







原文出自:http://hxraid.javaeye.com/blog/646300
们首先总结一下《排序结构专题1-4》中的十种方法的性能((N个关键字的待排序列)):

1、 O(N^2) 级别的普通排序算法,我们用C++ 的随机函数rand() 产生的随机数进行排序,并计算耗费时间。
其中分别随机生成1W,3W,5W... 19W(增量为2W)共十组待排序列进行测试。得到直接插入排序、折半插入排序、起泡排序、简单选择排序的耗时统计图如下所示(SPSS软件做图统计)。

从上图可以发现,起泡排序的耗时最大,其他三者的耗时差不多。其中折半插入排序在待排数据量达到19W以后,其性能要比直接插入排序,和简单排序要好一些。另外,在数据量较小的情况下,插入排序的性能要比选择排序要略好。
普通算法分析:在数据规模较小时(9W之内),折半插入、直接插入、简单选择插入差不多。当数据量较大时,折半插入要好一些。而起泡排序算法的时间代价是最昂贵的。 另外,普通排序算法基本上都是相邻元素进行比较,因此O(N^2)基本的排序算法都是稳定的。
2、O(N*logN) 级别的先进排序算法,其时间复杂度要比普通算法要快得多。由于数据本身要小的多,因此我们没有拿它们和普通算法进行比较,而是另外选择从10W——140W(增量10W)的15组数据进行测试,耗时性能比较如下(SPSS软件做图统计):
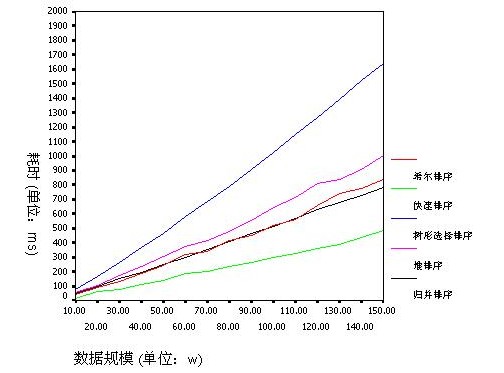
从上图可以发现,先进排序的耗时代价远远小于普通排序算法。而先进算法之间也有区别。其中快速排序无疑是最优秀的。其次是归并排序和希尔排序,堆排序稍微差一些,而最差的就是树形选择排序了。
先进算法分析:
(1) 就时间性能而言, 希尔排序、快速排序、树形选择排序、堆排序和归并排序都是较为先进的排序方法。耗时远小于O(N^2)级别的算法。
(2) 先进算法之中,快排的效率是最高的。 但其缺点十分明显:在待排序列基本有序的情况下,会蜕化成起泡排序,时间复杂度接近 O(N^2)。
(3) 希尔排序的性能让人有点意外,这种增量插入排序的高效性完全说明了:在基本有序序列中,直接插入排序绝对能达到令人吃惊的效率。但是希尔排序对增量的选择标准依然没有较为满意的答案,要知道增量的选取直接影响排序的效率。
(4) 归并排序的效率非常不错,在数据规模较大的情况下,它比希尔排序和堆排序都要好。
(5)堆排序在数据规模较小的情况下还是表现不错的,但是随着规模的增大,时间代价也开始和上面两种排序拉开的距离。
(6)树形选择排序并不是较好的先进排序方法,数据规模越大,其耗时代价越高。而且它所需要的额外辅助空间较多,达到O(N)级别。想想看,排序140W数据,需要额外再开辟140W的空间,实在是无法忍受。
(7) 多数先进排序都因为跳跃式的比较,降低了比较次数,但是也牺牲了排序的稳定性。
总的来说,并不存在“最佳”的排序算法。必须针对待排序列自身的特点来选择“良好”的算法。下面有一些指导性的意见:
(1) 数据规模很小,而且待排序列基本有序的情况下,选择直接插入排序绝对是上策。不要小看它O(N^2)级别。
(2) 数据规模不是很大,完全可以使用内存空间。而且待排序列杂乱无序(越乱越开心),快排永远是不错的选择,当然付出log(N)的额外空间是值得的。
(3) 海量级别的数据,必须按块存放在外存(磁盘)中。此时的归并排序是一个比较优秀的算法。
附:以上两个图的数据测试在Pentium 4 CPU 3.06GHZ下,CPU占用率0%的情况下运行的结果。 另外,下面是我测试九种排序算法的C源代码,可供大家下载使用。
★ 一个关于O(N*logN)耗时下限的理论
这里有一个疑问:是不是O(N*logN)是排序算法时间代价最好的极限呢?
当然不是,但是如果排序算法是基于"关键字比较"操作的,那么在最坏情况下确实能够到达的最好效果就是O(N*logN)了。 在最好情况下就没必要说了,如果待排序列基本有序,那么直接插入排序的比较次数都非常的少。
下面我们来证明一下(注意:这些排序算法的基本操作就是比较,其时间主要消耗在比较次数上)。现在有三个关键字K1、K2、K3。那么下图给出了这三个关键字记录在任何可能的排序状态下的判定树,树中的内部结点都进行了一次必要的比较。

三个关键字的待排序列只有上面叶子结点所描述的6中排序状态。而判定树上的每一次比较都是必须的。因此、这个判定树足以描述通过“比较”进行的排序过程。并且,每一个待排序列经过排序达到有序序列所需要进行的"比较"次数,恰为从树根到叶子结点的路径长度。因此3个关键字的比较最少需要2次,最多需要3次。
扩展一下,有N个关键字序列。那么就有N!种排序状态,自然判定树就有N!个叶子节点。我们知道,二叉树的树高为h的情况下,叶子结点最多有2^(h-1)个。而现在又N!个叶子结点,那么树高至少为log(N!)+1。也就是说,描述N个记录排序的判定树必存在一条长度为[log(N!)+1]的路径。根据斯特林公式(n!的高精度近似求解公式): log(N!)=N*log(N)。因此,最少的比较次数也就是N*log(N)了。
基于比较操作的排序算法的时间复杂度下限确实是O(N*logN)。那么如果不比较呢,耗时代价会不会进一步减少。当然,关于这方面的排序算法,请见《桶排序 》、《基数排序 》。















 295
295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









