









#本文内容部分来自网络,只为自己学习以及分享供更多的人学习使用
1、超参数调试处理
之前介绍过的一些超参数

颜色表示重要程度。
关于训练深度最难的事情之一是你要处理的参数的数量, 从学习速率 α 到 Momentum的 β, 如果使用 Momentum 或 Adam 优化算法的参数, 即 β1 , β2 和 ε, 也许你还要设置隐藏层层数,隐藏层神经元数目,也许你还想使用学习率衰减,那么你使用的不是单一的学习速率 α, 可能还需要选择 Mini-batch 的大小, 结果证实其中一些超参数比其他的更为重要。学习速率 α 是需要调试的最重要的超参数, 除了还有一些参数需要调试, 比如Momentum 的 β=0.9 就是一个很好的默认值, 还有调试 mini-batch 的大小以确保最优算法运行有效,还可以调试隐藏单元 ,后面三个是其次比较重要的。重要性排第三位的是隐藏层层数,层数有时会产生很大的影响,学习率衰减也是如此。
在超参数选择的时候,一些超参数是在一个范围内进行均匀随机取值,如隐藏层神经元结点的个数、隐藏层的层数等。但是有一些超参数的选择做均匀随机取值是不合适的,这里需要按照一定的比例在不同的小范围内进行均匀随机取值,以学习率
α
的选择为例,在
0.001,…,1
范围内进行选择:
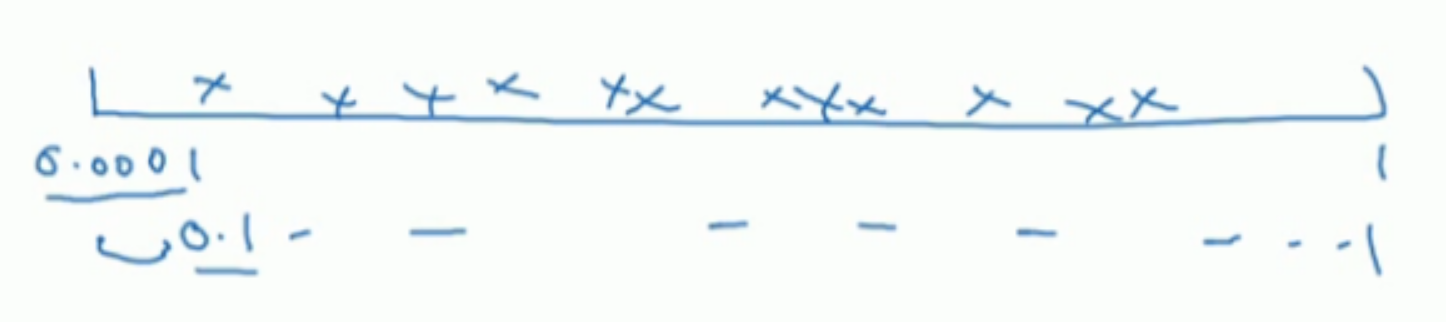
如果在 0.001,…,1 的范围内进行进行均匀随机取值,则有90%的概率 选择范围在 0.1∼1 之间,而只有10%的概率才能选择到 0.001∼0.1 之间,显然是不合理的.
代码实现:
- 1
- 2
一般的,如果在 10a∼10b 之间的范围内进行按比例的选择,则 r∈[a,b] , α=10r 。
- β=0.9,……,0.999
同理这里也不能使用线性轴来采样数据,我们可以通过对1-β=0.1,……,0.001来间接采样。转化成[0.1, 0.01],[0.01,0.001],转化成对数指数[-1,-2],[-2,-3]。
即
r∈[−3,−1],1−β=10r,β=1−10r
2、超参数调试实践–Pandas vs. Caviar


- 在计算资源有限的情况下,使用Babysetting Model,仅调试一个模型,每天不断优化;如图一,这一过程就像熊猫一样,只照顾一个宝宝,多的照顾不过来。
- 在计算资源充足的情况下,使用第二种,同时并行调试多个模型,选取其中最好的模型。如图二,就像鱼子酱一样,一下生多大一亿的孩子~~
其实说白了,就是资源是否充足,然后选择同时一次调试一个模型或者多个模型的区别。
3、正则化网络的激活函数
前面我们提到过,可以对输入数据进行归一化处理。其实,对于神经网络中的各隐藏层,也可以做同样的归一化处理。
Batch Norm 的实现:
以神经网络中某一隐藏层的中间值为例:
z(1),z(2),…,z(m)
:
μ=1m∑iz(i)σ2=1m∑i(z(i)−μ)2z(i)norm=z(i)−μσ2+ε‾‾‾‾‾‾√
这里加上
ε
是为了保证数值的稳定。
到这里所有
z
的分量都是平均值为0和方差为1的分布,但是我们不希望隐藏层的单元总是如此,也许不同的分布会更有意义,所以我们再进行计算:
z˜(i)=γz(i) n +β
这里
γ
和
β
是可以更新学习的参数,如神经网络的权重
w
一样,两个参数的值来确定
z˜(i)
所属的分布。

