







继上篇《Spark源码分析之Job的调度模型与运行反馈》之后,我们继续来看第二阶段--Stage划分。
Stage划分的大体流程如下图所示:
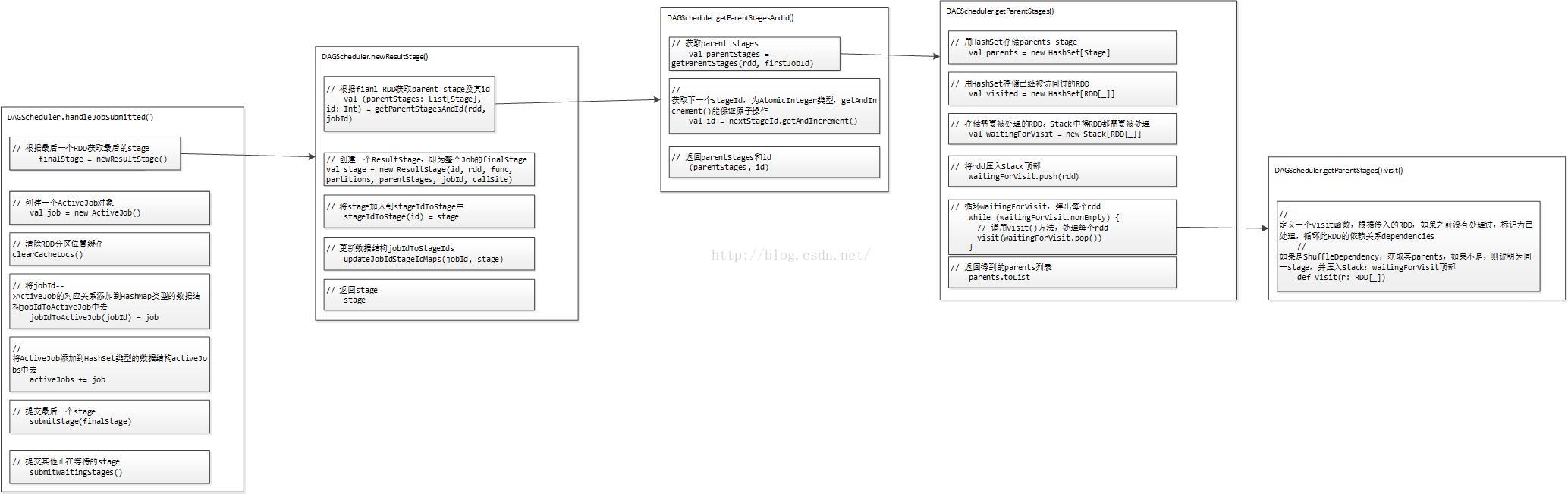
前面提到,对于JobSubmitted事件,我们通过调用DAGScheduler的handleJobSubmitted()方法来处理。那么我们先来看下代码:
// 处理Job提交的函数
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
// 利用最后一个RDD(finalRDD),创建最后的stage对象:finalStage
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
// 根据最后一个RDD获取最后的stage
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
// 创建一个ActiveJob对象
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
// 清除RDD分区位置缓存
// private val cacheLocs = new HashMap[Int, IndexedSeq[Seq[TaskLocation]]]
clearCacheLocs()
// 调用logInfo()方法记录日志信息
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
// 将jobId-->ActiveJob的对应关系添加到HashMap类型的数据结构jobIdToActiveJob中去
jobIdToActiveJob(jobId) = job
// 将ActiveJob添加到HashSet类型的数据结构activeJobs中去
activeJobs += job
finalStage.setActiveJob(job)
//2 获取stageIds列表
// jobIdToStageIds存储的是jobId--stageIds的对应关系
// stageIds为HashSet[Int]类型的
// jobIdToStageIds在上面newResultStage过程中已被处理
val stageIds = jobIdToStageIds(jobId).toArray
// stageIdToStage存储的是stageId-->Stage的对应关系
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
// 提交最后一个stage
submitStage(finalStage)
// 提交其他正在等待的stage
submitWaitingStages()
}第一,调用newResultStage()方法,生成Stage,包括最后一个Stage:ResultStage和前面的Parent Stage:ShuffleMapStage;
第二,创建一个ActiveJob对象job;
第三,清除RDD分区位置缓存;
第四,调用logInfo()方法记录日志信息;
第五,维护各种数据对应关系涉及到的数据结构:
(1)将jobId-->ActiveJob的对应关系添加到HashMap类型的数据结构jobIdToActiveJob中去;
(2)将ActiveJob添加到HashSet类型的数据结构activeJobs中去;
第六,提交Stage;
下面,除了提交Stage留在第三阶段外,我们挨个分析第二阶段的每一步。
首先是调用newResultStage()方法,生成Stage,包括最后一个Stage:ResultStage和前面的Parent Stage:ShuffleMapStage。代码如下:
/**
* Create a ResultStage associated with the provided jobId.
* 用提供的jobId 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









