表结构。
示例伪代码如下:
int iHitCnt = 0;//碰撞次数
for(UINT jj = 0;jj < 3;jj++)
{
for(UINT ii = 0;ii< nTotal;ii++)
{
if (jj == 1)
{
if(strlen(mp_HashPtr[ii].chMD5) == 0)
{
if (pp >= iHitCnt)
{//哈希表公共溢出区空间不足
delete []pFreeOffSet;
delete []mp_HashPtr;
return FALSE;
}
pFreeOffSet[pp++] = ii;
}
}
else
{
HashA = HashStringA(/*传入字符串*/);
pMD5 = MD5(/*传入字符串*/);
iHashPos = HashA % nTotal;//哈希值A做下标
//填充到哈希表中
if (strlen(mp_HashPtr[iHashPos].chMD5) != 0)
{
if (jj == 0)
{//第一次循环仅统计发生碰撞的次数
iHitCnt++;
}
else
{
if (pp >= iHitCnt)
{//超出公共溢出区长度
delete []mp_HashPtr;
delete []pFreeOffSet;
return FALSE;
}
PHASHSTRUCT pNewHashSt = mp_HashPtr + pFreeOffSet[pp];//从公共溢出区摘一个空白的区域,并将其加入到链表中
memcpy(pNewHashSt->chMD5,pMD5,MD5_LENGTH);
pNewHashSt->NextOffset = mp_HashPtr[iHashPos].NextOffset;
mp_HashPtr[iHashPos].NextOffset = pFreeOffSet[pp];
pp++;
}
}
else
{//第一遍时如果该位置没有数据则会被填充
memcpy(mp_HashPtr[iHashPos].chMD5,pMD5,MD5_LENGTH);
mp_HashPtr[iHashPos].NextOffset = 0;
}
}
}
if (jj == 0)
{
//根据统计结果,生成公共溢出区
pFreeOffSet = new int[iHitCnt];
if (nullptr == pFreeOffSet)
{//内码公共溢出区申请失败
delete []mp_HashPtr;
return FALSE;
}
ZeroMemory(pFreeOffSet,sizeof(int)*iHitCnt);
}
if (jj == 1)
{
pp = 0;
}
}
delete []pFreeOffSet;注:
1. 本方案中的value为数据的MD5值,长度固定为32位。
2. 链表的节点的指针域存储的是指向下一个节点的数组偏移量,读取节点内容时需要使用数组首地址+偏移量来得到真正的节点内容
总结:
本方案结合了两种碰撞处理的优点,减少内存碎片及避免堆积现象出现。提高了查询效率。
缺点是:建表过程需要经过3次循环才可以完成。可能会增加等待时间,降低客户体验。
完
by Jared Kin















 239
239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









