









**作者:**Mr. Ceong
链接:http://blog.csdn.net/leigaiceong/article/details/53188454
Python3 实现大众点评网酒店信息和酒店评论的网页爬取
概要
本文根据已有的的”大众点评网”酒店主页的URL地址,自动抓取所需要的酒店的名称、图片、经纬度、酒店价格、星级评分、用户评论数量以及用户评论的用户ID、用户名字、评分、评论时间等,并且将爬取成功的内容存放到.txt文档中。本文是在博文http://blog.csdn.net/drdairen/article/details/51146961的基础上进行实现和完善。因此十分感谢该文作者的无私奉献!。
正文
一、基本信息
- 编程语言: Python 3.5.2
- 实现平台: Eclipse for Pydev
- 实现功能:
1.爬取酒店的基本信息(包括:酒店名称、地址、图片、经纬度、酒店价格、星级评分、用户评论数量)
2.爬取酒店的评论信息(包括:酒店评论用户ID、用户名字、房间评分、服务评分、总评分、评价时间、酒店评论内容) - 实现代码: http://download.csdn.net/detail/qq_22107075/9668373
- 注意事项:
1.在抓取大众点评网的评论的时候如果访问大众点评网的频率过于频繁会导致大众点评网的反爬虫技术短暂屏蔽PC的IP地址(时长不定)
2.本文通过设置Python的time模块的sleep time来限定爬取评论的时间
二、实现过程
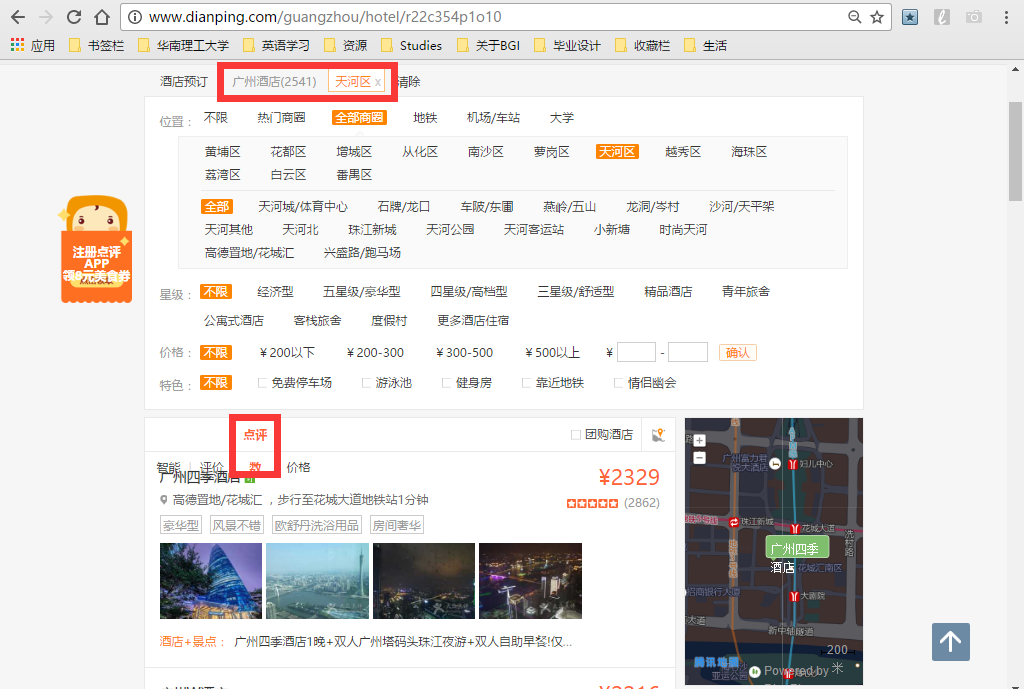
本文爬取的内容为广州市天河区附近用户评论数大于100的热门酒店(按评论数排名,如下图)。
实现思路
程序解读
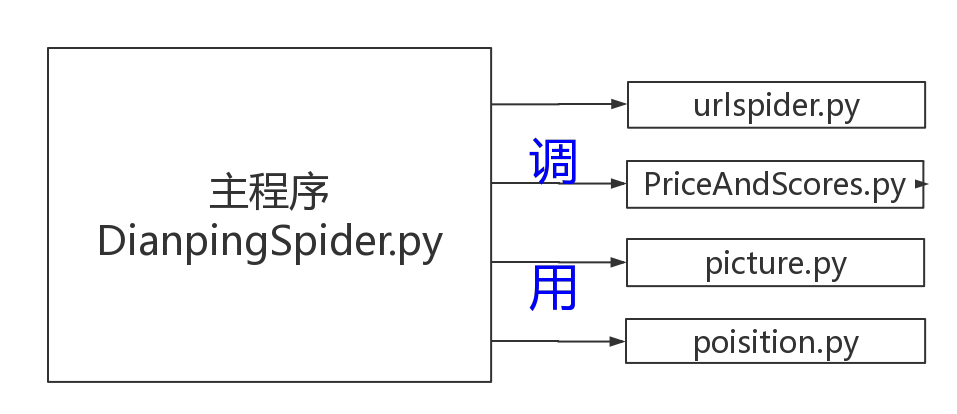
- 程序总共包含5个模块
DianpingSpider.py 主程序
picture.py 爬取酒店图片
position.py 根据POI参数转换成经纬度
PriceAndScores.py 爬取酒店价格和星级评分
urlspider.py 爬取广州市天河区附近热门酒店的URL
文件夹 hotel 存放成功爬取的酒店信息和用户评论
文件夹 image 存放成功爬取的酒店图片 - 模块解说
(1)DianpingSpider.py
该模块是实现本文的主程序,只要运行本程序即可实验本文功能。主要功能是调用另外四个模块及实现其他未实现的功能(详情请看代码)
实现原理为爬虫常用的Python 3模块,如:urllib.request、re、time,网上学习资料非常多,在此不作赘诉,烦请自己google。
import urllib.request
import re
import time
import picture #获取酒店图片
import urlspider #获取酒店的主页网址
import position #获取酒店的经纬度
import os
import random
import PriceAndScores #获取酒店的价格和星级评分
# 统计所有酒店的评价信息,存入文本
def getRatingAll(fileIn):
count =0 # 计数,显示进度
websitenumber=0
for line in open(fileIn,'r'): # 逐行读取并处理文件,即hotel的url
count=line.split('\t')[0]
line=line.split('\t')[1]
websitenumber+=1
print("正在抓取第%s个网址的酒店信息"%(websitenumber))
try:
print("正在抓取第%s家酒店的信息,网址为%s"%(count,line.strip('\n')))
# 获取酒店编号
hotelid = line.strip('\n').split('/')[4]
#print('该酒店的hotelid是 : ', hotelid)
# 拼凑出该酒店第一页"评论页面"的url
url = line.strip('\n') + "/review_more"
#print('该酒店第一页"评论页面"的url是', url)
# 模拟浏览器,打开url
headers = ('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko')
opener = urllib.request.build_opener()
opener.addheaders = [headers]
data = opener.open(url).read()
#print(data) 当访问大众点评网过于次数频繁的时候,大众点评网的反爬虫技术会封锁本机的IP地址,此时data就会出现异常,无法打印正常的html
