







 本文深入探讨Spark中的Stage划分,当RDD触发action操作后,DAGScheduler根据lineage进行Stage划分。重点在于理解宽依赖和窄依赖如何决定Stage边界,例如在RDD G与RDD F之间的宽依赖导致它们被划入不同Stage,而RDD G与RDD B因窄依赖位于同一Stage。通过分析DAGScheduler的newResultStage、getParentStagesAndId、getParentStages及getShuffleMapStage等方法,揭示Stage划分过程。
本文深入探讨Spark中的Stage划分,当RDD触发action操作后,DAGScheduler根据lineage进行Stage划分。重点在于理解宽依赖和窄依赖如何决定Stage边界,例如在RDD G与RDD F之间的宽依赖导致它们被划入不同Stage,而RDD G与RDD B因窄依赖位于同一Stage。通过分析DAGScheduler的newResultStage、getParentStagesAndId、getParentStages及getShuffleMapStage等方法,揭示Stage划分过程。
本文要解决的问题:
由于近期重点需要研究Spark的调度优化问题,所以对这一块进行重点分析。
本文主要讨论Spark中Stage的划分。
当rdd触发action操作之后,会调用SparkContext的runJob方法,最后调用的DAGScheduler.handleJobSubmitted方法完成整个job的提交。然后DAGScheduler根据RDD的lineage进行Stage划分,再生成TaskSet,由TaskScheduler向集群申请资源,最终在Woker节点的Executor进程中执行Task。
我们首先看一下如何进行Stage划分。下图给出的是对应Spark应用程序代码生成的Stage。它的具体划分依据是根据RDD的依赖关系进行,在遇到宽依赖时将两个RDD划分为不同的Stage。

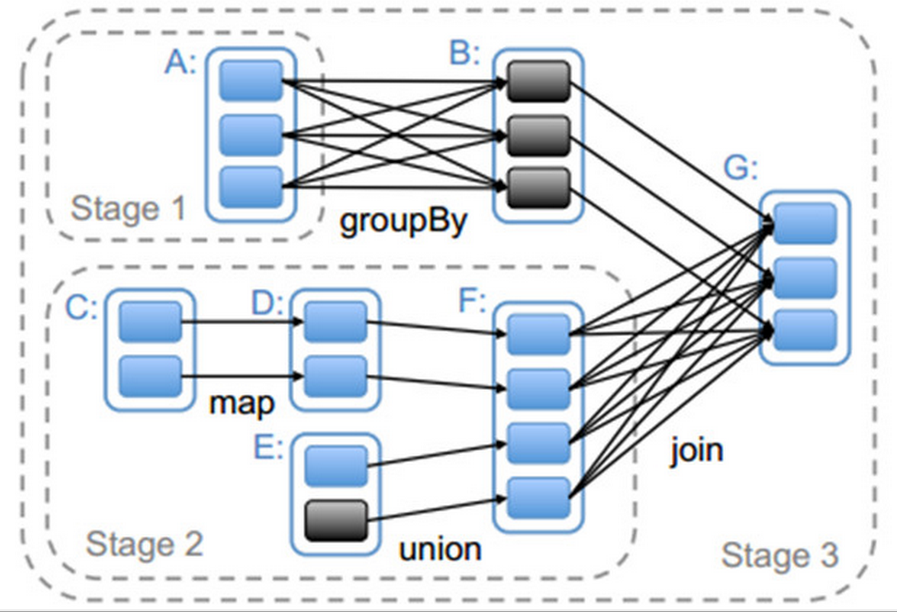
从上图中可以看到,RDD G与RDD F间的依赖是宽依赖,所以RDD F与 RDD G被划分为不同的Stage,而RDD G 与 RDD 间为窄依赖,因此 RDD B 与 RDD G被划分为同一个Stage。通过这种递归的调用方式,将所有RDD进行划分。
//DAGScheduler.handleJobSubmitted方法
//参数finalRDD为触发action操作时最后一个RDD
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
//finalStage表示最后一个Stage
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
//调用newResultStage创 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









