




这篇文章主要讨论C++继承中的高级话题。主要偏向于编译器的实现角度,也会包含部分应用角度。本文是一个长篇连载,不定期更新。
说明:本文章中用到的测试环境均是Redhat Linux Enterprise 6 x86_64 (64位), 编译器 g++ 4.4.7
预期的内容至少包括:
1.子类如何能够调用父类的函数
2.虚函数,虚表
3.构造函数,拷贝构造函数,析构函数语意学
1.子类如何能够调用父类的函数
1.1准备问题
我们知道,类的函数是存储在静态区的,类的每个函数只有一份,每个类的实例都共享这些函数。
这里产生了一个问题:如果是存在静态区,就有了“全局”的意思,那么一个类中的相同名字的函数如何去区分呢?这里可以用C++的命名改编解释,C++中每个函数其实都会被改名,除非你显式地指定使用,extern "C"禁止函数名字改编。每一个函数都会改为另一个惟一的名字,故,即使是处于一个类的同名函数在静态区中的存储也是不一样的,也就做到了区分。
还有一个问题:成员函数如何访问对象的数据?我们都知道,每个成员函数里面有一个隐含的this指针指向施于该函数的对象。成员函数存储于静态区,从存储的程序文件就已存在,而对象是在运行时期才分配空间的,那这个this指针是如何存在于函数内部的呢?答案是:每个成员函数在编译期被编译期加入了一个指针参数,该指针指向当前的类对象。伪码类似: void A:: say(A* pa);每次施于此函数的对象调用此函数时就会将其地址传给pa;
1.2单继承情况
为了说明子类如何调用父类的函数,特编写以下的测试代码:
#pragma pack(4) //使用4字节对齐的方案,这里因为64位机器 int 为4个字节,指针是8字节,
//而类中用到了这两种类型,为了防止int的占位被透明地对齐,所以使用4字节对齐,
//让每个成员的真实内存地址更清晰地显示。
class CBase1
{
private :
int id;
char *name;
public:
void say()
{
printf("-----------------------------------\r\n");
//打印对象的地址
printf("this: %p\r\n",this);
//打印对象的成员地址
printf("id: %p\r\n",&id);
printf("name: %p\r\n",&name);
}
};
class CDrive : public CBase1
{
private :
int oid;
public :
CDrive(){}
void selfsay()
{
printf("-----------------------------------\r\n");
//打印对象的地址
printf("origin object : %p\r\n",this);
//打印对象的成员地址
printf("oid: %p\r\n",&oid);
}
}
void test()
{
CDrive d;
d.selfsay();
d.say();
}
int main()
{
test();
return 0;
}
额外地说明:本例中函数直接在类中被定义,这时内联并不是讨论的要点,它不影响我们讨论的内容。
输出的结果是:
-----------------------------------
origin object : oxfff...c20
oid : oxfff...c2c
-----------------------------------
this : oxfff...c20
id : oxfff...c20
name : oxfff...c24
由输出的结果,我们发现,构造的CDrive对象的地址(简称)为 20,其父类的成员id地址也是20,id是int类型,占4个字节,name紧接其后,所以name是24,name是个指针类型,占8个字节,原对象(test函数中的d)的成员oid地址是2c。
根据以上数据,我们作以下推测:
1.子类的内存空间包含父类的成员,因为 id 和 name 夹在对象的首地址和对象的成员oid之间。
2.父类的成员从子类的内存空间的首地址向后排布,这点从 id 和 name的地址值可以看出来。
3.函数CBase1::say接受了一个CBase*的参数,即,存在 CBase * ptmp = &d;在CBase::say里打印的 this 的值为 20,也等于原对象(test函数中的d)的地址;
根据上面的推测,我们大致可以知道子类是怎样访问父类的函数了。首先,我们要认识到一点,父类的函数只会操作父类对象的数据,因为父类根本不知道它是否有子类以及子类的成员。其次,父类的函数是通过传入的 this 指针访问对象数据的,本质上,是通过偏移量来实现访问的。而函数代码经过编译后已经确定了,即,函数里面取父类成员的
偏移量的大小与取子类成员中的父类成员的偏移量大小应该是一样的!所以编译器出于这个原因,有如下的设计:
1.父类成员依次从子类对象的首地址向后排布。
2.子类对象指针传入父类成员函数时指针的数值没有改变。即,对父类适合的成员解析同样也适合于子类的成员解析。(也许这句话你会惊呼:“当然如此”!因为,谁会期望编译器在我只希望更改一个指针的类型的时候而改变了它的值呢?这不可能!但事实上可能会令你失望,因为这不是绝对的!稍后将会讲到)
1.3多重继承
那么,如果把上述的情况变复杂,加入多重继承会怎样呢?