data = data.decode('utf-8', 'ignore')
#print(data)
# 获取酒店用户评论数目
rate_number = re.compile(r'全部点评</a><em class="col-exp">\((.*?)\)</em></span>', re.DOTALL).findall(data)
rate_number = int(''.join(rate_number)) # 把列表转换为str,把可迭代列表里面的内容用‘ ’连接起来成为str,再进行类型转换
print("第%d家酒店的评论数为%s" % (websitenumber, rate_number))
if(rate_number<100):#若酒店评论数目少于100条,则不跳过该酒店,不再挖取信息
continue
# 获取酒店名称和地址
opener1 = urllib.request.build_opener()
opener1.addheaders = [headers]
hotel_url =opener1.open(line).read()
hotel_data = hotel_url.decode('utf-8')#ignore是忽略其中有异常的编码,仅显示有效的编码
#print(hotel_data) #当访问大众点评网过于次数频繁的时候,大众点评网的反爬虫技术会封锁本机的IP地址,此时hotel_data就会出现异常,无法打印正常的html
# 获取酒店名称
shop_name=re.compile(u'<h1 class="shop-name">(.*?) </h1>',re.DOTALL).findall(hotel_data)
shop_name=str(''.join(shop_name)) #类型转换
shop_name=shop_name.strip() #去掉字符串中的换行符
# 获取酒店地址
address=re.compile(u'<p class="shop-address">地址: (.*?)\n <span>',re.DOTALL).findall(hotel_data)
address=str(''.join(address))
#print(address)
# 获取酒店经纬度
poi=re.compile(r'poi: \"(.*?)\",',re.DOTALL).findall(hotel_data)
poi=str(''.join(poi))
(longitude,latitude)=position.getPosition(poi)
print("longitude:%s°E,latitude:%s°N"%(longitude,latitude))
#获取酒店评分和酒店价格
(price,scores)=PriceAndScores.getPriceAndScores(line.strip('\n'))
# 获取酒店图片
PictureOut ='.\\image\\'+str(count)+" "+shop_name
picture.getPicture(line.strip('\n'), PictureOut)
#保存酒店信息
fileOut='.\\hotel\\'+str(count)+" "+shop_name+'.txt'
if os.path.exists(fileOut):
os.remove(fileOut)
fileOp = open(fileOut, 'a', encoding="utf-8")
fileOp.write("酒店名称: %s\n酒店网址: %s\n地址: %s\n经度: %s°E,纬度: %s°N\n酒店评分: %d stars\n酒店价格:¥ %d 元起/人\n评论数量: %s\n"%(shop_name,line.strip('\n'),address,longitude,latitude,scores,price,rate_number))
fileOp.write( "酒店ID \t\t 用户ID \t\t 用户名字 \t\t 房间评分 \t\t 服务评分 \t\t 用户总评分 \t\t 评价时间 \n")
fileOp.close()
FileName='.\\hotel\\'+str(count)+" "+shop_name+' 用户评论.txt'
if os.path.exists(FileName):
os.remove(FileName)
# 解析评分
pages = int(rate_number / 20) + 1 # 由评论数计算页面数,大众点评网每页最多20条评论.
# print(pages)
for i in range(1, pages + 1):
# 打开页面
add_url = url + '?pageno=' + str(i)
