









符号表(3)——二叉查找树
本系列文章主要介绍常用的算法和数据结构的知识,记录的是《Algorithms I/II》课程的内容,采用的是“算法(第4版)”这本红宝书作为学习教材的,语言是java。这本书的名气我不用多说吧?豆瓣评分9.4,我自己也认为是极好的学习算法的书籍。
通过这系列文章,可以加深对数据结构和基本算法的理解(个人认为比学校讲的清晰多了),并加深对java的理解。
1 二叉查找树
二叉查找树是一个对称有序的二叉树
即:
每个节点有key,有2个孩子,左孩子的key小于自己的key,右孩子的key大于自己的key。(和堆不一样)
/1463215799595.png)
1.1 代码框架
我们可以根据定义设计出一个如下的二叉查找树基本框架,然后去完善它
public class BST<Key extends Comparable<Key>, Value>
{
private Node root;
private class Node{}
public void put(Key key, Value val){}
public Value get(Key key){}
public void delete(Key key){}
public Iterable<Key> iterator(){}
}1.2 节点表示
作为二叉查找树的节点,它应该包含键-值,还有左右孩子
private class Node {
private Key key;
private Value val;
private Node left, right;
public Node(Key key, Value val) {
this.key = key;
this.val = val;
}
}1.3 取得操作
根据二叉树的性质,可以从root开始搜索:
- 如果 小于 ,左孩子
- 如果 大于,右孩子
- 如果找到,返回
- 如果为null,则取得失败
public Value get(Key key)
{
Node x = root;
while(x != null)