再定义一个父类CBase2,定义如下:
class CBase2
{
public:
int level;
void does()
{
printf("-----------------------------------\r\n");
//打印对象的地址
printf("this : %p\r\n",this);
//打印对象的成员地址
printf("level: %p\r\n",&level);
}
}
//让CDrive不仅继承于CBase1,还继承CBase2,
class CDrive : public CBase1,pubilc CBase2
{
...//CDrive的内容不变
}
测试函数加入对CBase2::does的调用,
void test()
{
CDrive d;
d.selfsay();
d.say();
d.does();
}
得到如下输出结果:
-----------------------------------
origin object : oxfff...c20
oid : oxfff...c30
-----------------------------------
this : oxfff...c20
id : oxfff...c20
name : oxfff...c24
-----------------------------------
this : oxfff...2c
level : oxfff...2c
CDrive * pd = &d;
CBase2 * pb = pd;
指针的自动偏移就发生在第二句话。那么编译器为什么要采用暗地里的手段去改一个内存地址呢?因为,程序员有理由相信,一切不由自己做的更改可能都是非正确的!那么编译器为什么认为它是正确的呢 ?
因为编译器不认识类的成员变量的名字,它只认识偏移量,这个是在编译时期决定了的,以后都不会变(这也是为什么会导致程序涉及到指针运算,赋值后可能存在与平台不兼容的原因),比如,编译器只知道,CBase1::id 对应于CBase1的对象的偏移为0字节,CBase::name的偏移为4字节,CBase2::level对应于CBase2的对象的偏移为0字节,这个行为对于所有的对象都应该是一样的!编译器为了保护这个行为施于所有对象时都是一样的,所以它必须得为有些不属于这种行为的行为予以适当的纠正!上面的多重继承导致的“并非每一个父类的成员都会放置于子类对象的首地址处”,那么,只能在地址转换时,编译器予以自动的偏移校正,而这个是可以保证是正确的,只要将所有的意外情况纠正,则“施于所有对象身上的取成员操作都是正确的”得到了保证!
1.3.1子类指针向父类指针转型
如果有人写出以下代码:
CBase2 b;
CDrive * pd = &b;
编译器会不会警告或者是报错?
如果已经对对象的内存布局了然于胸,则此问题你应该信心十足地说,编译器会报错而不只是抱怨!因为对于一个静态类型为 CBase2的对象来讲,它的内存布局中肯定就不含有子类的成员,那么,它怎么知道需要编移多少才能到达子类的首地址呢?也许该子类还继承了其它的类,或者该子类有虚函数(这种情况是下一个要讲到的话题),或者。。。太多的未知情况让这个问题充满了阴霾!就算编译器确定了父类指针转向子类指针的编移量,这个行为也是毫无意义且充满了危险的,你应该怀有极大的敬意去亲近这个行为!(哈哈,这里是借用了Effective C ++中Scott Meyers描述转型时用的一句话,本人很喜欢Scott Meyer写书的风格,此处取而用之,以示向大师的敬意!)我们知道,子类的数据成员都排布在父类数据成员(这里讨论的不包括静态的成员)的后面,那么,你拿到的转型后的子类对象指针,天晓得你会对内存中的数据施以什么暴行!如果你仅仅是访问一下数据,并不想修改,你可以这样骗过编译器:
CBase2 b;
CDrive * pd = (CDrive *)(void *)&b;
此处,就是C++另外的标准所保证的:C++指针的类型只是负责解释传入的内存地址里面装的什么!它并不具有什么魔法!你当然可以使用 char *的方法去解析,也可以把它当作悬而未决的方法(void *)而暂时不加以解析,你还可以。。。总之,你可以做你想做的任何事情,不过假设你不对自己加以约束,迟早有某个时候,你会惊呼不妙!
