







SVM的文章介绍多如牛毛,很多介绍都非常详尽,而我却一点都不开窍,始终无法理解其中的奥秘。
这次,我要用自己粗浅的语言,来撩开我与SVM之间的面纱。
- SVM是要解决什么问题?
之前,冲上来就看SVM的应用,简介,最优化计算方法等。从没认真想过SVM要解决什么问题。
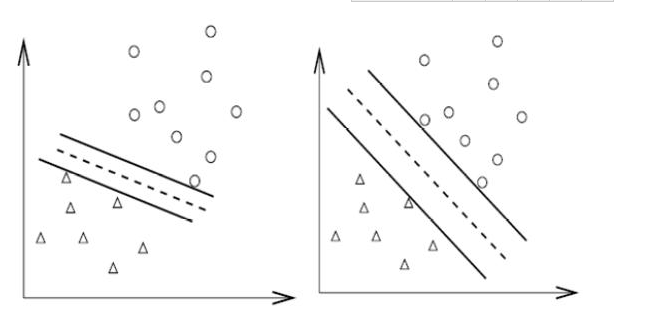
下面一幅是常用的图,来解释SVM的需求。
SVM最基本的应用是分类。 求解最优的分类面,然后用于分类。
最优分类面的定义:
对于SVM,存在一个分类面,两个点集到此平面的最小距离最大,两个点集中的边缘点到此平面的距离最大。
从直观上来看,下图左边的,肯定不是最优分类面;而右边的能让人感觉到其距离更大,使用的支撑点更多,至少使用了三个分类面,应该是最优分类面。
那么,是不是一个最优分类面需要两个或三个以上的点才能确定那?
这个要依据实际情况而定。
如下图,左图是由三个点,来确定的一个最优分类面,不同类别的两个点确定一个中心点,而同类的两个点可以确定方向向量。这个最优分类面,需要三个点。
但对于右图,直接获取不同类别的两个点的垂面,即是最优分类面。这个分类面,则需要两个点。
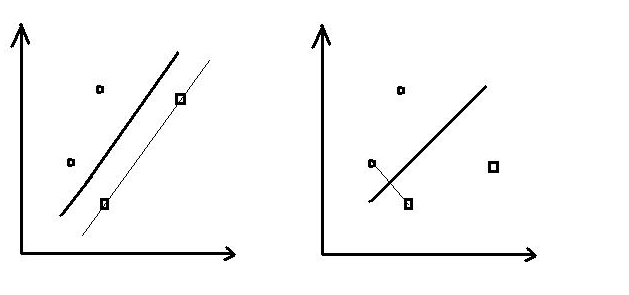
以上,情况的分析,使得求解最优分类面的思路,模式比较复杂。
若采用穷举法,至少需要以下过程。
先取不同类别的两个点,求解中心连线的垂面。如以上右图模式
然后判断其他点到此垂面的距离,若有更小的距离(或负值,即分类错误),则选取以上左图模式。
穷举所有点。采用最直接的方式处理,则其运算复杂度为 m*n*n, 若n > m.
这个还没有用到高维映射哪,如果再加上高维映射的处理,算法恐怕就更复杂了。所以,穷举法是不太现实的。
- 从直观到数学推论
由直观到拟合:
直观上,存在一个最优的超平面。
那么,我们就假设这个最优面的公式是:
W * X + b = 0,
那么对于所有的点集x,
都存在平行于最优超平面,的点集的边界面
W * xi + b >= 1 或 W * xi + b <= -1, 这里 yi可以归一化为1,-1
最大化这两个平行超平面的距离。即
max 2 / ||w||
或者说是 最小化w,即 min ||w||
另外一个条件是 W * xi + b >= 1 或 W * xi + b <= -1。
这个有点超出平时用的计算方法了(如果没学过最优化理论),因既有求极值,又有不等式存在。这个是典型的QP(quandratic programming)二次规划问题。
高数里面有有关求极值的理论,采用的是拉格朗日乘子法,但其条件是等式。
所以,需要将不等式,转化为等式的形式。 方法就引入变量。
给每个点配上一个系数α,若是边界点,那么α就为大于0,否则就为0.
则 αi * yi * (W * xi + b) = 0.