{
int cmp = key.compareTo(x.key);
if(cmp < 0)
x = x.left;
else if(cmp > 0)
x = x.right;
else if(cmp == 0)
return x.val;
}
return null;
}1.4 插入操作
插入操作可以用递归来做。(凡是涉及链表的插入操作,都可以考虑用递归,用非递归相对来说麻烦点,因为插入操作是在父亲节点上插入一个左右孩子,如果root为空还得单独判断)
不断的递归搜索左右孩子,直到找到一个null节点,就把新<键,值>插入。如果键本身在树中,则更新值。
/1463217008582.png)
这里比较巧妙的是:root = put(root, key, val);
把root也结合进去了。
public void put(Key key, Value val) {
root = put(root, key, val);
}
private Node put(Node x, Key key, Value val) {
if (x == null) {
return new Node(key, val);
}
int cmp = key.compareTo(x.key);
if (cmp < 0) {
x.left = put(x.left, key, val);
} else if (cmp > 0) {
x.right = put(x.right, key, val);
} else if (cmp == 0) {
x.val = val;
}
return x;
}也可以使用非递归的代码:
public void put(Key key,Value val)
{
Node x = root;
if(x == null)
x = new Node(key,val);
while(true)
{
int cmp = key.compareTo(x.key);
if(cmp < 0)
{
if(x.left != null)
x = x.left;