在上面的“欺诈”行为之后,我们继续编写一点代码,对它进行测试:
b.does();
pd.selfsay();
在公布测试结果之前,请转入下一节。
1.3.2一个让你紧崩神经的问题
我想先问你一个问题,为什么pd能够调用selfsay函数?或者说,有如下的代码:
CDrive *pd = NULL;
pd -> selfsay();
是否会真的会有在你看过这短短两行代码后,隐约地一直在触动你那敏感的神经的崩溃行为?
在我试图说服你,让你松下你那紧崩的神经前,我想让你回忆一下对象的内存布局!对象的数据存放在什么地方,函数存放在什么地方?你之所以紧张,是因为你想到了类似(NULL) -> member的调用方式会导致 access violation(访问违例),因为进程空间中的内存有一段是禁止访问区,如果强制访问则会触发 access violation。你可以写一段代码用来测试:
int *pt = (int *)(void*)(0x10);
int i = *pt;
后一句话将引发访问违例,因为试图从用户禁入区访问数据!
言归正传,为什么
CDrive *pd = NULL;
pd -> selfsay();
能够正常地执行呢?这是因为CDrive::selfsay函数独立于对象而存在,对于它的调用被转化为了:selfsay(CDrive*)的形式,在本例中,也就是selfsay(NULL),这是合法的!谁会阻止你给一个函数传入一个NUll行参呢?我们再看selfsay函数内部,并没有涉及到访问禁访问区,所以自然不会不合法!
那么,是时候分析我们写的“欺诈代码”了:
CBase2 b;
CDrive * pd = (CDrive *)(void *)&b;
b.does();
pd.selfsay();
只需要分析最后一句,因为施于CDrive::selfsay函数的对象并不是一个合法的对象,最坏的情况就是你给它传入一个NULL,它也不会崩溃!所以它还是会执行的,只不过这个结果毫无意义!
执行的结果如下:
-----------------------------------
this : oxfff...c10
level : oxfff...c10
-----------------------------------
origin object : oxfff...c10
oid : oxfff...c20
-----------------------------------
惟一有意思的是,oid 还是坚持排布在其对象的首地址的后面16个字节!这里你应该动脑筋想一下为什么?(其实也是很简单的)
1.4多重继承子类有虚函数
与多重继承的情况一样,一旦子类新增加了虚函数,则也会存在子类指针向父类指针转型时的偏移。
我们现在在子类 CDrive中加入一个虚函数,使之成为如下定义:
class CDrive
{
private :
int oid;
public :
CDrive(){}
void selfsay()
{
printf("-----------------------------------\r\n");
//打印对象的地址
printf("origin object : %p\r\n",this);
//打印对象的成员地址
printf("oid: %p\r\n",&oid);
}
virtual void write(){}
}
我们知道,一个类若有虚函数,则它必然会有一个虚表指针指向一个虚表。而这个虚表指针是放置于对象之首的。直接给出输出结果:
-----------------------------------
origin object : oxfff...fe0
oid : oxfff...ff8
-----------------------------------
this : oxfff...fe8
id : oxfff...fe8
name : oxfff...fec
-----------------------------------
this : oxfff...ff4
level : oxfff...ff4
由结果,我们得到以下结论:
1.对象首地址为 fe0,CBase1的 subobject存在于其后的8个字节,说明首个8个字节一定存放着某个物件。