headers = ('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko')
opener = urllib.request.build_opener()
opener.addheaders = [headers]
data = opener.open(add_url).read()
data = data.decode('utf-8', 'ignore')
# 获取酒店评论用户ID列表
userid_temp=re.compile(r'<a target="_blank" rel="nofollow" href="/member/(.*?)" user-id="(.*?)" class="J_card">', re.DOTALL).findall(data)
userid=[None]*len(userid_temp)
for i in range(0,len(userid_temp)):
userid[i]=userid_temp[i][0]
# 获取酒店评论用户的名字
username = re.compile(r'<img title="(.*?)" alt=', re.DOTALL).findall(data)
# 获取评价时间
rate_time = re.compile(r'<span class="time">(..-..)', re.DOTALL).findall(data)
# 获取单项评分
rate_room = re.compile(r'<span class="rst">房间(.*?)<em class="col-exp">', re.DOTALL).findall(data)
# rate_envir = re.compile(r'<span class="rst">位置(.*?)<em class="col-exp">', re.DOTALL).findall(data)
rate_service = re.compile(r'<span class="rst">服务(.*?)<em class="col-exp">', re.DOTALL).findall(data)
# 获取总评分
rate_total = re.compile(r'" class="item-rank-rst irr-star(.*?)0"></span>', re.DOTALL).findall(data)
mink = min(int(len(userid)), int(len(rate_total)), int(len(rate_room)))
# 获取用户评论
user_comments= re.compile(r'<div class="J_brief-cont">(.*?)</div>',re.DOTALL).findall(data)
user_comments=str(''.join(user_comments)) #类型转换
user_comments=user_comments.strip() #去掉字符串中的换行符
#print(user_comments)
#将除酒店评论外的信息写入文件
fileOp = open(fileOut, 'a', encoding="utf-8")
for k in range(0, mink):
fileOp.write('%s \t\t %s \t\t %s \t\t %s \t\t %s \t\t %s \t\t %s \t\t\n' % (hotelid, userid[k], username[k], rate_room[k], rate_service[k], rate_total[k], rate_time[k]))
fileOp.close()
#将酒店评论写入另外的文件
CommentsFile=open(FileName, 'a', encoding="utf-8")
CommentsFile.write(user_comments.strip('\n'))
CommentsFile.close()
sleepNum=random.randint(0,2)
time.sleep(sleepNum)#当访问过频的时候,大众点评网的发爬虫技术可能会临时封锁我们的ip,所以可以通过设定时间来调整爬取速度,建议慢速爬取。或者通过代理ip来避免反爬虫技术封锁IP
print(sleepNum)
print("成功挖取第%s酒店的信息\n"%(count))
# 异常处理:若异常,存储该url到新文本中,继续下一行的抓取
except:
print("第%s个酒店网址的信息抓取失败\n"%(websitenumber))#发生异常,无法成功爬取有用信息,抓取失败
exceptionFile='exception.txt'
file_except = open(exceptionFile,'a')
