




 本文深入探讨了二叉搜索树(BST)的基本概念、实现细节及其关键操作,包括查找、插入、删除等,并分析了BST的性能特点及应用场景。
本文深入探讨了二叉搜索树(BST)的基本概念、实现细节及其关键操作,包括查找、插入、删除等,并分析了BST的性能特点及应用场景。
符号表
符号表就是键值对的集合,并且支持put和get操作。现实中符号表的应用非常广泛,所以这里介绍几种键值对的实现,主要是二叉查找树以及之后将要介绍的红黑树。
一个值得注意的点就是,符号表里面不允许重复的key,也就是put一个键值对时,会先查找符号表里面是否含有这个key,有的话就更改这个key对应的值,没有的话就新加一个键值对
两种简单实现:
(1)使用无序链表的顺序查找
我们维护一个无序链表,当我们查找时,需要从头遍历链表,记着,key是不重复的,所以一旦我们找到了一个相符合的key,就可以返回了,所以易知平均的查找时间成本为Θ(N/2)最坏为N。对于插入,未命中的查找和插入都需要N次,命中的查找在最坏条件下需要N次。所以这个实现是很慢的。
(2)使用有序数组的二分查找
将key[]数组进行排序,使用的时候可以用二分查找在对数时间内找到需要查找的key。而插入操作也是需要先查找,查找到的话就更新元素,否则就插入新元素,但是这个操作需要移动插入位置之后的所有元素,因此插入操作总体上还是线性的
二叉搜索树(BST)
下面主要介绍二叉搜索树,它既是一种比较高效的实现符号表的结构也是下面理解红黑树的重要步骤。
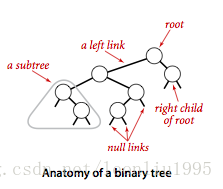
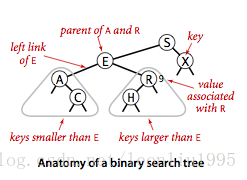
二叉搜索树:首先它是一棵二叉树(每个节点有两个子节点),每个节点的键(key)都是Comparable的,对于每一个节点,它的左子树的节点都小于该节点,右子树都大于该节点。
对于每个叶节点,它的子节点链接都是空的。
基本实现
Node对象
我们将Node定义为一个内部类,首先包含key 和value ,下面代码中的Key 和Value代表泛型。还包含左右两个子节点的引用,以及节点数N。
private class Node{
private Key key;
private Value value;
private Node left, right;
private int N;
//N为该节点及以下节点的节点数。
public Node(Key key, Value value, int N) {
this.key = key;
this.value = value;
this.N = N;
}
}查找get()
对于一个已经有序的BST,首先要记得在整个类中有个root引用指向根节点。那么在我们查找某个key的时候,先和根节点比较,如果key比root小那么就在左子树中继续查找,否则就在右子树中继续查找,如果key命中就直接返回。对于子树,我们可以递归地应用上面的方法,不断比较并决定在哪个子树中查找,直到命中或者查找到叶节点的空连接。
下面的代码使用了递归,以后的其他方法都大量的使用了递归。
public Value get(Key key){
return get(root, key);
}
private Value get(Node x, Key key){
if (x==null) return null;
int cmp = key.compareTo(x.key);
if (cmp<0) return get(x.left, key);
else if (cmp>0) return get(x.right, key);
else return x.value;
}插入put()
插入本质上和查找差不多,我们不断地进行查找,如果查找到了就更改这个节点的value值,如果查找不到,此时应该是查找到了一个空节点,那么就在这个节点插入新的节点。
public void put (Key key, Value val){
root = put(root,key, val);
}
private Node put(Node x, Key key, Value value){
if (x==null) return new Node(key, value, 1);
int cmp=key.compareTo(x.key);
if (cmp<0) x.left = put(x.left, key, value);
else if (cmp>0) x.right = put(x.right, key, value);
else x.value = value;
x.N = size(x.left)+size(x.right)+1;
return x;