从另一方面来讲,αi也可以看做是拉格朗日系数,采用拉格朗日乘子法,求极值。
由于αi也是未知的。所以,又需要求出αi。
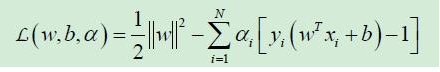
即 min ( max L ), max L 是因为后面的超平面公式经过减号后变成了 <= 形式,其求和的最大值为0。
先对min求极值, 对w,和b进行微分。
推导出以下关系

(blog没公式编辑器,想偷懒只要剪贴了)
终于推出简单点的公式了。由min 到 max 也是一个对偶转换的过程,又称dual
求max极值,并且,只有一个等式约束条件,缺点就是未知变量也增加了。
接下来,就是用最优化的方法,求取极值了。
对未知变量,取一个初始值,然后用点集中的点,一个接一个的进行训练。
直至未知变量收敛。
- SMO(序列最小最优化算法) 解法
SVM 从简单边界分类思路,到复杂的拉格朗日求解。
其实,对于二次规划问题,有经典的最速下降法,牛顿法等最优化求解方法。而SMO是一个SVM的优化算法,避开了经典的二次规划问题。
消除w,转换为 αi 的求解。这是一个更加有效的求解方法
利用KKT条件,再加上一堆的推论,终于有以下公式:
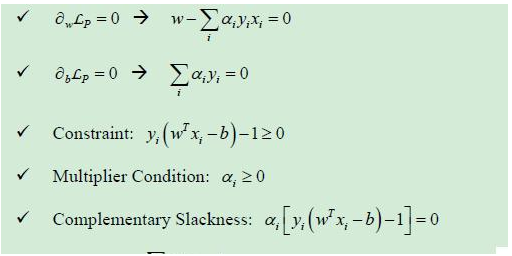
还是这么多公式和术语,真是令我头疼。只能先记着,后面慢慢消化。
原理理解:
αi * αj * … 其实仍然是一个多元规划问题,所以,先多做几个假设:
1. 假设除 α1 之外,其他都是定值,那么据∑ni=1αiyi=0, α1可以直接定下来,就无法进行优化了。
2. 若有 α1, α2是变量,其他是常量, α2可以由 α1来表示,代入到目标函数中,就形成了一个一元二次函数。这样就能轻易地求极值了。其中,还是要考虑约束条件的:
αiα
i
0 <= ai <= C. 总之,求极值是方便可行多了。
采用此方法,选取不同的 αi, αj求极值。 然后选取最大的。
SMO就是采用这种原理,只不过它不是依次或随机选取 α,而是采用启发式算法选取最优的两个维度。
John C. Platt 的那篇论文 Fast Training of Support Vector Machines Using Sequential Minimal Optimization,有原理,有伪代码可以参考。
http://blog.pluskid.org/?page_id=683
介绍的也是比较深入浅出的。
- SVM种类有哪些,适用场景及优缺点
SVM的空间复杂度:
SVM 是所占内存,是样本数据量的平方。
《A Tutorial on Support Vector Machines for Pattern Recognition》 1998KluwerAcademicPublishers,Boston,训练计算复杂度在O(Nsv^3+LNsv^2+d*L*Nsv)和O(d*L^2)之间,其中Nsv是支持向量的个数,L是训练集样本的个数,d是每个样本的维数(原始的维数,没有经过向高维空间映射之前的维数).
总的来讲,SVM的SMO算法根据不同的应用场景,其算法复杂度为~N 到~N^2.2之间,而chunking scale的复杂度为~N^1.2 到~N^3.4之间。一般SMO比chunking算法有一阶的优势。
线性SVM比非线性SVM的smo算法要慢一些。所以,据原著论文的测试,SMO算法,在线性svm上快1000倍,在非线性上快15倍。
对于SVM的SMO算法的内存需求时线性的,这使得其能适用比较大的训练集。
所以,如果数据量很大,SVM的训练时间就会比较长,如垃圾邮件的分类检测,没有使用SVM分类器,而是使用了简单的naive bayes分类器,或者是使用逻辑回归模型分类。
其他观点:
SVM在小样本训练集上能够得到比其它算法好很多的结果。支持向量机之所以成为目前最常用,效果最好的分类器之一,在于其优秀的泛化能力,这是是因为其本身的优化目标是结构化风险最小,而不是经验风险最小,因此,通过margin的概念,得到对数据分布的结构化描述,因此减低了对数据规模和数据分布的要求。
SVM也并不是在任何场景都比其他算法好,对于每种应用,最好尝试多种算法,然后评估结果。如SVM在邮件分类上,还不如逻辑回归、KNN、bayes的效果好。
SVM各个参数的含义?
