






Embedding原理
应用中一般将物体嵌入到一个低维空间
 ,只需要再compose上一个从
,只需要再compose上一个从 到的线性映射就好了。每一个
到的线性映射就好了。每一个 的矩阵
的矩阵 都定义了到的一个线性映射:
都定义了到的一个线性映射: 。当
。当 是一个标准基向量的时候,
是一个标准基向量的时候,对应矩阵
中的一列,这就是对应id的向量表示。这个概念用神经网络图来表示如下:
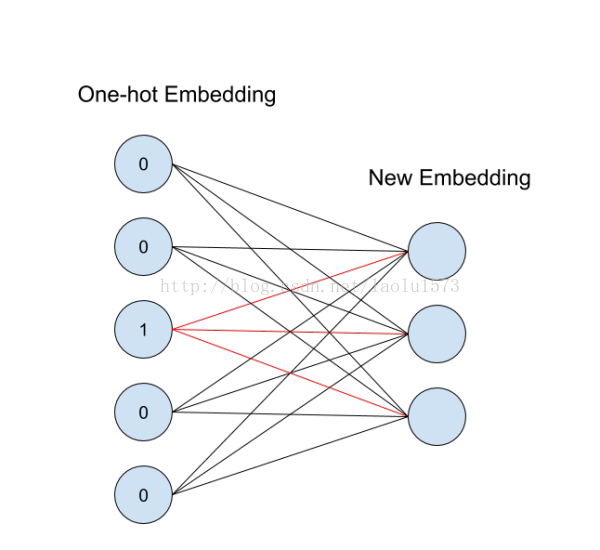
从id(索引)找到对应的One-hot encoding,然后红色的weight就直接对应了输出节点的值(注意这里没有activation function),也就是对应的embedding向量。
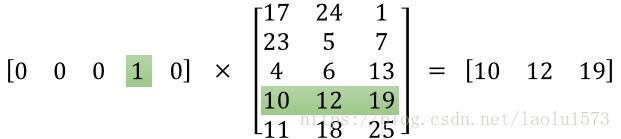
One-hot型的矩阵相乘,可以简化为查表操作,这大大降低了运算量。
tf.nn.embedding_lookup:
tf.nn.embedding_lookup()就是根据input_ids中的id,寻找embeddings中的第id行。比如input_ids=[1,3,5],则找出embeddings中第1,3,5行,组成一个tensor返回。
embedding_lookup不是简单的查表,id对应的向量是可以训练的,训练参数个数应该是 category num*embedding size,也就是说lookup是一种全连接层。
看一段代码:
#!/usr/bin/env/python # coding=utf-8 import tensorflow as tf import numpy as np # 定义一个未知变量input_ids用于存储索引 input_ids = tf.placeholder(dtype=tf.int32, shape=[None]) # 定义一个已知变量embedding,是一个5*5的对角矩阵 # embedding = tf.Variable(np.identity(5, dtype=np.int32)) # 或者随机一个矩阵 embedding = a = np.asarray([[0.1, 0.2, 0.3], [1.1, 1.2, 1.3], [2.1, 2.2, 2.3], [3.1, 3.2, 3.3], [4.1, 4.2, 4.3]]) # 根据input_ids中的id,查找embedding中对应的元素 input_embedding = tf.nn.embedding_lookup(embedding, input_ids) sess = tf.InteractiveSession() sess.run(tf.global_variables_initializer()) # print(embedding.eval()) print(sess.run(input_embedding, feed_dict={input_ids: [1, 2, 3, 0, 3, 2, 1]}))

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









