






集合篇:
List 是 Colllection 的直接子类,它是有序的,它能够准确的确定每个元素的具体位置,可以直接的通过索引获取元素。Collection 有迭代器 Iterator ,List也相应的有一个自己Iterator,那就是ListIterator,它也是继承自Iterator的。其次List和其他集合不同的是:List里面的元素是可以重复的,而Set的元素是不重复的,Map里面的Key也是不重复的。
下面来看看List都提供的那些方法,
直接跳过Clooection已有的,直接看看LIst特有的一些方法:
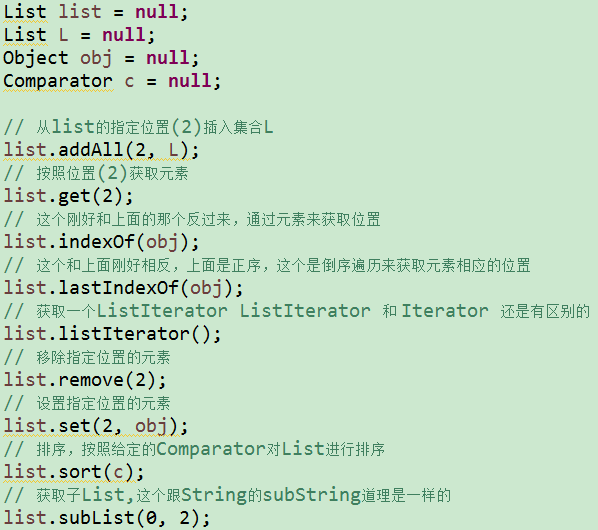
从上面这个代码中可以看到,List特有的方法中,几乎都是带有索引的,因为List是有序的,所以,集合中,带有索引的方法中,几乎都是List 特有的。
现在再来看看List 集合特有的Iterator-->ListIterator,ListIterator就不再上代码了。ListIterator 和 Iterator 基本相同,不同之处在于,ListIterator有一个hasNext() 方法相对应的,那就是hasPrevious()为什么Iterator没有,而ListIterator是有的,因为List是有序的。除了这个方法以外,还有两个特有的,nextIndex() 和 previousIndex(),这两个方法,一看方法名就一目了然了。
List最基本的已经说完就说说它实现的已知子类:ArrayList,LinkedList 和 Vector
ArrayList 底层的数据结构是数组,特点是查询快,增删慢。同时线程是异步的,也就是不安全的
LinkedList 底层的数据结构是链表,特点是查询慢,增删快。同时线程是异步的,也就是不安全的
Vector 底层的数据结构也是数组,线程是同步的,不管增删还是查询都比较慢。
了解完最基本的区别,现在来看看
ArrayList的底层的数据结构是数组,数组是定长的啊,所以,如果没有在初始化的时候指定ArrayList的长度,那么就会自动生成一个长度为10的数组,当添加第11个数据的时候,ArrayList会自动扩容。一次扩容50%,扩容的方式是在内存中先申请一个现有集合长度的150%长度的数组,然后把原来的数据复制到新的数组中,再销毁原数组。原理清楚了,ArrayList 的两个特点也就很好理解了,查询快,因为是数组,数组是直接根据索引进行查数据的(数组是申请一片内存,只要知道索引和每一个数据的大小,就能够算出相应的内存中的地址),所以ArrayList 查询速度快也就很好理解了,为什么增删会慢呢?也是因为它底层是数组,假如一个集合的长度是6,那么我现在要往第三位插入一个数据,那么,3456这三个是不是要依次往后挪,先把6往后挪一位,也就是7,然后是5,然后是4,最后是3,3移完后,3这个位置才会腾出来给新的数据插进去。删除也一样,例如我要删第3个数据,那么,就把3删掉后,456都要往前挪,所以,ArrayList在增加和删除的时候是比较耗时间的,需要移动的数据太多了。如果遇到不够大的时候,需要扩容,那就更慢了。最后说说,ArrayList 还有一个缺点是:会浪费内存,因为是数组,数组是定长的,如果没有用完,还有空缺的,那就浪费了。
LinkedList 的底层的数据结构是链表。链表就是一个一个节点组成的,节点除了存储数据以外,还存储着它上一个节点的地址和下一个节点的地址。这就是链表。链表为什么增删快呢?因为链表在增删的时候数据是不需要移动的,原来在哪就在哪?在内存中的位置是不变的,变得只是它存储的上一个节点的地址或者下一个节点的地址。假设现在有AB两个节点,A节点在前,B节点在后,那么,A节点的下一个节点的地址存储的是B节点的地址,B节点的上一个节点的地址存储的是A节点的地址,现在要往AB节点中间插入一个节点C,那么C节点插入的时候只需要把C节点的上一个节点的地址为A的地址,下一个的地址为B的地址,然后把A下一个的地址改为C的地址,B的上一个的地址改为C的地址,不用挪动数据,只需要改节点的地址就可以,相应的,删除也一样,删除只需要把要删除的节点的前一个节点和后一个的相应的地址就可以,例如有ABC三个节点,要删除B节点,只需要把A节点的下一个节点的地址改成C节点的地址,把C节点的上一个节点的地址改成A节点的地址。所以,链表的增删是比较快的,而为什么查找会比较慢呢?前面已经说过ArrayList的数据结构是数组,根据索引就可以算出相应元素存储的位置,而链表不一样,如果你需要找底3个节点,那么你就需要先通过第一个节点找到第二个节点,然后通过第二个节点找到第三个节点,所以,如过LinkedList在查找的时候,越靠后的查找越慢,(如果linkedList是从后面往前找的话就反过来)。
最后就是Vector,它和ArrayList的底层实现是一样的,最大的不同就是它是线程同步的,是安全的。同时也是因为线程同步,所以,它无论增删还是查找都是比较慢的。















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









