







 本文详细介绍了如何使用Scrapy框架爬取豆瓣电影Top250的完整过程,包括创建项目、定义爬虫、解析数据、存储信息及处理图片下载。在解析过程中遇到的403错误通过模拟浏览器请求头得以解决,同时通过Items和Pipelines分别处理数据结构和存储。在遇到robots.txt限制时,选择忽视以完成图片下载。
本文详细介绍了如何使用Scrapy框架爬取豆瓣电影Top250的完整过程,包括创建项目、定义爬虫、解析数据、存储信息及处理图片下载。在解析过程中遇到的403错误通过模拟浏览器请求头得以解决,同时通过Items和Pipelines分别处理数据结构和存储。在遇到robots.txt限制时,选择忽视以完成图片下载。
看了几篇博客,跟着其他大佬的讲解学习了一下使用scrapy框架爬取网站信息,然后自己趁热打铁一波爬取一下豆瓣电影top250
运行环境
1. win7-64bit
2. python 3.5.3
可以看到该页面结构如下图
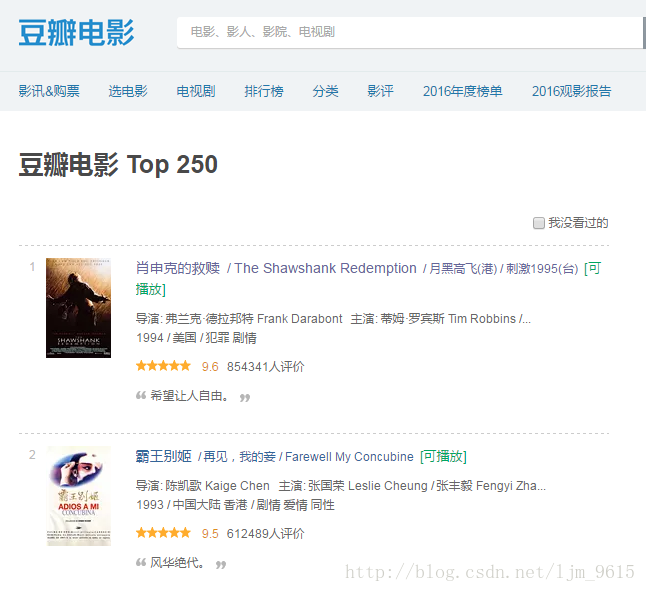
而要爬取的部分为
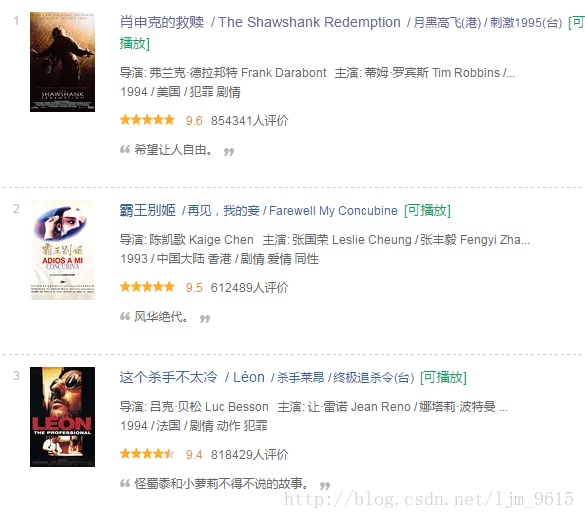
通过查看源代码,需要解析的代码就是这么一部分
<li>
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img alt="肖申克的救赎" src="https://img3.doubanio.com/view/movie_poster_cover/ipst/public/p480747492.webp" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>
1994 / 美国 / 犯罪 剧情
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4616
4616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









