







Introduction
本文对colly如何使用,整个代码架构设计,以及一些使用实例的收集。
Colly是Go语言开发的Crawler Framework,并不是一个完整的产品,Colly提供了类似于Python的同类产品(BeautifulSoup 或 Scrapy)相似的表现力和灵活性。
Colly这个名称源自 Collector 的简写,而Collector 也是 Colly的核心。
Colly Official Docs,内容不是很多,最新的消息也很就远了,仅仅是活跃在Github
Concepts
Architecture
从理解上来说,Colly的设计分为两层,核心层和解析层,
Collector:是Colly实现,该组件负责网络通信,并负责在Collector作业运行时执行对应事件的回调。Parser:这个其实是抽象的,官网并未对此说明,goquery和一些htmlquery,通过这些就可以将访问的结果解析成类Jquery对象,使html拥有了,XPath选择器和CSS选择器
通常情况下Crawler的工作流生命周期大致为
- 构建客户端
- 发送请求
- 获取响应的数据
- 将相应的数据解析
- 对所需数据处理
- 持久化
而Colly则是将这些概念进行封装,通过将事件注册到每个步骤中,通过事件的方式对数据进行清理,抽象来说,Colly面向的是过程而不是对象。大概的工作架构如图
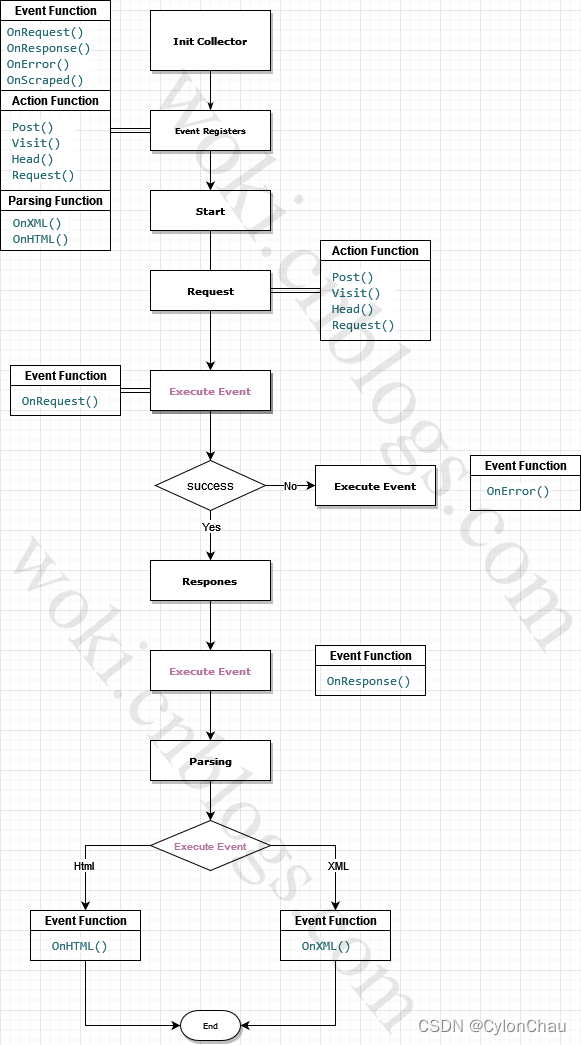
event
通过上述的概念,可以大概了解到 Colly 是一个基于事件的Crawler,通过开发者自行注册事件函数来触发整个流水线的工作
Colly 具有以下事件处理程序:
- OnRequest:在请求之前调用
- OnError :在请求期间发生错误时调用
- OnResponseHeaders :在收到响应头后调用
- OnResponse: 在收到响应后调用
- OnHTML:如果接收到的内容是 HTML,则在 OnResponse 之后立即调用
- OnXML :如果接收到的内容是 HTML 或 XML,则在 OnHTML 之后立即调用
- OnScraped:在 OnXML 回调之后调用
- OnHTMLDetach:取消注册一个OnHTML事件函数,取消后,如未执行过得事件将不会再被执行
- OnXMLDetach:取消注册一个OnXML事件函数,取消后,如未执行过得事件将不会再被执行
Reference
Utilities
简单使用
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
// Instantiate default collector
c := colly.NewCollector(
// Visit only domains: hackerspaces.org, wiki.hackerspaces.org
colly.AllowedDomains("hackerspaces.org", "wiki.hackerspaces.org"),
)
// On every a element which has href attribute call callback
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
link := e.Attr("href")
// Print link
fmt.Printf("Link found: %q -> %s\n", e.Text, link)
// Visit link found on page
// Only those links are visited which are in AllowedDomains
c.Visit(e.Request.AbsoluteURL(link))
})
// Before making a request print "Visiting ..."
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL.String())
})
// Start scraping on https://hackerspaces.org
c.Visit("https://hackerspaces.org/")
}
错误处理
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
// Create a collector
c := colly. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1453
1453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











