







大二上学期的时候用python实现过一个简单的爬虫,学了go以后发现go的标准库十分强大,于是想实现一个教务系统的爬虫,爬取学分和成绩页面,再搞一个web界面出来.
项目github地址:https://github.com/Nickqiaoo/go-webcrawler
爬取分析
爬虫无非就是模拟浏览器的HTTP请求,我们首先来看一下浏览器是怎么发请求的.
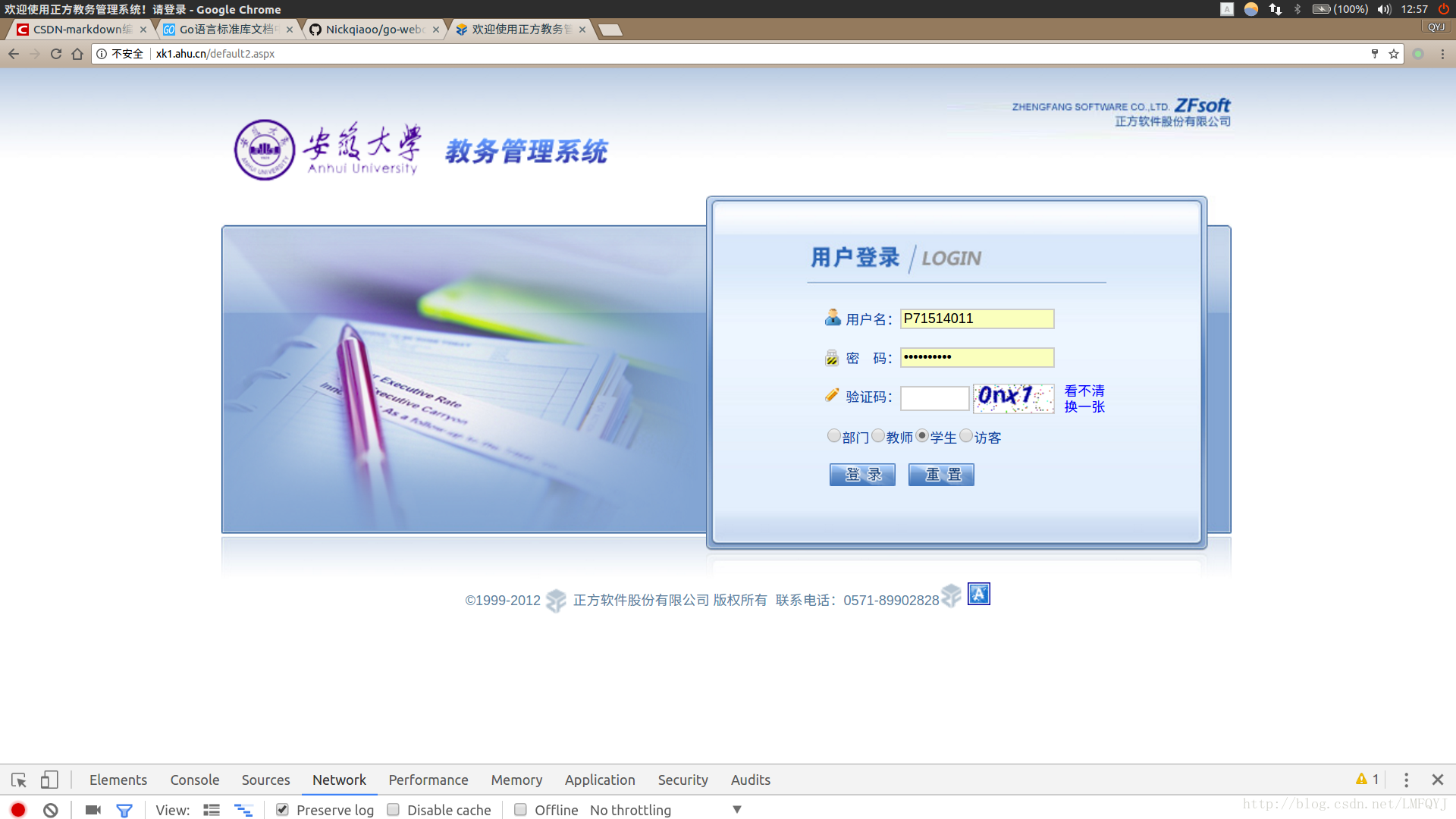
这是教务系统的主页,要想登录首先要获取验证码.验证码是怎么获取的呢?
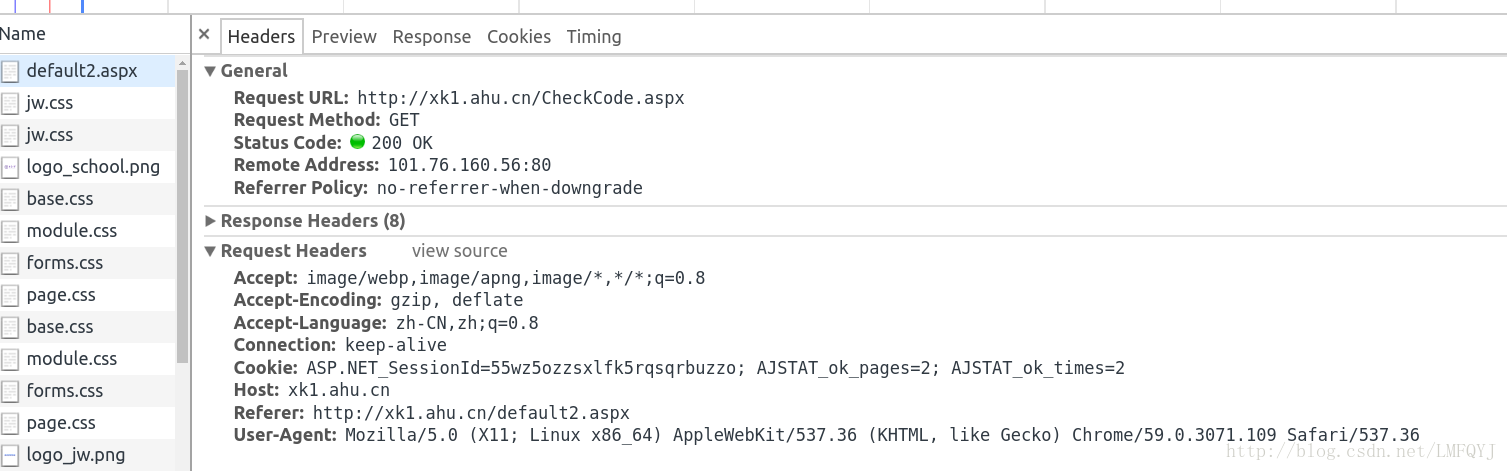
可以看到是GET CheckCode这个UR
爬虫无非就是模拟浏览器的HTTP请求,我们首先来看一下浏览器是怎么发请求的.
这是教务系统的主页,要想登录首先要获取验证码.验证码是怎么获取的呢?
可以看到是GET CheckCode这个UR

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2069
2069





