







上篇博客使用scrapy框架爬取豆瓣电影top250信息将各种信息通过json存在文件中,不过对数据的进一步使用显然放在数据库中更加方便,这里将数据存入mysql数据库以便以后利用。
运行环境:
1. win7-64bit
2. python 3.5.3
3. mysql 5.7.17
安装mysql数据库模块
打开命令行输入python后,通过import MySQLdb检查是否支持mysql数据库
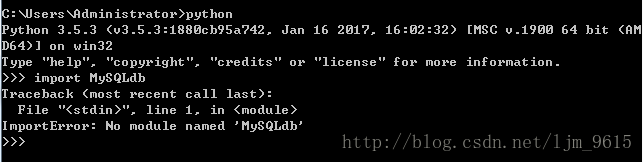
出现错误
ImportError: No module named MySQLdb
那么就要手动安装,查找发现mysqldb只支持到python3.4,这里选择使用pymysql,通过这里下载后解压,切换到PyMySQL3-0.5目录,通过shift+鼠标右键选择在此处打开命令窗口,输入命令python setup.py install安装
安装结束后,测试是否可以使用

安装成功!
创建数据库和表
由于上篇博客中爬取的数据属性就是对应的MovieItem属性
class MovieItem(scrapy.Item):
# 电影名字
name = scrapy.Field()
# 电影信息
info = scrapy.Field()
# 评分
rating = scrapy.Field()
# 评论人数
num = scrapy.Field()
# 经典语句
quote = scrapy.Field()
# 电影图片
img_url = scrapy.Field()据此创建数据库表,创建数据库的时候加上DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci,以防出现乱码
create database douban < 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