file_except.write("%s\t\t%s"%(str(websitenumber),line)) #将爬取酒店信息时发生异常的网址保存起来
#----------------------------------
#------------测试爬虫程序-------------
#----------------------------------
if __name__ == "__main__":
urlspider.getHotelUrl(1) #爬取符合条件的酒店的主页网址
fileIn = "HotelUrl.txt" #需要爬取酒店的网址
getRatingAll(fileIn)#抓取酒店评论页面的间隔时间,单位为秒,可为0(2)urlspider.py
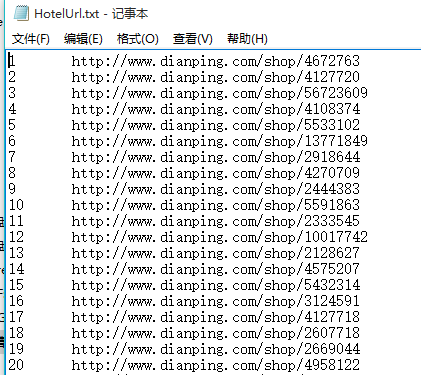
本模块主要是爬取广州市天河区附近热门酒店的主页网址(酒店出现的顺序按评论数排名)。从程序中可以看出,我们需要从http://www.dianping.com/guangzhou/hotel/r22c354pno10 (最后一个 n 表示页数 1-50,并非为字母,通过改变 n 值可以遍历所有页面,找到所有酒店)中爬取每一页的所有酒店。在以访客方式访问时只能查看最多50页的酒店,不过已经足够了,毕竟评论数大于100条的其实并不多。爬取下来的酒店主页保存在“./HotelUrl.txt”。
代码如下:
import urllib.request
import re
import os
def getHotelUrl(count):
filename ='HotelUrl.txt'
if os.path.exists(filename):
# print("Yes")
os.remove(filename)
print("正在获取广州市天河区附近热门酒店的URL,保存至HotelUrl.txt")
for k1 in range(1,51):
tempurlpag = "http://www.dianping.com/guangzhou/hotel/r22c354p"+str(k1)+"o10"
#下面对于当前页拿到每个酒店网址并加入队列
headers = ('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko')
opener = urllib.request.build_opener()
opener.addheaders = [headers]
op = opener.open(tempurlpag)
data= op.read().decode(encoding='UTF-8')
linkre = re.compile(r'data-shop-url="(.*?)"\r\n data-hippo', re.DOTALL).findall(data)
# print(linkre)
for k2 in range(0, len(linkre)):
tempurlhotel = "http://www.dianping.com/shop/" + linkre[k2]
fileOp = open(filename, 'a', encoding="utf-8")
fileOp.write(str(count)+"\t"+tempurlhotel+'\n')
fileOp.close()
count+=1
#print('目前是第: %d 页的第: %d 个酒店,其地址是 :%s'%(k1+1,k2+1,tempurlhotel))
print('第: %d 页抓取完成!'%k1)
#----------------------------------
#--------测试抓取酒店URL程序------------
#----------------------------------
if __name__ == "__main__":
count=1
getHotelUrl(count)运行结果:
(3)position.py
本模块主要用来爬取大众点评网的经纬度信息。大众点评网的地图位置很精确,但从HTML源码中却找不到坐标(经纬度)信息。本文将HTML中的js文本的POI参数转换成坐标,从而获取经纬度信息。参考于资料http://www.site-digger.com/html/articles/20111110/18.html,如有兴趣可仔细专研。
部分代码:
# coding: utf-8
# 解析大众点评地图坐标参数(POI)
def to_base36(value):
#将10进制整数转换为36进制字符串
if not isinstance(value, int):
raise(TypeError("expected int, got %s: %r" % (value.__class__.__name__, value)))