2.其它的规律与之前的一样。
这里可以直接给出结论:首个八字节放的正是指向虚表的指针。之所以要放在首个8字节是有原因的,这个原因将在后面给出。
1.5多重继承父类有虚函数
让我们把问题再变得复杂一点,以挖掘得更深一些:
在CBase2中增加一个虚函数且依然保持多重继续的体系:
class CBase2
{
public :
int level;
void does()
{
printf("-----------------------------------\r\n");
//打印对象的地址
printf("this : %p\r\n",this);
//打印对象的成员地址
printf("level: %p\r\n",&level);
}
virtual void talk(){};
}
//让CDrive依然多重继承
class CDrive : public CBase1,pubilc CBase2
{
...//CDrive的内容不变
}
因为这种情况已经很复杂了,单纯用输出来看显得有点无所适从,所以画图以示之。
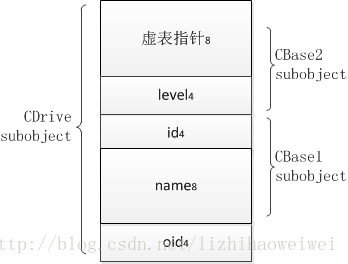
每个成员的右下角的数字表示占的字节数。如果有以下的测试语句:
CDrive d;
CBase1 *pb1 = &d;
CBase2 *pb2 = &d;
则我们可以预计:
pb2 - &d = 0 , pb1 - &d = 12;这样才能保证“施于真实的对象d上的操作也适合其父类的操作”。
1.6多重继承多个父类都有虚函数
再让情况变得复杂一点,如果让两个父类都有一个虚函数,
class CBase1
{
private :
int id;
char *name;
public:
void say()
{
printf("-----------------------------------\r\n");
//打印对象的地址
printf("this: %p\r\n",this);
//打印对象的成员地址
printf("id: %p\r\n",&id);
printf("name: %p\r\n",&name);
}
virtual void play()
{
printf("in CBase1::virtual void play\r\n");
}
};
class CBase2
{
public :
int level;
void does()
{
printf("-----------------------------------\r\n");
//打印对象的地址
printf("this : %p\r\n",this);
//打印对象的成员地址
printf("level: %p\r\n",&level);
}
virtual void talk(){};
}
则再画出内存布局图:
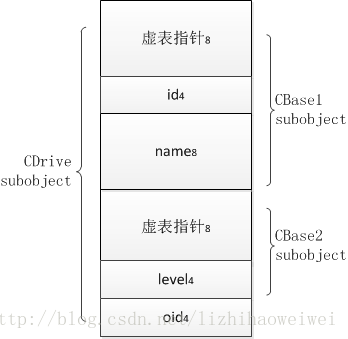
可以看出,现在已经有了两个虚表,一个是CBase1 subobject的,另一个是CBase2 subobject的,那么,我们怎样确定子类的虚函数被加于哪一个虚表中呢?不知道你注意到没有,“每一个对象的虚表指针都放置于该对象首地址四个字节中”,CBase1,CBase2都是,所以,为了保证所有对象的行为的尽量统一,则子类对象的虚表与第一个虚表进行合并!将它增加的虚函数指针增加到第一个虚表中!这里的第一个虚表,指的它最先继承的那个具有虚函数的类的虚表,两个条件一个不可缺少(最先继承且该父类有虚函数)。
1.7为什么对象的虚表指针一定要放置于对象的首地址
另外,前面曾经提到过一个问题,“为什么对象的虚表指针一定要放置于对象的首地址处呢?”,下面正式地回答这个问题。
主要是出于:对象开为的统一与访问的简单性
试想,一个对象里面可以永久作为存放这个指针的位置有多少个?我的意思是指,在不打乱原先对象成员布局的情况下!你也许会说,有无数多个啊,放于对象首地址向后的1个字节处,2个字节处......甚至任何一个字节开始处都可以!这样你就完全没有搞清楚我的意思!对象确定的地址处是指,与对象本身的成员是何类型,占多大空间没有关系,这些确定的地址永远都存在!你也许会这样想,那这个指针能不能存放在诸如,“对象的第一个成员后面”?