将Batch Norm 应用到神经网络中:
- for t = 1 … num (这里num 为Mini Batch 的数量):
- 在每一个
Xt
上进行前向传播(forward prop)的计算:
- 在每个隐藏层都用 Batch Norm 将
z[l]
替换为
z˜[l]
- 使用反向传播(Back prop)计算各个参数的梯度:
dw[l]、dγ[l]、dβ[l]
- 更新参数:
-
w[l]:=w[l]−αdw[l]
-
γ[l]:=γ[l]−αdγ[l]
-
β[l]:=β[l]−αdβ[l]
- 同样与Mini-batch 梯度下降法相同,Batch Norm同样适用于momentum、RMSprop、Adam的梯度下降法来进行参数更新。
另外,我们知道正常情况下,还有一个参数b,但是由于
β的存在,其实可以直接省略掉b参数,因为两者都属于常数项,留一个参数就可以。
Batch Norm 的好处:
首先,Batch Norm 通过对输入层的输入特征进行归一化,可以使得每一次梯度下降
都可以更快的接近函数的最小值点,
从而加速模型训练过程的原理是有相同的道理。
其次,batch norm可以使得权重比你的网络更滞后或更深层


Batch Norm 的实现:
以神经网络中某一隐藏层的中间值为例:
z(1),z(2),…,z(m)
:
这里加上 ε 是为了保证数值的稳定。
到这里所有 z 的分量都是平均值为0和方差为1的分布,但是我们不希望隐藏层的单元总是如此,也许不同的分布会更有意义,所以我们再进行计算:
这里 γ 和 β 是可以更新学习的参数,如神经网络的权重 w 一样,两个参数的值来确定 z˜(i) 所属的分布。
- for t = 1 … num (这里num 为Mini Batch 的数量):
- 在每一个
Xt
上进行前向传播(forward prop)的计算:
- 在每个隐藏层都用 Batch Norm 将 z[l] 替换为 z˜[l]
- 使用反向传播(Back prop)计算各个参数的梯度: dw[l]、dγ[l]、dβ[l]
- 更新参数:
- w[l]:=w[l]−αdw[l]
- γ[l]:=γ[l]−αdγ[l]
- β[l]:=β[l]−αdβ[l]
- 在每一个
Xt
上进行前向传播(forward prop)的计算:
- 同样与Mini-batch 梯度下降法相同,Batch Norm同样适用于momentum、RMSprop、Adam的梯度下降法来进行参数更新。
训练过程中,我们是在每个Mini-batch使用Batch Norm,来计算所需要的均值 μ 和方差 σ2 。但是在测试的时候,我们需要对每一个测试样本进行预测,无法计算均值和方差。通常的方法就是在我们训练的过程中,对于训练集的Mini-batch,使用指数加权平均,当训练结束的时候,得到指数加权平均后的均值 μ 和方差 σ2 ,而这些值直接用于Batch Norm公式的计算,用以对测试样本进行预测。当然,如果不用指数加权平均的方法,直接计算训练集中的均值与方差,也是可行的。
4、Softmax
前面我们介绍的分类方法其实都是二分分类。而Softmax回归可以将多分类任务的输出转换为各个类别可能的概率,从而将最大的概率值所对应的类别作为输入样本的输出类别。
附上两个链接拓展阅读:
http://ufldl.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92
https://zhuanlan.zhihu.com/p/21485970
下面为部分摘抄:
Softmax 回归 vs. k 个二元分类器
如果你在开发一个音乐分类的应用,需要对k种类型的音乐进行识别,那么是选择使用 softmax 分类器呢,还是使用 logistic 回归算法建立 k 个独立的二元分类器呢?
这一选择取决于你的类别之间是否互斥,例如,如果你有四个类别的音乐,分别为:古典音乐、乡村音乐、摇滚乐和爵士乐,那么你可以假设每个训练样本只会被打上一个标签(即:一首歌只能属于这四种音乐类型的其中一种),此时你应该使用类别数 k = 4 的softmax回归。(如果在你的数据集中,有的歌曲不属于以上四类的其中任何一类,那么你可以添加一个“其他类”,并将类别数 k 设为5。)
如果你的四个类别如下:人声音乐、舞曲、影视原声、流行歌曲,那么这些类别之间并不是互斥的。例如:一首歌曲可以来源于影视原声,同时也包含人声 。这种情况下,使用4个二分类的 logistic 回归分类器更为合适。这样,对于每个新的音乐作品 ,我们的算法可以分别判断它是否属于各个类别。
现在我们来看一个计算视觉领域的例子,你的任务是将图像分到三个不同类别中。(i) 假设这三个类别分别是:室内场景、户外城区场景、户外荒野场景。你会使用sofmax回归还是 3个logistic 回归分类器呢? (ii) 现在假设这三个类别分别是室内场景、黑白图片、包含人物的图片,你又会选择 softmax 回归还是多个 logistic 回归分类器呢?
在第一个例子中,三个类别是互斥的,因此更适于选择softmax回归分类器 。而在第二个例子中,建立三个独立的 logistic回归分类器更加合适。
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