if value == 0:
return "0"
if value < 0:
sign = "-"
value = -value
else:
sign = ""
result = []
while value:
(value, mod)= divmod(value, 36)
result.append("0123456789abcdefghijklmnopqrstuvwxyz"[mod])
return(sign + "".join(reversed(result)))
def getPosition(C):
#解析大众点评POI参数
digi = 16
add = 10
plus = 7
cha = 36
I = -1
H = 0
B = ''
J = len(C)
G = ord(C[-1])
C = C[:-1]
J -= 1
for E in range(J):
D = int(C[E], cha) - add
if D >= add:
D = D - plus
B += to_base36(D)
if D > H:
I = E
H = D
A = int(B[:I], digi)
F = int(B[I+1:], digi)
L = (A + F - int(G)) / 2
latitude = float(F - L) / 100000
longitude = float(L) / 100000
return longitude,latitude
#-----------------------------
#-----------测试程序-----------
#-----------------------------
if __name__ == '__main__':
(longitude,latitude)=getPosition('IJGDHFZVIBRDHR')
print("longitude:%s°E,latitude:%s°N"%(longitude,latitude))(4) picture.py
本模块主要实现酒店图片的爬取。每个酒店的主页都会有几张该酒店的图片,我们将它们中的前5张(有些酒店少于5张)给爬取下来,存放到“./image”文件夹中。主要思路是将html中的图片对应链接给爬取出来,然后保存到该文件夹下即可。
import urllib.request
import re
def getPicture(url,FileOut):
webPage=urllib.request.urlopen(url)
data = webPage.read()
data = data.decode('UTF-8')
picture_temp=re.compile(r'<img src="(.*?)%',re.DOTALL).findall(data)
picture_url=picture_temp[0:5]#只需要获取前五张图片即可
#print(picture_url)
for i in range(0,5):
web = urllib.request.urlopen(picture_url[i])
#print(web)
itdata = web.read()
#print(itdata)
f = open(FileOut+str(i+1)+'.jpg',"wb")
f.write(itdata)
f.close()
#----------------------------------
#--------------测试程序---------------
#----------------------------------
if __name__ == "__main__":
url = "http://www.dianping.com/shop/4672763"
HotelName=u"广州四季酒店"
#FileOut ='G:/EclipseWorkspace/Python/src/InternetWorm/Image/'+HotelName
FileOut ='.\\image\\'+HotelName
getPicture(url,FileOut)运行结果:

(5)PriceAndScores.py
本模块获取每个酒店的价格和星级评分。注意获取酒店价格的时候我把酒店网址“www.dianping.com/shop/*”改为“m.dianping.com/shop/*”。主要是有部分www端酒店主页的价格是动态网页,爬取较为麻烦,有兴趣你自己可以试一下,而m端的网页价格是静态网页,爬取较为简单。
程序如下:
import urllib.request
import re
## 获取酒店名称和地址
def getPriceAndScores(url):
url=url.replace('www.','m.')#爬取价格的时候需要将酒店的PC端(www.)的改为APP端(m.)
