







这算是比较贴近于实际生活的爬虫了,根据用户输入的关键字批量下载今日头条相关图集图片,,核心用到了urllib.request.urlretrieve()这个方法,然后百度了一下进度条怎么玩,直接把代码加上去了,没毛病,感觉代码有些复杂,其实理论上一层网页可以将所需额图片都爬取下来,但是当时担心出现问题,就多添加了一层网页url分析,主要用的还是json分析,这些都相对简单的,关键一层一层网页间的url链接分析,当时写的时候听懵逼的,循环太多(其实写完后再去看看还是一脸懵逼,怀疑是不是自己写的),
此次下载的是fate相关的图片,因为是ajax异步加载,这个其实很好控制的,但是网页数量太多,加上有等待时间,就没有加载太多网页直接上代码吧,(感觉注释挺明了的)
import requests
from bs4 import BeautifulSoup
from skimage import io
import urllib
import re
import time
import json
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
,'Accept':'application/json, text/javascript'
,'Host':'www.toutiao.com'
,'Connection':'keep-alive'
,'Accept-Encoding':'gzip, deflate'
,'Accept-Language':'zh-CN,zh;q=0.8'
,'Upgrade-Insecure-Requests':'1'
,'Referer':'http://www.toutiao.com/search/'
}
url = 'http://www.toutiao.com/search_content/?offset={}&format=json&keyword={}&autoload=true&count=20&cur_tab=3'
#urltest = 'http://www.toutiao.com/search_content/?offset=0&format=json&keyword=fate&autoload=true&count=20&cur_tab=3'
urllist = []#创建个列表用于存放每次异步加载所更新出来的20条网页url
name = input('请输入所要查找的图片关键词')
for i in range(0,2):#爬取前100条链接
urllist.append(url.format(i,name))
path = '/Users/loukun/Desktop/picture'
def Schedule(a,b,c):#显示下载进度
'''''
a:已经下载的数据块
b:数据块的大小
c:远程文件的大小
'''
per = 100.0 * a * b / c
if per > 100 :
per = 100
sys.stdout.write('\r%.2f%%' % per)
time.sleep(1)
if per == 100:
print('该图片加载完成')
urlname = []#存放每个图集的名称
urllist2 = []#存放每个图集的链接
def get_link(url):
session = requests.Session()
res = session.get(url)
soup = BeautifulSoup(res.text,'html.parser')
jd = json.loads(soup.text)
for articleurl in jd['data']:
name = articleurl['title']
urlimg = articleurl['url']
urlname.append(name)
urllist2.append(urlimg)
#print('图集名称:\n',name,'\n图集链接:\n',url)
return urllist2
#print(urllist)
for url in urllist:
#print('父URL',url)
get_link(url)
time.sleep(1)
def img_save(urllist3,urlname):
i2 = 1
for imgurl,imgname in zip(urllist3,urlname):#将列表中所存放的图片url打印出来,通过skimage将图片打印到控制台上
print('图片',i2,'链接:',imgurl)
print('图片',i2,'预览:\n')
imgname2 = imgname.lstrip('origin/')
try:#查看图片
fateimg = io.imread(imgurl)
io.imshow(fateimg)
io.show()
except OSError:
print('图片打开失败!!')
