







一、 HDFS部分原理
1. 回收站:Trash
回收站机制,为了防止用户删除一些 文件以后后悔了还想找回来,或者用户 因为操作失误删除了一些不想删除的文件。设置了删除文件后的回收站。用户可以在回收站自动清理之前进行恢复数据。
类似于Windows中的回收站,他们 都是在删除的时候不是直接从磁盘中清除数据 ,而是将文件移动到垃圾回收站的这个目录里面。当需要恢复的时候再从这个里面把文件移动出来。所以说回收站的本质就是文件的移动 。其中与Windows不同的是,Windows不会自动清除回收站里面的内容,只有当用户自己 手动清理回收站之后,回收 站中的 数据才会被清除。而在HDFS 中的回收站,是通过用户设置 的策略 ,在固定的 时间会清除回收站目录下的文件。
回收站书定时清理配置
<!--开启垃圾回收,需要在core-site.xml中添加如下配置,然后重启hdfs即可-->
<!--垃圾回收,1440 minites == 1天-->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
从回收站中回复数据(文件的移动)
hdfs dfs -mv /user/root/.Trash/Current/xxx /
2. NameNode的持久化
在NameNode中我们存储了文件块的元数据信息,因为 要快速的存取他会先存放在内存中(因为内存的存取速度很快),然后在持久化到硬盘上。那么他具体是怎么工作的呢,先来引入两个该概念 。
在Redis中,它的数据和HDFS一样也是存放在内存中的,这就存在一个问题,如果服务器突然宕机了,内存中的数据也就丢失了,所以我们 必须把数据持久化存储到我们的硬盘上。Redis就引入了两个持久化机制:PDB和AOF用来 解决数据会因故障丢失的问题。
RDB(快照)机制。他是将内存中的数据写入磁盘中永久保存,也是Redis的默认机制。他的原理是:它的主线程依然继续处理客户的请求,这时候创建出来一个子线程。子线程负责将进程创建前的内存数据(快照数据)写入到磁盘中(命名2为dump.rdb文件)。它的优点是:在保存快照是不会影响主进程的工作。方便备份很容易将一个rdb文件移动到其他机器上。rdb在恢复大数据的时候比 AOF快。缺点 因为每次做快照都要 保存 内存中的所有数据,所以就需要更多的时间,然而在他备份的时候也有可能出现宕机的情况造成数据丢失。
AOF(日志)机制。AOF(Append Only File)机制保存的是redis执行过的命令。原理:当Redis每执行一条 命令都会在日志文件(appendonly.aof)中记录下来。当Redis在重启的时候就重新执行日志文件中的命令来回复到之前的状态。**优点:**可以更好的保护 数据 不丢失,写入性能好,日志 可读性好,如果误删的话可以将日志中的删除命令移除就可以回复数据了 。缺点相同的数据集下 aof的文件通常大于RDB,数据恢复的时候会慢
在了解了这两个机制之后,那我们的HDFS就很聪明,直接把这两个结合起来使用,综合他们的优点来达到最佳方案。
HDFS在接受到客户端需要存储文件的信息之后,会先将操作的命令存储在edits log中,然后在修改内存中的元数据的信息。然后通过checkpoint机制,让他的辅助线程snn来完成持久化。
3. checkpoint机制
看图:

1. SecondaryNameNode向NameNode发起合并快照和日志请求
2. NameNode将当前的edits_inprogree文件保存改名edits_0-1000文件,并新建edits_inprogree继续持久化工作。
3. 将改名后的edits_0-1000文件和本地的快照(旧)发送给sencondaryNameNode
4. SecondaryNameNode负责将快照(旧)+edits文件合并成快照(新)
5. 将新的快照(新)发送给NameNode保存。
注意点:NameNode和SecondaryNameNode一般会分开放在两台服务器上。避免一旦服务器磁盘损坏持久化的数据全部丢失。
4. HDFS启动流程和安全模式
HDFS在启动的时候会自动进入安全模式,(在这个状态下只可以进行读操作)
在这个期间它主要会做如下一些事:
- 加载最新的快照数据,然后合并上次为合并完的log日志文件
- 等待 接受datanode的心跳(节点地址、健康状态、磁盘容量、剩余容量、版本号)
- 等待接收datanode的块信息报告。判断是否满足最小 副本因子(及块中是否至少存在一个正常 的块),并判断这些块的id、 offset(如果一个文件太大 会被分成好几个块,只有第一个块是从0开始的,其他的块都是衔接这上一个块的结尾开始的) 、length
- namenode会判断HDFS集群中所有的块是否完整,如果完整比例达到99.9%(这个参数可以调节)就可以正常的退出安全模式了。
- 退出安全模式,打开写功能正常运行。
如有异常也会进入安全模式,并且不会自动退出:
例如:
1、当在检查块的时候发现损坏的太多了。(如果一个块虽然损坏了但是只要他还有副本是好的就会自动修复)解决方法:手动 退出安全模式(hdfs dfsadmin -safemode leave)并找到损坏的块进行删除。
2、当磁盘容量达到警戒值的时候,会自动 进入安全模式。解决:删除不需要的文件。或者加磁盘 扩充容量
关于安全模式的一些手动操作
| 查看安全模式状态 | hdfs dfsadmin -safemode get |
|---|---|
| 进入安全模式 | hdfs dfsadminmode enter |
| 退出安全模式 | hdfs dfsadmin -safemode leave |
5. 文件上传流程
- 客户端向NameNode发送请求,说我想上传一个文件+(文件信息)
- NameNode收到请求后。会做一些检查(检查文件是否存在,若存在报错。检查上传文件的父目录是否存在,若存在,报错,检查权限信息。若无权限报错)
- Namodode检查完之后会给客户端一个响应。返回拆分块的信息。告诉他将块怎么拆分,拆分后等会上传到那个datanode上。一般如果有三个节点的话,会将第一个副本放到客户端所在的节点上第二个副本存放在第二个机架上的节点上,第三个副本存放在第二个机架上 的另一个节点上。
- 客户端收到NamoNode的响应之后,就开始将他要上传的东西进行逻辑切片,切成几个块
- 客户端开始准备上传文件块,构建传输通道,存储同一个块的所有节点形成一个数据流通道。
- 客户端开始上传文件,上传时底层一数据包(package)为单位传递,先传到底一个节点,第一个节点会先写在缓存中,同时向下一个节点传递和持久化到磁盘上。
- 当地一个块在 所有节点上上传完毕之后,关闭 上传通道
- 开始上传第二个块。。。。
- 所有数据上传完毕之后,向客户端返回 上传结果
10.客户端向NamoNode返回 信息 ,告诉他上传成功了
如果在上传 过程中 出现了异常,hdfs会进行重试,如果还失败会将失败的节点从上传通道里面删除,然后 返回给 NameNode。hdfs可以容忍最大程度就是有一个节点上传失败。如果都上传失败就会重新申请节点,重新构建上传通道。
6. 副本存放机制(体架感知)
Hadoop设计的目的就是解决海量大文件的处理问题,主要指大数据的存储和计算问题。其中HDFS解决数据存储的问题。MapReduce解决数据计算的问题
Hadoop设计分布式的存储和计算解决方案 架构在廉价的集群之上,所以服务器节点会出现宕机的情况,出于数据安全的考虑,HDFS的设计思路就是对用户存进HDFS里的所有数据都做 冗余备份 ,用来保证数据的安全
那么如果将三个备份都放到一个节点上的话显然不能保证安全,那他们就得放在不同机架的不同节点上。那么怎样即能 保证安全又能保证数据的存取效率,这就需要定制一些策略进行解决:
第一个副本存在在客户端, 如果客户端不在集群内, 就在集群内随机挑选一个合适的节点进行存放
第二个副本存在与第一个副本同机架, 且不同节点, 按照一定的规则挑选一个合适的节点进行存放
第三个副本存在与第一二副本不同机架且距第一个副本逻辑距离最短的机架, 按照一定的规则挑选一个合适的节点进行存放.
这样设计的优点:如果 本机的数据损坏,那么可以直接从同机架的不同 节点上获取数据,这样的速度一定比跨机架要快。如果本机架出现问题那么还可以在另一个机架上找到备份的数据继续使用。如果都存放到了一个机架上面,一个机架出现 问题整个数据就都没了。
如果需要使用机架感知需要在namenode的core-site.xml中配置如下配置:
#!/bin/bash
HADOOP_CONF=/opt/installs/hadoop2.9.2/etc/hadoop
while [ $# -gt 0 ] ;
do
nodeArg=$1
exec<${HADOOP_CONF}/topology.data
result=""
while read line
do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ]||[ "${ar[1]}" = "$nodeArg" ]
then
result="${ar[2]}"
fi
done
shift
if [ -z "$result" ]
then
echo -n "/default-rack"
else
echo -n "$result"
fi
done
然后配置一个topology.data的 文件
192.168.123.102 hadoop02 /switch1/rack1
192.168.123.103 hadoop03 /switch1/rack1
192.168.123.104 hadoop04 /switch2/rack2
192.168.123.105 hadoop05 /switch2/rack2
其中switch表示交换机,rack表示机架
需要注意的是,在Namenode上,该文件中的节点必须使用IP,使用主机名无效,而ResourceManager上,该文件中的节点必须使用主机名,使用IP无效,所以,最好IP和主机名都配上。
然后进行验证:
hdfs dfsadmin -printTopology
附加知识点:
1、增加datanode节点,不需要重启namenode
非常简单的做法:在topology.data文件中加入新加datanode的信息,然后启动起来就OK
2、节点间距离计算
有了机架感知,NameNode就可以画出下图所示的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离,得到最优的存放策略,优化整个集群的网络带宽均衡以及数据最优分配
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R2/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
————————————————
版权声明:本部分”机架感知“借鉴与CSDN博主「中琦2513」的文章,遵循CC 4.0 BY-SA版权协议
原文链接:https://blog.csdn.net/zhongqi2513/article/details/73695229
7. 文件下载流程
- 客户端向NameNode发送请求,说我想下载一个文件
- NameNode收到请求后。会做一些检查(检查文件是否存在,若存在就返回数据块及副本存储的节点信息)
- 客户端收到NamoNode的响应之后,就开始下载第一个块
- 客户端开始准备下载文件块,构建传输通道,存储同一个块的所有节点形成一个数据流通道。第一个块下载成功之后会生成一个 crc文件,和上传时候的.meta文件进行完整度校验
- 开始上传第二个块。。。。
- 所有数据上传完毕之后,向namenode返回下载结果
- 异常处理:当数据块的某个节点读取不到数据的时候就会向namenode回报,namenode就会把这个节点标记为异常节点,其他人再下载这个东西的时候就不会优先向他下载了,然后客户端就去读取其他也有这个块的节点来。块下载失败会有3次重新下载的机会。
二、分布式环境安装步骤
1.分布式环境搭建
分布式环境需要三台 CentOS 7做分布式
环境搭建思路:
先安装一台Centos7服务器。
1.配置主机的ip地址为静态地址,注意一下三个地方
vim /etc/sysconfig/network-scripts/ifcfg-ens33

