






简介
Connectionist Temporal Classification(CTC) 是一种用来在语音识别、手写体识别等序列问题中训练深度神经网络的算法。
考虑下语音识别。 我们有一个音频剪辑片段数据集和相应的转录,但不幸的是,我们不知道转录中的字符如何与音频对齐,这让训练一个语音识别器的难度比初看起来的要大。
失去这种对齐,简单的方法对我们来说不能用了。 我们可以制定一个规则,比如“一个字符对应十个输入”。 但是人们的语速在变化,所以这种规则总是可以被打破。
这个问题不只是在语音识别中出现。 我们在其他许多地方看到它。 比如手写体识别、 视频行为标注。


Speech recognition: The input can be a spectrogram or some other frequency based feature extractor.
连接主义时间分类器(CTC)是一种避开输入和输出之间的对齐的方式。 我们会看到,它特别适合语音和手写识别等应用。
考虑从输入序列X=[x1, x2,...,xt]映射到输出序列Y=[y1, y2,...yu],比如音频的转录。我们希望找到一个从X‘s到Y’s的准确的映射。
存在一些挑战让我们不能使用更简单的有监督学习算法,尤其是:
- X和Y的长度可以变。
- X和Y的长度比例可变
- 我们没有一个X和Y之间的准确的对齐(对应元素)。
CTC算法可以克服这些挑战。对于一个给定的X,它给我们一个所有可能Y值的输出分布。我们可以使用这个分布来推断可能的输出或者评估一个给定输出的概率。
并不是所有的计算损失函数和执行推理的方法都是易于处理的。 我们要求CTC可以有效地做到这两点。
损失函数:对于给定的输入,我们希望训练模型来最大化分配到正确答案的概率。 为此,我们需要有效地计算条件概率p(Y | X)。 函数p(Y | X)也应该是可微的,可以使用梯度下降。
推理:在我们训练好模型后,我们希望使用它来推断给定X的最可能的Y。就是解
理想情况下,Y*可以被有效地找到。有了CTC,我们就可以找到一个近似的解,这个解不太难找。
算法
给定一个X,CTC算法可以为任意Y分配一个概率。计算这个概率的关键是CTC如何考虑输入和输出之间的对齐。我们先看看这些对齐,然后展示如何使用它们来计算损失函数并执行推理。
对齐
CTC算法是无需对齐的-它不需要输入和输出之间的对齐。然而,为了得到给定输入的一个输出的概率,CTC通过总结两者之间所有可能的对齐的概率来进行工作。 为了理解损失函数最终是如何计算的,我们需要了解这些对齐是什么。为了激发CTC对齐的具体形式,首先考虑一种初级的做法。 我们举个例子,假设输入长度为6, Y=[c,a,t]。 对齐X和Y的一种方法是将输出字符分配给每个输入步骤并折叠重复的部分。
这种方法存在两个问题。
- 通常,强制每个输入步骤与某些输出对齐是没有意义的。 例如在语音识别中,输入可以具有无声的延伸,但没有相应的输出。
- 我们没有办法产生连续多个字符的输出。 考虑这个对齐[h,h,e,l,l,l,o],折叠重复将产生“helo”而不是“hello”。
CTC允许的对齐是与输入的长度相同。 在合并重复并移除ε标记后,我们允许任何映射到Y的对齐方式:

让我们回到输入长度为6的输出[c,a,t]。 以下是一些有效和无效对齐的例子。

损失函数


如果我们不小心,CTC的loss计算可能非常昂贵。 我们可以尝试简单的方法,计算每个对齐的得分并把他们累加到一起。 问题是可以存在大量的对齐,对大多数问题,这太慢了。
庆幸的是,我们可以使用动态规划算法更快的计算loss。 关键点是,如果两个对齐在同一步已经达到了相同的输出,可以合并它们。


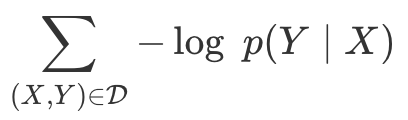
推理
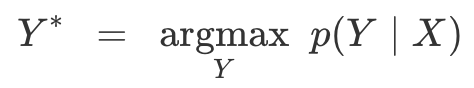
对许多应用来说,这种启发式算法表现不错,特别是当大多数大概率被分配到单个对齐时。 但是这种方法有时会错过很容易找到的更高概率的输出。 问题就在于,它没有考虑到单个输出可以有多个对齐的事实。















 136
136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