try:#保存图片
if not os.path.exists(path):#若该路径下面的文件夹不存在则创建一个
os.mkdir(path)
urllib.request.urlretrieve(imgurl,path +'/'+ 'fate系列' + imgname2 + '%s.jpg' % i2,Schedule)
print('下载完成\n\n')
except Exception:
print('下载失败')
#time.sleep(1)
i2 += 1
#通过正则表达式以及json将每张图片的url爬取出来并打印并下载到本地文件夹
def get_jsonurl(url,urlnamecon):
urllist3 = []#该列表用于存放每张图片的url
urlname = []
res = session.get(url,headers = headers)
res.text
soup = BeautifulSoup(res.text,'html.parser')
message = re.findall('gallery: (.*?),\n',soup.text,re.S)#通过正则表达式将json文件提取出来
jd = json.loads(message[0])#通过loads方法将json文件转化为字典形式
url = jd['sub_images']#通过json在线解析器将解析出来的字典类型的网页元素通过键找出其所对应的值
for url1 in url:
urllist3.append(url1['url'])
urlname.append(url1['uri'])#将每张图片的名称保存到列表中
img_save(urllist3,urlname)
num = 1
for urlcontent,urlnamecon in zip(urllist2,urlname):
print('图集',num,'名称:',urlnamecon)#打印每个图集的名称
print('图集',num,'链接:',urlcontent)#打印每个图集的链接
print(len(urlname))
get_jsonurl(urlcontent,urlnamecon)
num += 1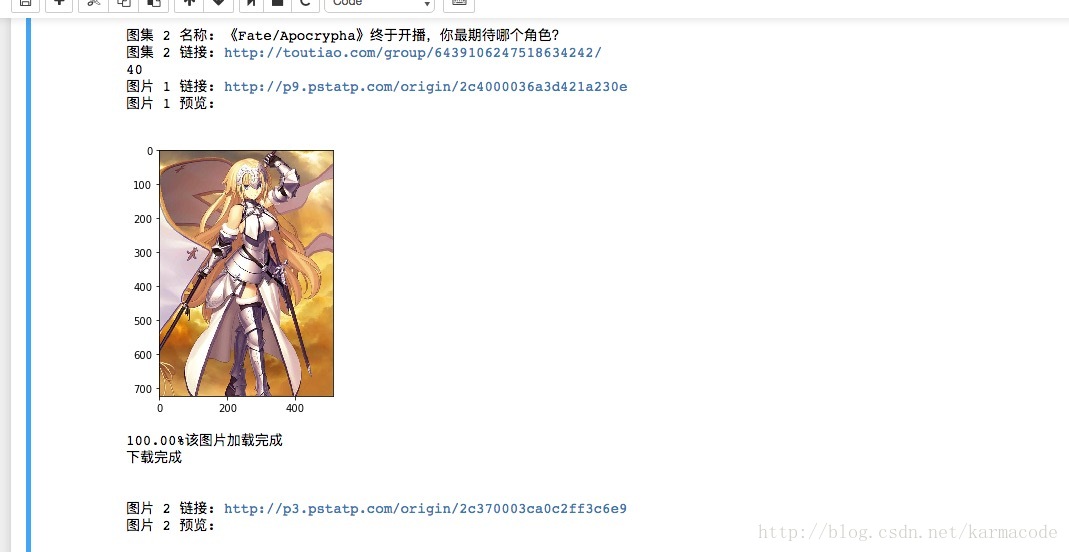
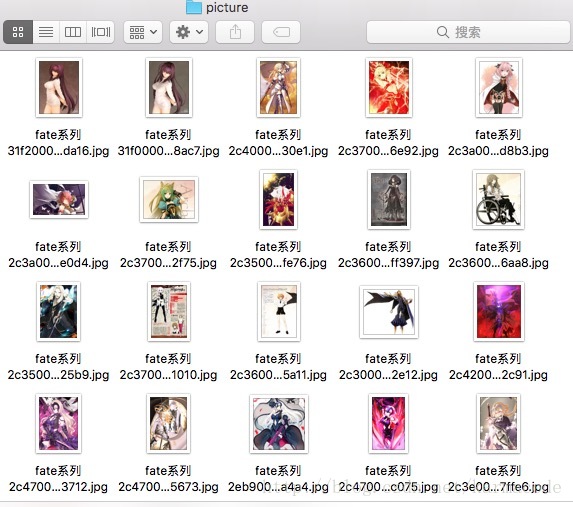
当时文件名没控制好,一直覆盖原来的文件,搞了好长时间,最后还是用了原图片地址内的部分字符串作为文件名了,这样免的覆盖了,
总之,马马虎虎,还有很多要改进的地方,,欢迎大佬们测试(此代码真的挺实用的 #滑稽)














 1283
1283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