我会这样试图去解释,因为对象的第一个成员的大小是不确定的,虽然编译时期就可以确定这个大小,但是对于不同的类的对象,第一个成员肯定会有存在不同类型,不同大小的,也就说是,在不同对象中,基于对象基址的寻址,这个偏移量不都一样,虽然可以访存到处于第一个对象后面虚表指针,但这样既不经济,也不符合软件工程的一些规则,比如,行为与数据强相关了!而且这种寻址方式会失去部分可移植性!
考虑另一种方式,如果我们把偏移量规定好,让对象的基址作偏移去访存呢?这样就破坏了对象的内存。有如下原因:1).内存对齐将使得对象的内存布局扑朔迷离,你很有可能会得到很多种不同的布局。2).这个偏移量让对象对于成员的访问变得间接且复杂。这点你可以自行推断。
依你所见,这个指针只有放在对象的首地址才会让所有对象都不需要思考去拿什么值作编移量,减少了设计上的复杂。
1.8虚表的布局
虚表的结构比较简单,你可以把它理解为函数指针数组,而每个虚表会用某个特殊的值去标注结尾以及是否还有下一个虚表,这些值是不确定的,它与编译器的实现有关系。
画如下图:
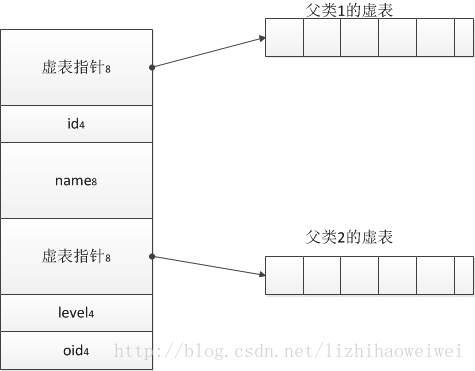
两个父类与一个子类,只有二张虚表。这个前面已经说过,子类与继承顺序中的第一个父类共用一个虚表。很自然的是,如果子类重写了父类中的虚函数,则父类虚表中的函数指针指向子类的函数否则不变。而新增加的虚函数则放入第一个父类的虚表中。
我们现在根据虚表的结构直接调用某个虚函数看能否成功。编写如下的测试代码:
CDrive d;
typedef void *ADDRESS; //定义一个“地址类型",那个void不是必须的,你可以用任何类型来代替,因为所有指针类型
//的长度都是一样的,更进一步来说,所有的指针都是一样的,只是解析方式不同而已!
//64位机器上也可以改写为 typedef long long ADDRESS;前一种写法更具有移值性
typedef void (* PFUNC)();//定义一个接受void参数返反void的函数指针
ADDRESS *pvptr = (ADDRESS*)&d;//将d按ADDRESS*方式去解析,也就是得到一个虚表指针的存放地址。
ADDRESS vptr = *pvptr;//解析虚表指针的地址区,得到虚表指针的值,即虚表的地址。
PFUNC pvfunc1 = (PFUNC)*((ADDRESS*)vptr);//第一个虚函数指针
//PFUNC pvfunc2 = (PFUNC)*((ADDRESS*)vptr + 1);//第二个虚函数指针
//...
pvfunc1(); //调用第一个虚函数
正确地打印出了:
in CBase1::virtual void play
说明正确地调用了CBase1的第一个虚函数。如果对上面的注释中的解释理解有困难,可以参照我的另一篇文章《指针高级》
《Inside The C++ Object Model》一书中指出:虚表的首地址处是对象的 type_info。
但我们在上面的测试代码直接把首地址处当成了第一个函数指针指的地址。那这样岂不是矛盾了 ?
如果有调试工具,你可以测试,这个type_info放在虚表的前面,即假设 table是虚表,则 table[-1]存放的是type_info结构体指针或者某一个封装的类的指针。type_info是怎样实现的这里我们就不需要深究了,只需要搞清楚一点,它可以减去四字节的偏移量得到它的地址即可。

















 506
506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