2.关闭 防火墙。设置防火墙不开机自启
[root@localhost bin]# systemctl stop firewalld 关闭防火墙
[root@localhost bin]# systemctl status firewalld 查看防火墙状态
关闭防火墙开机自启动: systemctl disable firewalld
3.在/etc/hosts里面配置主机映射文件
vim /etc/hosts
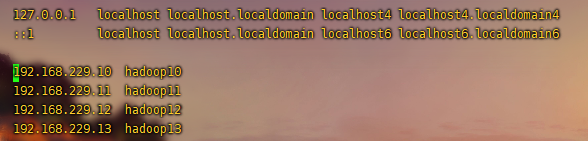
4.在/opt/下面建立三个目录,一个用来放软件的安装包。一个用来安装软件。一个用来存放数据
mkdir installs
mkdir modules
mkdir data
5.安装jdk环境,安装hadoop软件
首先将这两个压缩包上传到/opt/modules
然后解压到installs里面并重命名
解压: tar zxvf jdk-8u171-linux-x64.tar.gz -C /opt/installs/
tar zxvf jdk-8u171-linux-x64.tar.gz -C /opt/installs/
重命名:cd /opt/installs
mv jdk... jkd1.8
mv hadoop... hadoop...
说明: mv 源文件名字 新名字
6.配置 并刷新环境变量
vim /etc/profile
结尾加上如下配置:
export JAVA_HOME=/opt/installs/jdk1.8
export HADOOP_HOME=/opt/installs/hadoop2.9.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出之后刷新环境变量: source /etc/profile
结尾加上如下配置

7.配置hadoop配置文件(这些文件都在/hadoop/etc/hadoop/目录下)

1. hadoop-env.sh 配置JDk环境变量(第25行)

2. core-site.xml 配置hdfs的入口和数据要保存的位置

3. hdfs-site.xml 配置副本的个数和SecondaryNameNode节点的位置

4. slaves 配置从机datanode的ip
8.在上面安装完之后就可以关机并做一个快照,后面两个直接克隆,克隆完之后在做修改
11.复制过来两台做一下配置
修改IP地址(同上)
设置主机的名(hostnamectl set-hostname XXX 主机名) 设置主机的名字)
实现三台机器之间的相互免密登录
ssh-keygen
ssh-copy-id hadoop11
ssh-copy-id hadoop12
ssh-copy-id hadoop13
到此三台服务器已配置完成。
12启动测试:(此时所有操作均在hadoop11(即namenode)上操作)
1.首次安装需要格式化HDFS
hdfs namenode -format
2.启动hdfs
start-dfs.sh
3.浏览器上打开网站测试
192.168.229.11:50070
此时看到有三个datanode配置都成功了
















 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