}下面我们来仔细分析这个代码。第一个public的put是提供对外接口的,从而能够将下面的具体实现封装起来。在看下面的函数,里面的几个比较语句和get()里面很像。但是有一点不同,就是出现了x.left = put(x.left, key, value)这种语句,而不是查找中的return get(x.left, key)。根据我的理解,因为查找本身不会对数据结构产生影响,我们仅仅是从根节点往下查找,不断递归这个过程,当条件满足时直接返回。而put()更像是对整个树的一种变换,我们不断地对比较过的子树应用这个变换,直到查找到这个key或者查找到空节点,然后我们就可以返回,返回的过程是沿着来时的路径完全的返回。这里需要注意,对于空节点,put函数返回了一个新的Node,并且N为1,然后把它的引用赋值给了它的父节点,然后会返回父节点。之后的向上的过程对于节点本身并没有影响,主要是可以在put()不断返回时不断更新N,x.N = size(x.left)+size(x.right)+1;这个语句就是起到这个作用,因为是从刚更新的节点不断走上来的,所以最后的访问过的节点的N值肯定都被正确的更新了。
删除最小值和删除
删除最小值时需要不断沿着左子树往下走,因为整个树的最小值一定在最左边。所以如果找到一个结点,它的左节点的左节点为空,那么将该节点的右子树赋值给父节点左链接,这样就达到删除的效果,并且更新了最小值。
public void delMin(){
root = delMin(root);
}
private Node delMin(Node x){
if (x.left == null) return x.right;
x.left = delMin(x.left);
x.N = size(x.left)+size(x.right)+1;
return x;
}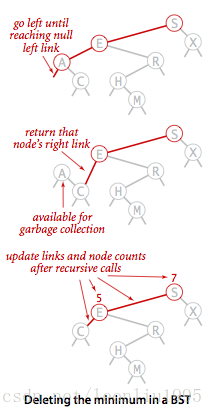
我们观察上面这个图,当往左运行到点A的时候,A的左节点为空,if (x.left == null) return x.right;这个语句返回A的左子树也就是节点C,再回到上一个函数,x.left = delMin(x.left);就把C的引用赋值给了E的左链接,这样删除掉了A同时剩下的树也是有序的。之后就开始不断运行递归语句后面的语句,也就是x.N = size(x.left)+size(x.right)+1;,这会从节点E开始不断更新节点的N值,当返回根节点时,程序运行完毕。
删除某一个值需要借用delMin()函数。这里用到的删除方法叫做Hibbard方法。具体思想是当我们查找到一个非叶节点的节点时,在下图中即为点E,我们要先把E节点的值赋值为他的右子树的最小值,这里即为H,然后对右子树使用delMin(),也就是删除这个最小值,接着把E节点的左子树赋值给这个新的节点H。最后向上返回的时候,把H的引用赋值给S这样点E就最终被删除了,新得到的树整体上也是有序的。
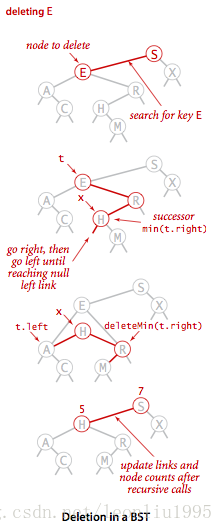
public void delete(Key key){
root = delete(root,key);
}
private Node delete(Node x, Key key){
if (x==null) return null;//找不到的情况
int cmp = key.compareTo(x.key);
if (cmp<0) x.left = delete(x.left, key);
else if (cmp>0) x.right = delete(x.right, key);
else {
if (x.right==null) return x.left;//寻找的节点正好是叶节点
if (x.left==null) return x.right;
Node t = x;
x = min(t.right);//找到右子树的最小值,并删除最小值
x.right = delMin(t.right);
x.left = t.left;
}
x.N = size(x.left)+size(x.left)+1;//更新节点的N值
return x;
}其他方法
最值
寻找最值很简单,就是不断递归,最小值在最左边,最大值在最右边。
public Key min(){
return min(root).key;
}
private Node min(Node x){
if (x.left==null) return x;
return min(x.left);
}
public Key max(){
return max(root).key;
}
private Node max(Node x){
if (x.right==null) return x;
return max(x.right);
}向下取整
