







 本文深入介绍了Python网络爬虫中Beautiful Soup库的使用,包括库的安装、基本元素、HTML内容遍历、格式输出以及信息提取方法。通过实际案例,详细讲解了如何利用Beautiful Soup进行HTML内容查找,同时探讨了HTML、JSON、YAML三种信息标记形式的比较,并展示了中国大学排名爬虫的编写与优化过程。
本文深入介绍了Python网络爬虫中Beautiful Soup库的使用,包括库的安装、基本元素、HTML内容遍历、格式输出以及信息提取方法。通过实际案例,详细讲解了如何利用Beautiful Soup进行HTML内容查找,同时探讨了HTML、JSON、YAML三种信息标记形式的比较,并展示了中国大学排名爬虫的编写与优化过程。
【第二周】 网络爬虫之提取
Beautiful Soup库入门
Beautiful Soup库的安装与测试
中文文档:Beautiful Soup 4.4.0 文档
安装方式:pip install beautifulsoup4
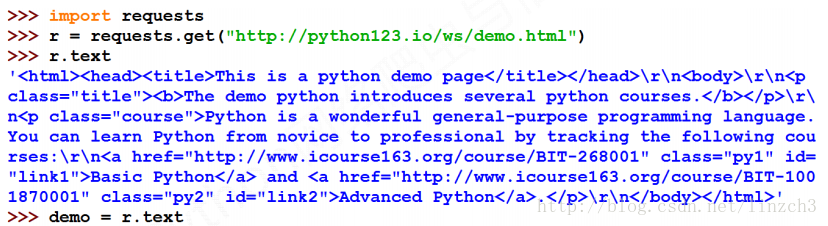
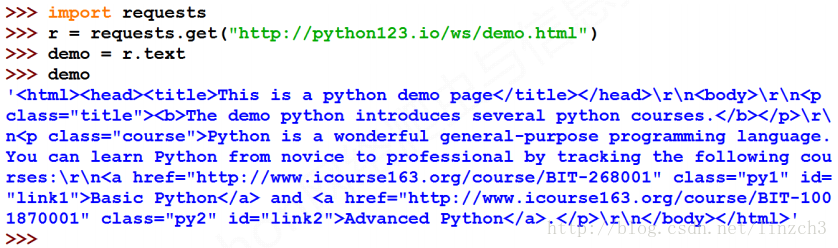
测试网站(http://python123.io/ws/demo.html)的源代码(当然用requests库获取便可):
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>
</body></html>测试代码和对应的部分输出:
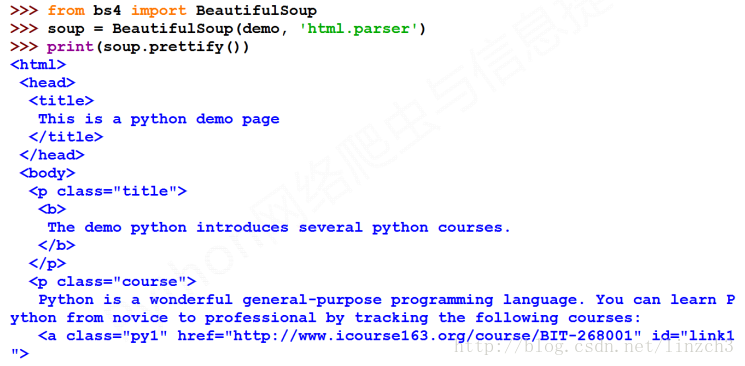
注: prettify函数的作用是:打印一下 soup 对象的内容,进行格式化输出,可以看到上面的该函数的输出的形式很适合我们直接阅读。另外,该函数使用得比较多,因此要多留意一下。更多的细节下面的“基于bs4库的HTML格式输出”章节。
常用使用方法:

Beautiful Soup库基本元素
Beautiful Soup库,也叫beautifulsoup4或 bs4,约定引用方式如下,即主要是用BeautifulSoup类:
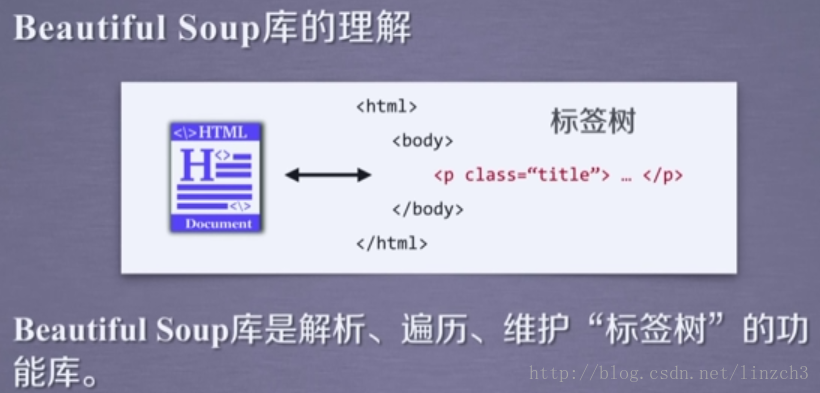
from bs4 import BeautifulSoup对库的理解:

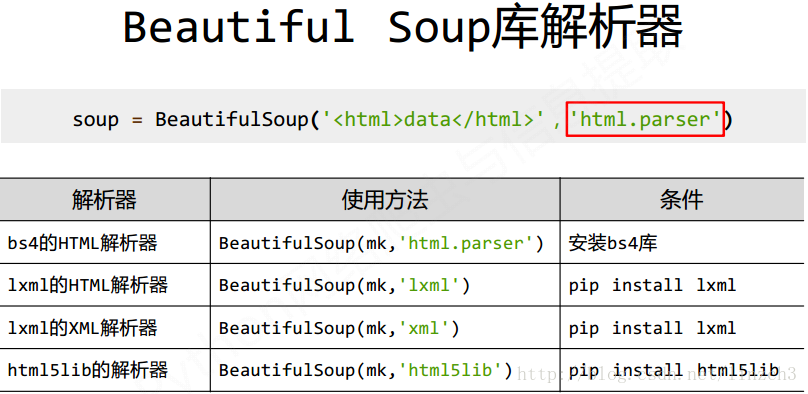
其他解析器:
对标签的理解:

对标签的进一步说明:

以之前的demo.html为例子:
在浏览器上显示为:
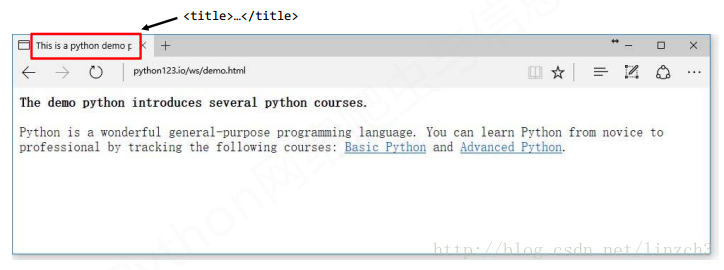
使用requests库爬取的效果:
具体分析demo的基本元素:

注意:
1.soup.a是指将soup中的名字为a的标签(在HMTL5中 代表 链接标签)提取出来
2.当HTML文档中存在多个相同对应内容时,soup.返回第一个
3.上面的tag的输出是将原先的tag的属性按照属性的字母序重新排列得到的。
原先的是:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> 输出的是:
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 254
254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









