







第三部分 数据结构
第11章 散列表
- 散列表是普通数组的推广
- 散列表查找元素的平均时间是O(1)
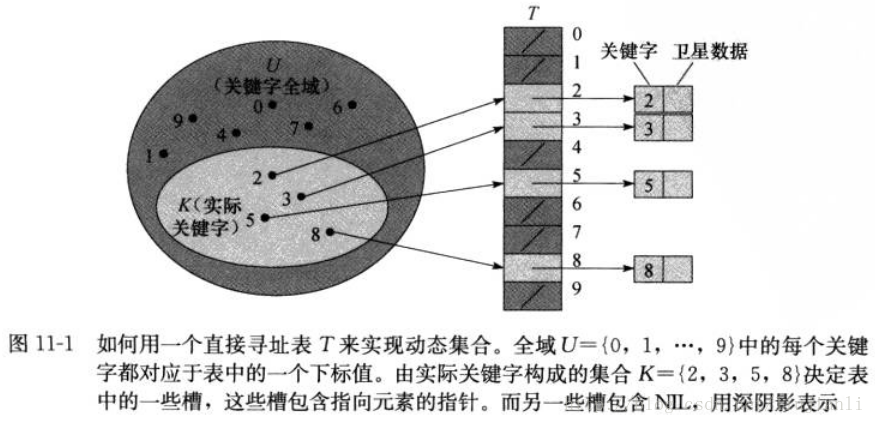
1. 直接寻址表
- 当关键字的全域U比较小时,直播寻址是一种简单而有效的技术
- 为表示动态集合,用一个数组称为直接寻址表,其中每个位置称为槽,对应全域U中的一个关键字
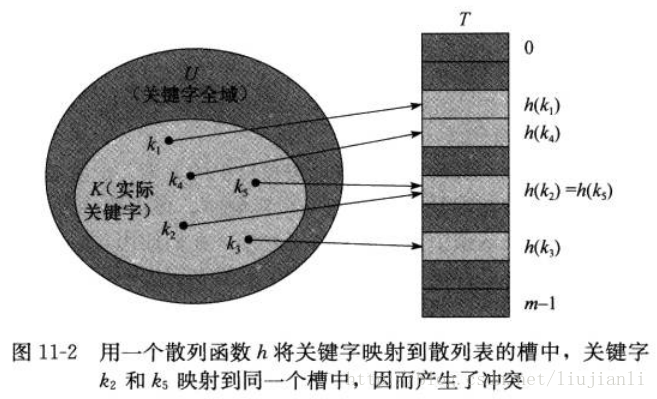
2. 散列表
- 散列函数,由关键字k计算出槽的位置,函数h将关键字的全域U映射到散列表的槽位上
- 两个关键字可能映射到同一个槽中,即冲突。最简单的冲突解决方法,称为链接法。把散列到同一槽中的所有元素都放在一个链表中
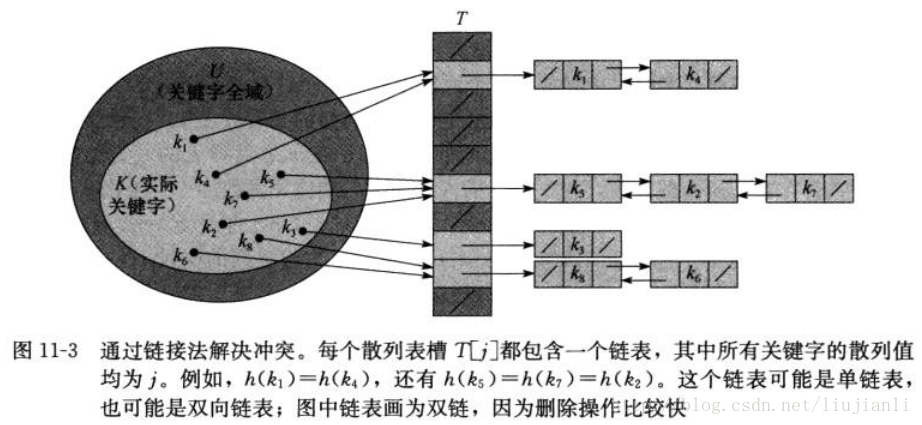
3. 散列函数
好的散列函数应满足:简单均匀散列假设,每个关键字都被等可能地散列到m个槽位中的任何一个,并与其他关键字已散列到哪个槽位无关
除法散列法
- 通过取k除以m的余数,将关键字k映射到m个槽中的某一个上,散列函数为:h(k) = k mod m
- 避免选择m的某些值。如,m不应为2的幂,因为如果m = 2 ^ p,则h(k)就是kr p个最低位数字
乘法散列表
- 第一步,用关键字k乘上常数A(0 < A < 1),并提取kA的小数部分
- 第二步,用m乘以这个值,再向下取整
- 散列函数为: h(k) = ⌊m(kA mod 1)⌋
- 优点:对m的选择不是特别关键,一般选择它为2的某个幂次(m = 2 ^ p,p为某个整数)
开放寻址法
- 为了使用该方法插入一个元素,需要连续地检查散列表,或称为探查。
- 探查分为
- 线性探查
- 二次探查
- 双重探查,是用于开放寻址法的最好方法之一。
Hash-Insert(T, k)
i = 0
repeat
j = h(k, i)
if T[j] == NIL
T[j] = k
return j
else
i = i + 1
until i == m
error "hash table overflow"
Hash-Search(T, k)
i = 0
repeat
j = h(k, i)
if T[j] == k
return j
i = i + 1
until T[j] == NIL or i == m
return NIL













 805
805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