首先向下取整函数floor(key)得到的结果一定是小于等于key的,所以我们首先和BST的根节点进行比较,如果小于根节点,那么floor(key)一定在左子树中,所以继续在左子树中查找,如果key大于等于根节点,那么有两种情况,一种是在右子树中查找到了,那么就可以返回这个结果,如果没有查找到,那么就返回根节点。
public Key floor(Key key){
Node x = floor(root, key);
if (x==null) return null;
return x.key;
}
private Node floor(Node x, Key key){
if (x==null) return null;
int cmp=key.compareTo(x.key);
if (cmp==0) return x;
if (cmp<0) return floor(x.left,key);
Node t = floor(x.right, key);
if (t!=null) return t;
else return x;
}代码的实现基本是按照上面提出的思路来的,对于floor(key),该节点的右子树肯定都是大于它的,那么floor()函数会不断的在左子树上递归,直到找到空节点,然后返回null,这个null不断往上抛,对于floor(key)这个节点来说,t为null,于是就会把floor(key)返回,接着这个值就会被最终抛出去。
同样的向上取整函数ceiling()原理类似,把right和left互换即可。
范围查找
范围查找就是查找落在(lo, hi )之间的key,同时返回一个Iterable对象,在这里我们使用队列Queue,当我们把lo ,hi分别换成min() ,max()之后就可以对整个树进行遍历。
public Iterable<Key> keys(){
return keys(min(), max());
}
public Iterable<Key> keys(Key lo, Key hi){
Queue<Key> queue = new Queue<Key>();
keys(root ,queue, lo, hi);
return queue;
}
private void keys(Node x, Queue<Key> queue, Key lo, Key hi){
if (x==null) return ;
int cmplo = lo.compareTo(x.key);
int cmphi = hi.compareTo(x.key);
if (cmplo<0) keys(x.left,queue, lo,hi);
if (cmplo<=0 && cmphi>=0) queue.enqueue(x.key);
if (cmphi >=0) keys(x.right, queue, lo,hi);
我们来看具体的代码,前两个是public的函数,不带参数的可以遍历整个树,带参数的可以查找出一定范围内的节点。private的函数是将Node x 及其子树中在范围(lo, hi )中的节点都加入队列queue中。其中第一行是递归的终点。几个if语句中if (cmplo<0) keys(x.left,queue, lo,hi);这句话相当于不断地往左遍历直到最小值的左节点返回null,或者超出(lo,hi )的范围,然后执行下一句。如果在范围内,就enqueue,这个值显而易见是整个树在(lo,hi)范围内最小的,然后再右子树中继续递归,找到的是右子树中最小的,也是整个树在(lo,hi)范围内第二小的,如此进行下去,我们发现这个顺序其实是升序的。
其他
其他还有一些函数,比如select()函数,找到从左至右排名为K的键,以及rank()函数,找到键key 的排名。
分析
BST理想情况下性能是非常好的,但是他有一个比较大的缺点就是容易受到键被插入顺序的影响。BST的性能受到树的形状也就是高度的影响,最坏的情况是键是按照有序的方式插入的
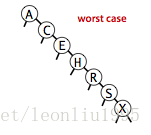
那么此时BST就和一个链表没有什么区别了,这时查找和插入的成本都是
总结
在一棵二叉树中,所有操作在最坏条件下所需的时间都和树的高度成正比
但是BST的树本身受输入的影响太大,并且自己不能调节,所以树本身可能非常不平衡,有的子树非常长有的很短。所以我们希望有一个数据结构,这个数到每一个叶节点都一样长,在下一篇就会有一个这样的数据结构——2-3查找树,以及它的具体实现——红黑树,红黑树的一个重要特征就是每个叶节点到根节点的黑连接数目是一样的,这样树本身的平衡性就有了很大的保障。

















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