#print(url)
opener = urllib.request.build_opener()
headers = ('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko')
opener.addheaders = [headers]
data=opener.open(url).read()
data= data.decode('utf-8')#ignore是忽略其中有异常的编码,仅显示有效的编码
#获取酒店总评分
scores=re.compile(r'<span class="star star-(.*?)"></span>',re.DOTALL).findall(data)
#scores=str(' '.join(scores))
scores = int(scores[0])/10
#print(scores)
#获取酒店价格
price =re.compile(r'<span class="price">(.*?)</span>',re.DOTALL).findall(data)
price = int(''.join(price ))
#print(price )
return price,scores
if __name__ == "__main__":
url="http://www.dianping.com/shop/2256811"
(price,scores)=getPriceAndScores(url)
print(price)
print(scores)结果展示
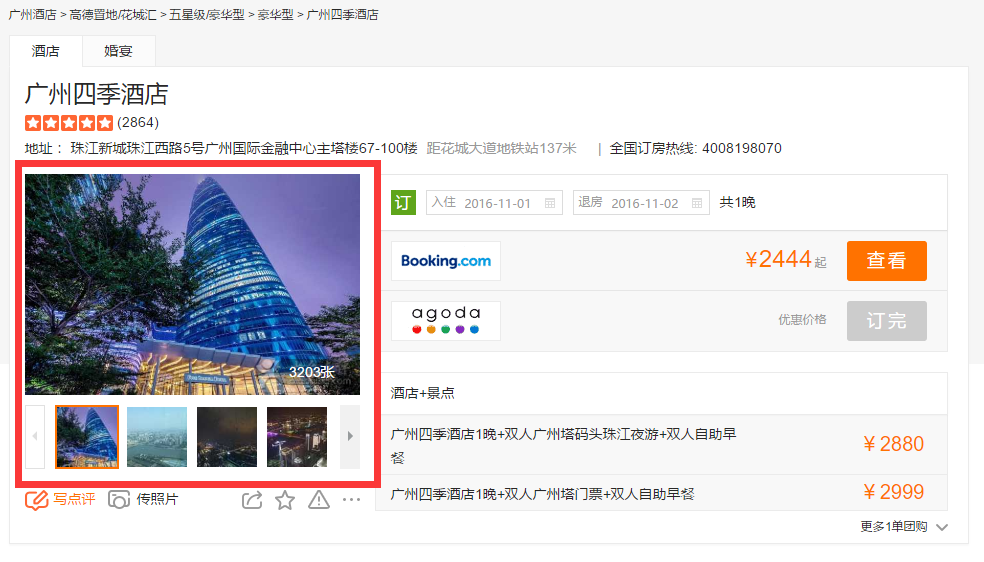
