







HDFS不能够自动判断集群中各个datanode的网络拓扑情况。这种机架感知需要topology.script.file.name属性定义的可执行文件(或者脚本)来实现,文件提供了IP->rackid的翻译。NameNode通过这个得到集群中各个datanode机器的rackid。如果topology.script.file.name没有设定,则每个IP都会翻译成/default-rack。
下面给出了一个script文件的c语言示例。这个文件需要处理多个输入参数的情况,每个参数是个ip。文件的输出对应就是rackid串。
int main(int argc , char *argv[])
{
for(int i=1 ;i< argc; i++)
{
char* ipStr = argv[i];
// 找到ip对应的rack设置,下面的
cout<<"/rack1/"<<i<<" ";
}
cout<< endl;
}
网络拓扑
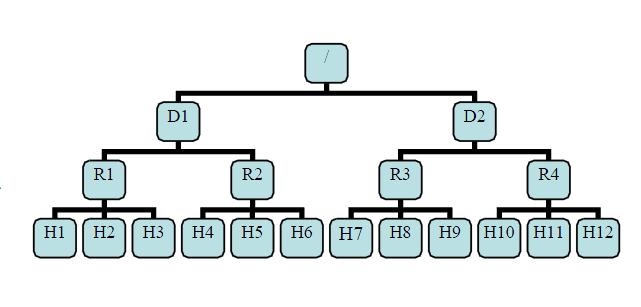
有了机架感知,NameNode就可以画出上图所示的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
副本放置策略
第一个block副本放在和client所在的node里(如果client不在集群范围内,则这第一个node是随机选取的,当然系统会尝试不选择哪些太满或者太忙的node)。
第二个副本放置在与第一个节点不同的机架中的node中(随机选择)。
第三个副本和第二个在同一个机架,随机放在不同的node中。
如果还有更多的副本就随机放在集群的node里。
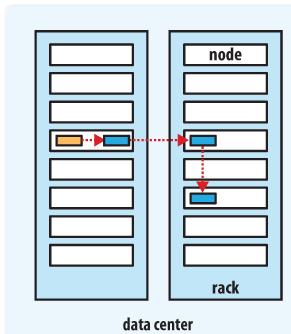
Hadoop的副本放置策略在可靠性(block在不同的机架)和带宽(一个管道只需要穿越一个网络节点)中做了一个很好的平衡。下图是备份参数是3的情况下一个管道的三个datanode的分布情况。
http://blog.csdn.net/a822631129/article/details/48628497















 105
105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









