




 本文介绍了MongoDB中writeconcern的不同级别及其对写操作可靠性的影响。包括Unacknowledged、Acknowledged、Journalled和ReplicaAcknowledged等不同级别,并讨论了如何在性能和可靠性之间找到平衡。
本文介绍了MongoDB中writeconcern的不同级别及其对写操作可靠性的影响。包括Unacknowledged、Acknowledged、Journalled和ReplicaAcknowledged等不同级别,并讨论了如何在性能和可靠性之间找到平衡。
mongodb有一个write concern的设置,作用是保障write operation的可靠性。一般是在client driver里设置的,和db.getLastError()方法关系很大
一般来说,所有的mongo driver,在执行一个写操作(insert、update、delete)之后,都会立刻调用db.getLastError()方法。这样才有机会知道刚才的写操作是否成功,如果捕获到错误,就可以进行相应的处理。处理逻辑也是完全由client决定的,比如写入日志、抛出错误、等待一段时间再次尝试写入等。作为mongodb server并不关心,server只负责通知client发生了错误
这里有2点需要注意:
1、db.getLastError()方法是由driver负责调用的,所以业务代码不需要去显式调用。这点后面还会专门提到
2、driver一定会调用db.getLastError()函数,但是并不一定能捕获到错误。这主要取决于write concern的设置级别,这也是本文的主题
write concern:0(Unacknowledged)
此级别调用的时序图如下:
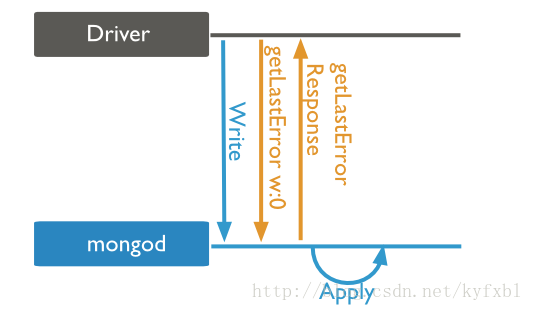
driver调用了getLastError()之后,mongod立刻返回结果,然后才实际进行写操作。所以getLastError()的返回值一定是null,即使之后的Apply发生了错误,driver也不知道。使用这个级别的write concern,driver的写入调用立刻返回,所以性能是最好的,但是可靠性是最差的,因此并不推荐使用。在各平台最新版本的driver中,也不再以0作为默认级别。其实还有一个w:-1的级别,是error ignored,基本上和w:0差不多。区别在于,w:-1不会捕获任何错误,而w:0可以捕获network error
write concern:1(acknowledged)
此级别调用的时序图如下:
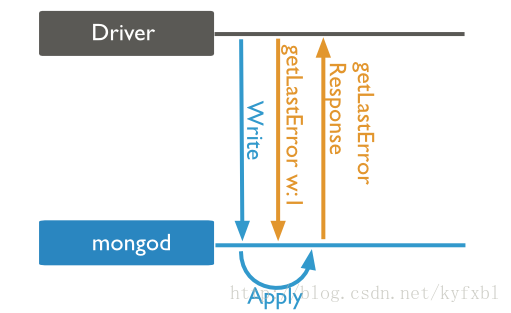
和Unacknowledged的区别是,现在mongod只有在Apply(实际写入操作)完成之后,才会返回getLastError()的响应。所以如果写入时发生错误,driver就能捕获到,并进行处理。这个级别的write concern具备基本可靠性,也是目前mongodb的默认设置级别
write concern:1 & journal:true(Jounaled)
此级别调用的时序图如下:
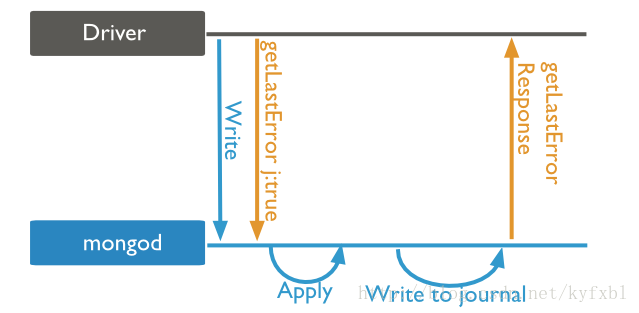