1.每个酒店的基本信息及酒店评论用户的基本信息
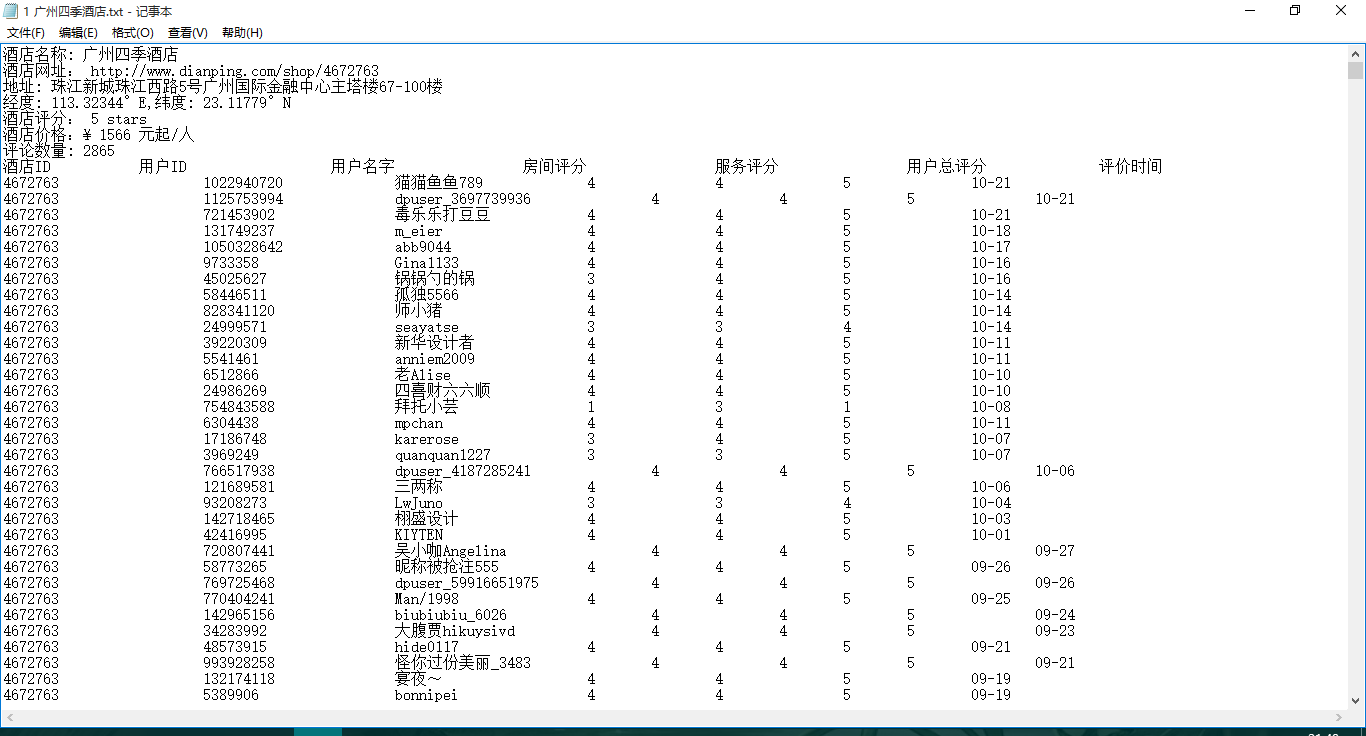
2.每个酒店的用户评论

3.每个酒店的图片

4.hotel文件夹下
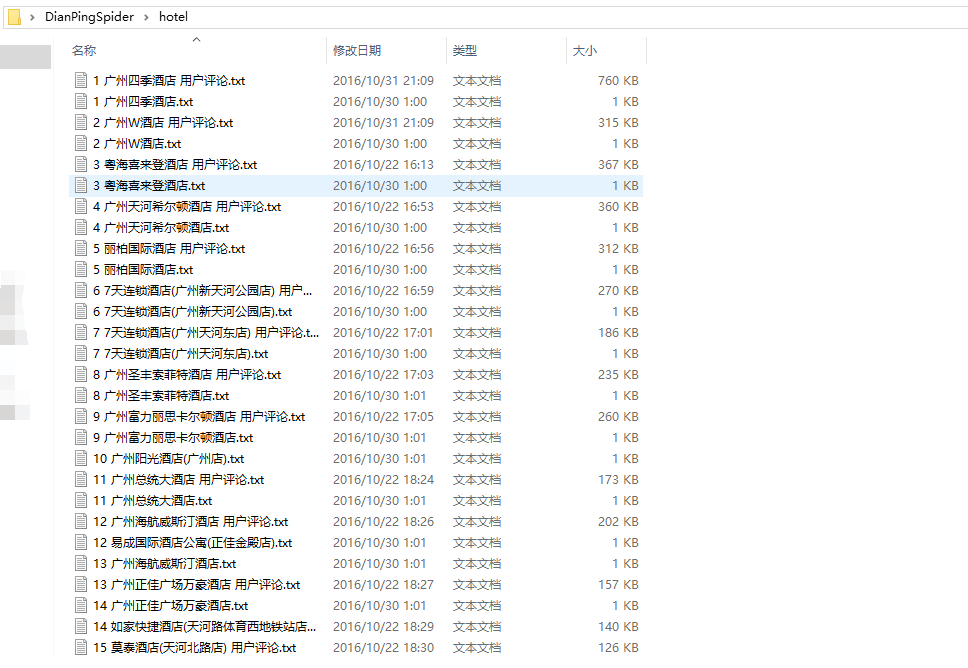
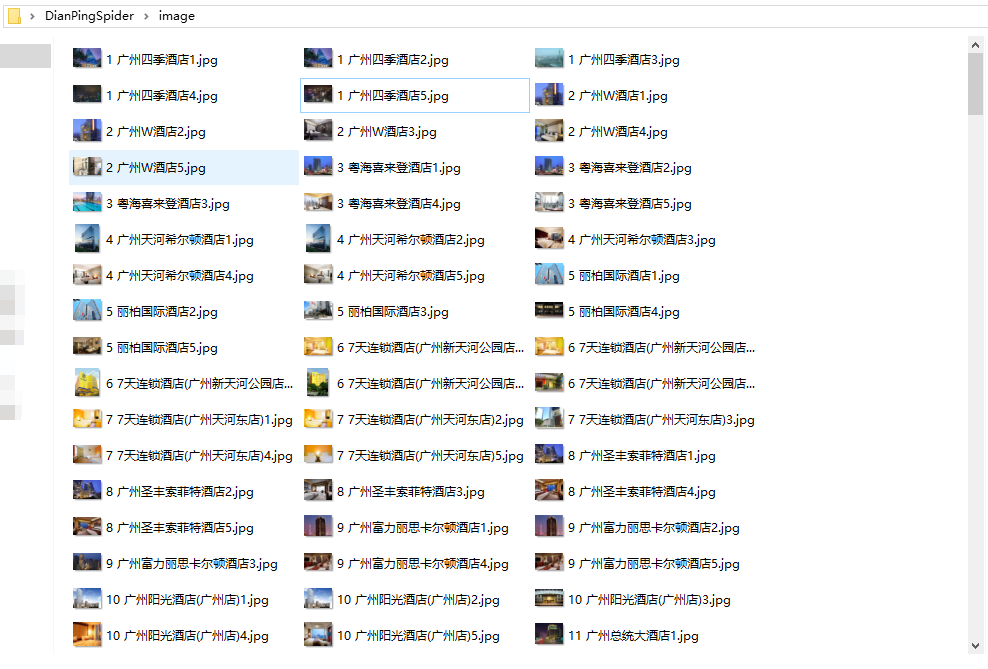
5.image文件夹下
本文仅献给那些想亲自快速实现网页爬虫的人类,对于大神来说本文不适合,对于搞研究的也不适合。因为本文仅适合“实现”而不是适合“讲原理”。十分感谢大家阅读这篇有点杂乱无章的笔记















 3392
3392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