x.left = new Node(key,val);
return ;
}
if(cmp > 0)
{
if(x.right != null)
x = x.right;
x.right = new Node(key,val);
return ;
}
if(cmp == 0){
x.val = val;
return ;
}
}
}1.5 动画演示
动画演示查找和插入
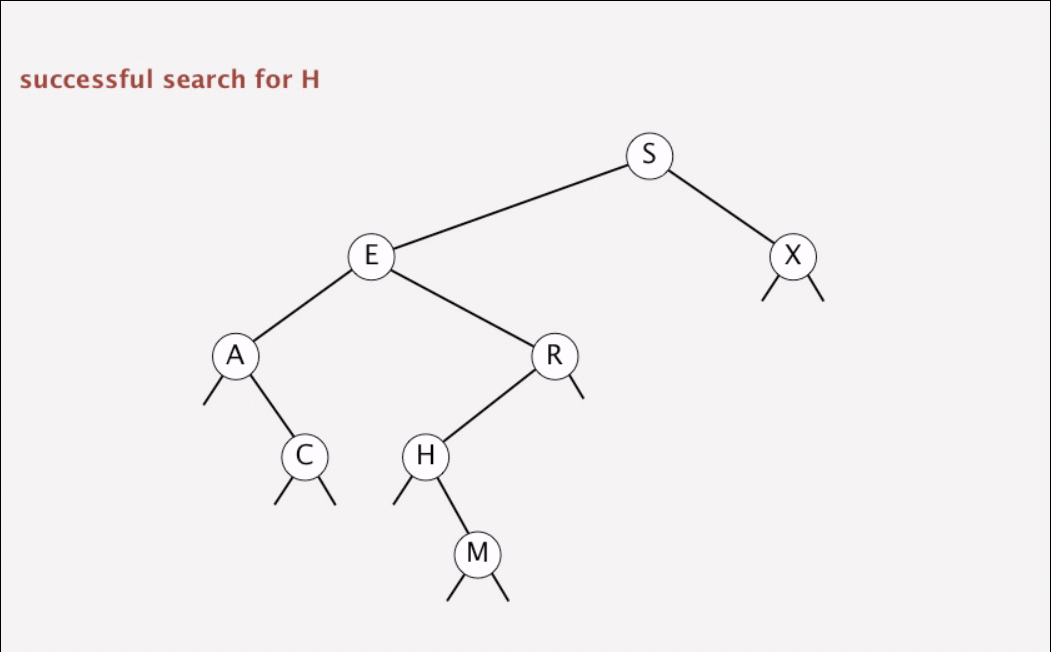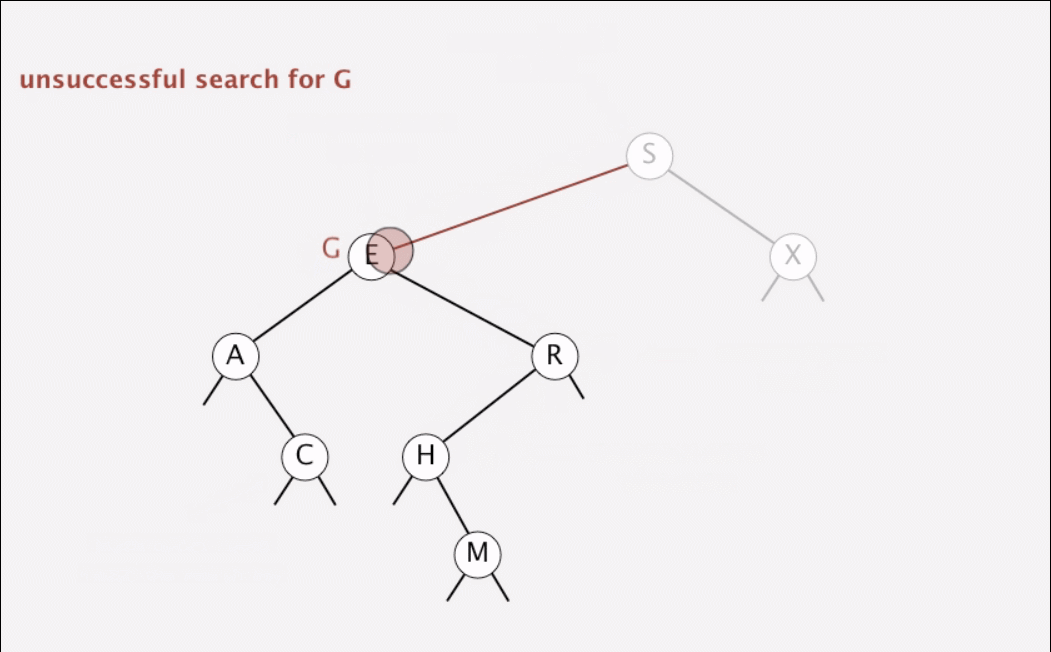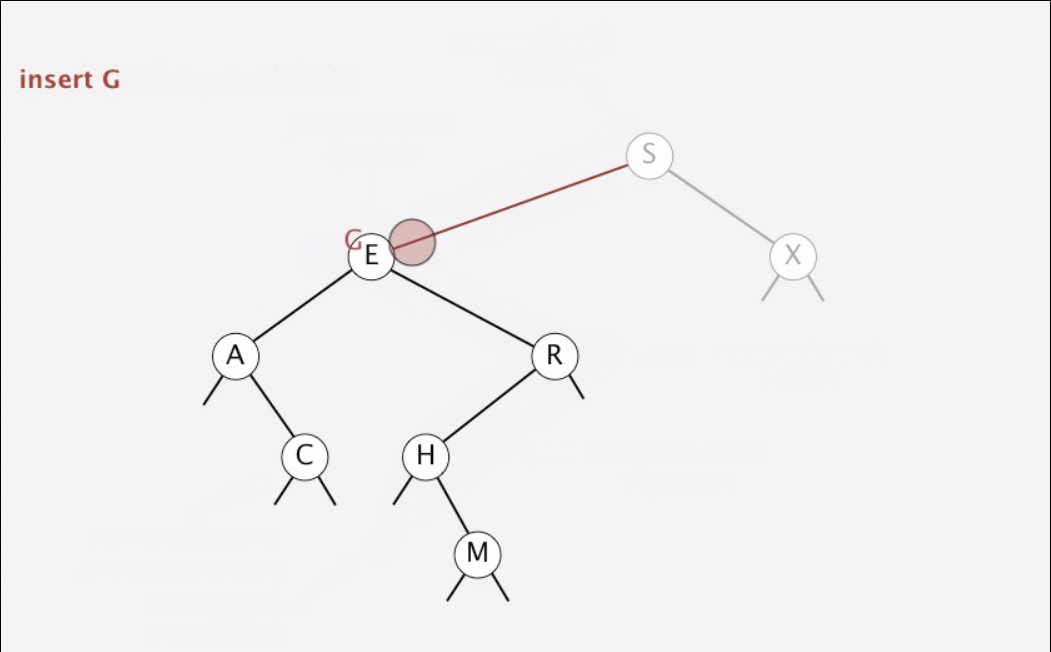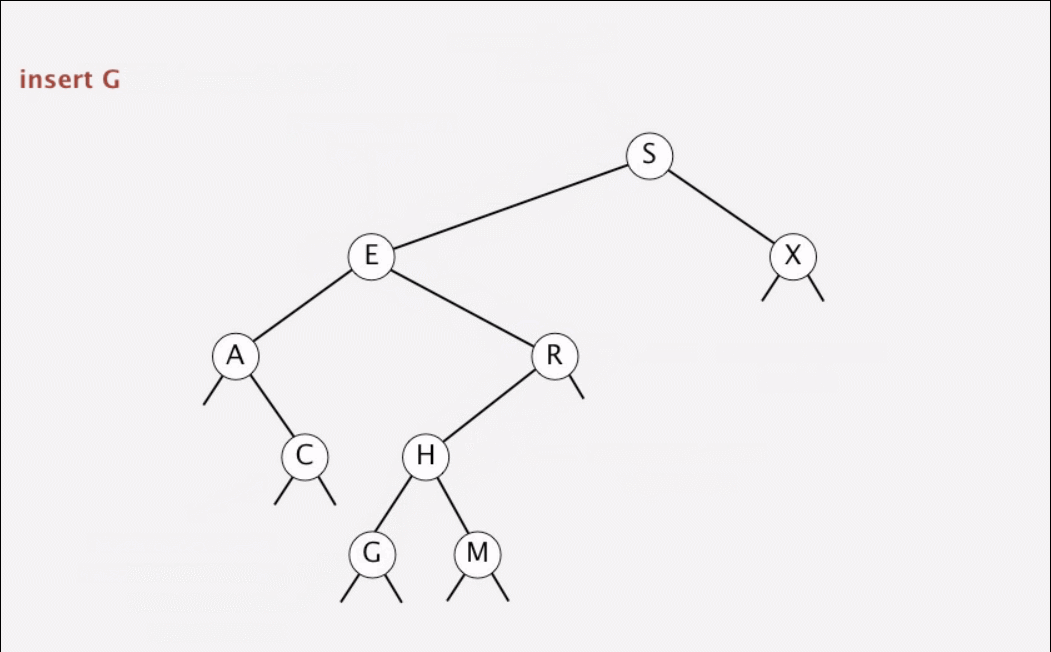
1.6 二叉树的形状
根据不同的插入顺序,二叉树会呈现出不同的形状,最好的状态当然是完全平衡的状态,这个时候搜索效率最高,最坏的形式就是插入的序列有序,这个时候二叉树的搜索效率就是N了。
/1463217037569.png)
我们看看随机插入的效果:
/2.gif)
研究表明,二叉树的平均深度都不深,如果插入是随机的情况下。所以通常情况下,二叉树的效率还是很高的。
/1463218554853.png)
/1463218535706.png)
2. 有序操作
2.1 最大最小
这个很简单,最大的话直接搜索到最右的孩子
最小的话直接搜索到最左的孩子
/1463218515735.png)
2.2 floor和ceiling
floor:找到比key小的最大key
ceiling:找到比key大的最小key
/1463219191566.png)
2.2.1 floor操作:(递归操作)
由于floor操作是找比key小的最大key,这个概念看起来特别绕,所以必须要理清楚。
- 条件一:首先前提条件是比给定的Key小
- 条件二:然后再在这些小值中找最大的一个。
我们先考虑如果给定你一个节点,如何找它的floor值??很明显,它的左子树(条件1)的最右节点(条件2),所以下面的思路也是这样的,先满足条件1,再满足条件2.