Acknowledged级别的write concern也不是绝对可靠的。因为mongodb的Apply操作,是将数据写入内存,定期通过fsync写入硬盘。如果在Apply之后,fsync之前mongod挂了,或者甚至server挂了,那持久化实际上是失败的。但是在w:1的级别下,driver无法捕获到这种情况下的error(因为response在apply之后就已经返回到driver)
mongod解决这个问题的办法是使用Journal机制,写操作在写入内存之后,还会写到journal文件中,这样如果mongod非正常down掉,重启以后就可以根据journal文件中的内容,来还原写操作。在64位的mongod下,journal默认是打开的。但是32位的版本,需要用--journal参数来启动
在driver层面,则是除了设置w:1之外,再设置journal:true或j:true,来捕获这个情况下的error
write concern:2(Replica Acknowledged)
这个级别只在replica set的部署模式下生效
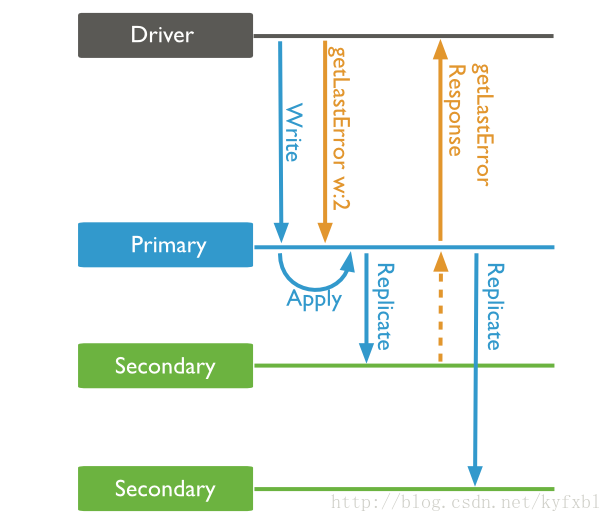
这个级别下,只有secondary从primary完成了复制之后,getLastError()的结果才会返回。也可以同时设置journal:true或j:true,则还要等journal写入也成功后才会返回。但是注意,只要primary的journal写入就会返回,而不需要等待secondary的journal也写入。类似的也可以设置w:3,表示至少要有3个节点有数据;或者w:majority,表示>1/2的节点有数据。一般小规模的集群就是3节点部署,所以配置w:2就可以了
建议
设置write concern级别,其实就是在写操作的性能和可靠性之间做权衡。写操作的等待时间越长,可靠性就越好。对于非关键数据,建议使用默认的w:1就可以了,对于关键数据,则使用w:1 & j:true比较好。这里要注意,journal无论如何都是建议打开的,设置j:true,只是说driver调用getLastError()之后是否要等待journal写入完成再返回。并不是说不设置j:true就关闭了server端的journal
关于getLastError()
一般来说,开发者写的代码,不需要自行调用db.getLastError()函数,driver在每一个写操作之后,都会立刻自动调用该方法
db.collection("test", {}, function (err, collection) {
collection.insert({name: "world peace"}, function (err, result) {
assert.equal(null, err);
console.log(result);
db.close();
})
});这段代码,driver在insert()之后,隐式调用db.getLastError(),如果捕获到任何错误,就会赋给回调函数中的err参数。区别就在于是否能够捕获到错误。在w:-1时,err永远是null(没有机会捕获到error);在w:0时,一般也捕获不到,除了network error;在w:1时,如果mongod apply发生错误,就会传递给err参数了。代码都是一样的,区别就在于设置的write concern级别

















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