sigma: rbf核函数的参数,用于生成高维的特征,常用的有几种核函数,如径向核函数,线性核函数,这个也需要凭经验来选择。
C:惩罚因子。在最优化函数中,对离群点的惩罚因子,也是对离群点的重视程度体现。这个也是凭经验和实验来选择。
SVM种类:
C-SVM: 分类型SVM,需要调优的参数有惩罚因子C,核函数参数。 C的取值 10^-4, 10^-3, 10^-2,… 到 1, 5… 依次变大
nu-SVM: 分类型SVM, 在一定程度上与C-SVM相同,将惩罚因子C换成了因子nu。其最优化的函数略有不同。nu的取值是0-1,一般取值从0.1到0.8. 0代表样本落入间隔内的数目最小的情况,1代表样本可以落入间隔可以很多的情况。
wiki上的原话:
The main motivation for the nu versions of SVM is that it has a has a more meaningful interpretation. This is because nu represents an upper bound on the fraction of training samples which are errors (badly predicted) and a lower bound on the fraction of samples which are support vectors. Some users feel nu is more intuitive to use than C or epsilon.
C-SVR: 用于回归的svm模型
nu-SVR:同上
- 其他相关概念:
VC维:将N个点进行分类,如分成两类,那么可以有2^N种分法,即可以理解成有2^N个学习问题。若存在一个假设H,能准确无误地将2^N种问题进行分类。那么这些点的数量N,就是H的VC维。 这个定义真生硬,只能先记住。一个实例就平面上3个点的线性划分的VC维是3. 而平面上 VC维不是4,是因为不存在4个样本点,能被划分成2^4 = 16种划分法,因为对角的两对点不能被线性划分为两类。更一般地,在r 维空间中,线性决策面的VC维为r+1。
置信风险: 分类器对 未知样本进行分类,得到的误差。也叫期望风险。
经验风险: 训练好的分类器,对训练样本重新分类得到的误差。即样本误差
结构风险:[置信风险, 经验风险], 如(置信风险 + 经验风险) / 2
置信风险的影响因素有: 训练样本数目和分类函数的VC维。训练样本数目,即样本越多,置信风险就可以比较小;VC维越大,问题的解的种类就越多,推广能力就越差,置信风险也就越大。因此,提高样本数,降低VC维,才能降低置信风险。
而一般的分类函数,需要提高VC维,即样本的特征数据量,来降低经验风险,如多项式分类函数。如此就会导致置信风险变高,结构风险也相应变高。过学习overfit,就是置信风险变高的缘故。
结构风险最小化SRM(structured risk minimize)就是同时考虑经验风险与结构风险。在小样本情况下,取得比较好的分类效果。保证分类精度(经验风险)的同时,降低学习机器的 VC 维,可以使学习机器在整个样本集上的期望风险得到控制,这应该就是SRM的原则。
当训练样本给定时,分类间隔越大,则对应的分类超平面集合的 VC 维就越小。(分类间隔的要求,对VC维的影响)
根据结构风险最小化原则,前者是保证经验风险(经验风险和期望风险依赖于学习机器函数族的选择)最小,而后者使分类间隔最大,导致 VC 维最小,实际上就是使推广性的界中的置信范围最小,从而达到使真实风险最小。
训练样本在线性可分的情况下,全部样本能被正确地分类(咦这个不就是传说中的yi*(w*xi+b))>=1的条件吗),即经验风险Remp 为 0 的前提下,通过对分类间隔最大化(咦,这个就是Φ(w)=(1/2)*w*w嘛),使分类器获得最好的推广性能。
对于线性不可分的状况,可以允许错分。即对于离群点降低分类间隔。将距离原来的分类面越远,离群就越严重,这个距离,可以用一个值–松弛变量来表示,只有离群点才有松弛变量。当然,要对这个值加以限制,即在最小化函数里,加入一个惩罚项,里面还有一个可以人为设定的惩罚项C。当C无限的大,那么就退化为硬间隔问题,不允许有离群点,问题可能无解。若C=0,无视离群点。有时C值需要多次尝试,获取一个较好的值。 这个里面可分析还很多,后面再学习。
核函数作用:将完全不可分问题,转换为可分或达到近似可分的状态。
松弛变量:解决近似可分的问题。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









