









一:分类的概念
分类是一种重要的数据分析形式,分类方法用于预测数据对象的离散类别,而预测则用于预测数据对象的连续取值;数据分类是两个阶段的过程,包括学习阶段和分类阶段;学习阶段(训练阶段)就是建立描述预先定义的数据类或概念集的分类器;而训练集是有数据库元祖和与他们相互关联的类标号组成;类标号属性是离散值和无序的,它是分类的,因为每个值充当一个类;提供个每个训练元祖的类标号,这一阶段也称为监督学习(及分类器的学习在被告知每个训练元祖属于哪个类的“监督”下进行的),无监督学习:每个训练元祖的类标号是未知的;过分拟合:如果用训练集来度量分类器的准确率,则评估结果可能是乐观的,因为分类器趋向于过分拟合该数据;而是要用检验集数据要度量分类器的准确率;
二:决策树分类算法
决策树就是一个类似流程图的树型结构,其中树的每个内部结点代表对一个属性(取值)的测试,其分支就代表测试的每个结果;而树的每个叶结点就代表一个类别。树的最高层结点就是根结点;
下面就用一个案例描述怎么创建一个决策树;下面图示是一个训练样本集合,以下训练集训练一个决策树分类器
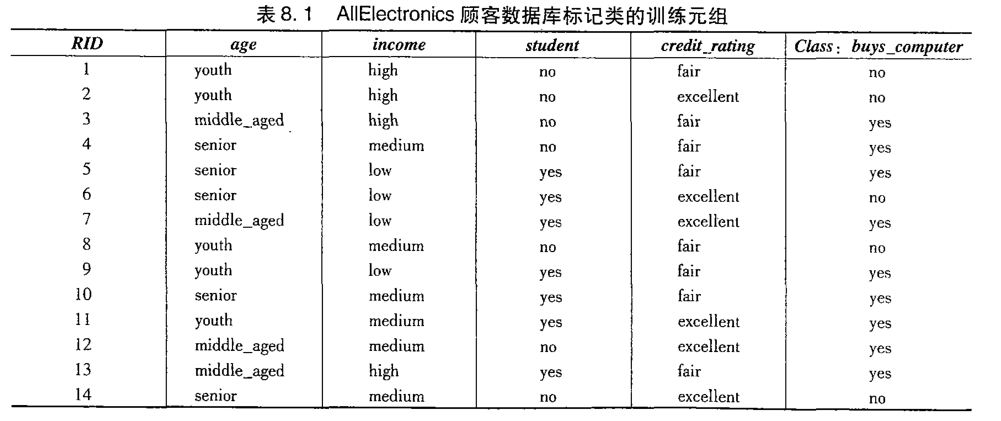
第一步:决策树开始时,作为一个单个结点(根结点)包含所有的训练样本集;
第二步:确定分裂属性;构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况:
1、属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2、属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3、属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
属性选择度量算法有很多,一般使用自顶向下递归分治法,并采用不回溯的贪心策略。这里介绍ID3和C4.5两种常用算法。
ID3使用信息增益作为属性选择度量,选择具有最高信息增益的属性作为节点N的分裂属性,该属性使结果跟去中对元祖分类锁需要的信息量最小,具体公式步骤如下;
A: 计算元祖分类所需要的期望信息,公式如下

设训练集中buys_computer =yes 为C1类,buys_computer = no 为C2类;|c1| = 9 ,|c2|=5;故可以算出 p1 = 9/15, p2=5/14,把p1和p2代入上面公式可得:
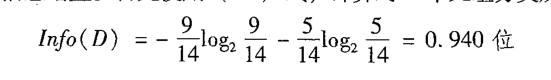
B: 计算每个属性的信息增益,属性的信息增益公式如下:
那先以age属性为例,先算INFOage(D),

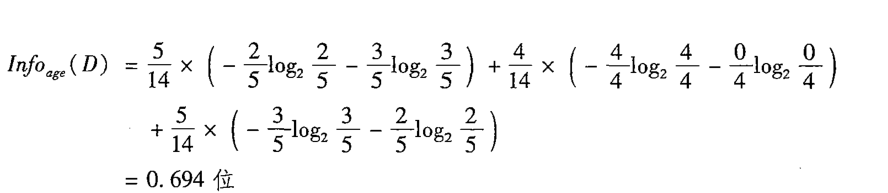

c4.5使用一种信息增益率作为分裂的标准;


















 2521
2521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