- 如果k ==
root.key
floor=root.key - 如果k <
root.key在左子树继续查找(杂没比我小的)
- 如果k >
root.key记录root(终于找到一个比我小的了,赶紧记下来)
- 如果
右边子树遇到一个小于k的,就继续(看还有么有更大的小值) - 否则,就是
root(看来没有比你大的了)
- 如果
- 如果k >
public Key floor(Key key)
{
Node x = floor(root,key);
if(x == null) return null;
return x.key;
}
private Node floor(Node x,Key key)
{
if(x == null) return x;
int cmp = key.compareTo(x.key);
if (cmp < 0) return floor(x.left, key);
if (cmp == 0) return x;
Node f = floor(x.right, key);
if (f == null)
return x;
else
return f;
}/1463218614300.png)
2.2.2 ceiling操作:(递归操作)
和floor操作相反
- 如果k ==
root.key
floor=root.key - 如果k >
root.key在右子树继续查找(杂没比我大的?)
- 如果k <
root.key记录root(终于找到一个比我大的了,赶紧记下来)
- 如果
左边子树遇到一个大于k的,就继续(看还有么有更小的大值) - 否则,就是
root(看来没有比你小的了)
- 如果
- 如果k <
public Key ceil(Key key) {
Node x = ceil(root, key);
if (x == null) {
return null;
}
return x.key;
}
private Node ceil(Node x, Key key) {
if (x == null) {
return x;
}
int cmp = key.compareTo(x.key);
if (cmp > 0) {
return ceil(x.right, key);
}
if (cmp == 0) {
return x;
}
Node f = ceil(x.left, key);
if (f == null) {
return x;
} else {
return f;
}
}2.3 子树统计
子树统计有很多应用的地方,我们经常需要查找比key小的有多少个,或者找第几大的元素,比如rank()操作,select()操作。
/1463219210698.png)
首先,我们需要在Node类中加入一个用来统计的变量count。并且修改size()和put函数,使得树在建立的时候,就使得count填充好。
private class Node
{
private Key key;
private Value val;
private Node left;
private Node right;
private int count; //加这里
} public int size()
{
return size(root);
}
private int size(Node x)
{
if (x == null) return 0;
return x.count; //加这里
} private Node put(Node x, Key key, Value val)
{
if (x == null) return new Node(key, val, 1);
int cmp = key.compareTo(x.key);
if (cmp < 0) x.left = put(x.left, key, val);
else if (cmp > 0) x.right = put(x.right, key, val);
else if (cmp == 0) x.val = val;
x.count = 1 + size(x.left) + size(x.right);//加这里
return x;
}2.4 rank()
rank的功能就是返回键小于key的个数。有三种情况:
- root == key
左孩子count(因为只有左孩子小于它) - root < key
左孩子count+1(自己)+ 右孩子继续找 - root > key
左孩子继续找(给定key还没找到比自己小的呢)
/1463219522881.png)
比如这个图中:
rank(S) = 6
rank(A) = 0 (左孩子为null)
rank(D) = 0+1+0+1 = 2 (1是A和C自己,0是A和C的左孩子)
public int rank(Key key)
{
return rank(root,key);
}
private int rank(Node x,Key key)
{
if(x == null) return 0;
int cmp = key.compareTo(x.key);
if(cmp > 0)
return 1 + size(x.left) + rank(x.right,key);
else if(cmp == 0)
return size(x.right);
return rank(x.left,key);
}2.5 有序遍历
根据二叉树的结构,很简单了:
- 遍历左孩子
- 把自己key插入队列
- 遍历右孩子
public Iterable<Key> keys()
{
Queue<Key> q = new Queue<Key>();
inorder(root, q);
return q;
}
private void inorder(Node x,Queue<Key> q)
{
if(x == null)
return ;
inorder(x.left, q);
q.enqueue(x.key);
inorder(x.right,q);
}3 总结
用二叉排序树实现的符号表操作,其时间复杂度要大大小于其他方式。
/1463219891133.png)
细心的小伙伴可能发现了,我们并没有讲删除操作,因为删除操作涉及的东西比较多,我们在后面单独讲它。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









