




K-means算法属于无监督学习聚类算法,其计算步骤还是挺简单的,思想也挺容易理解,而且还可以在思想中体会到EM算法的思想。
K-means 算法的优缺点:
1.优点:容易实现
2.缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢
使用数据类型:数值型数据
以往的回归算法、朴素贝叶斯、SVM等都是有类别标签y的,因此属于有监督学习,而K-means聚类算法只有x,没有y
在聚类问题中,我们的训练样本是
其中每个Xi都是n维实数。
样本数据中没有了y,K-means算法是将样本聚类成k个簇,具体算法如下:
1、随机选取K个聚类质心点,记为
2、重复以下过程直到收敛
{
对每个样例 i ,计算其应该属于的类:
对每个类 j ,重新计算质心:
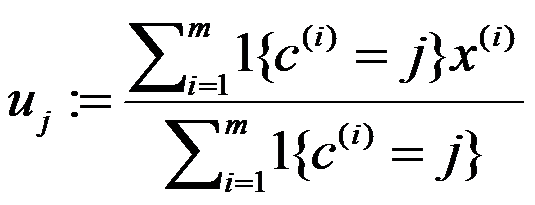
}
其中K是我们事先给定的聚类数目,Ci 表示样本 i 与K个聚类中最近的那个类,Ci的值是1到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









