









上篇我们介绍了词法分析阶段单词的识别工具--正规式。本篇介绍正规式的识别装置--有穷自动机。
之所以称为有穷自动机?我想这和人们把把不同的设计模式起了名字一样,和同样是java代码被称为Servlet一样。人们把抽象的东西起了一个客观的名字。
有穷自动机:
能准确的识别正规集,能识别正规文法所定义的语言和正规式表示的集合,也为词法分析程序的自动构造寻找特殊的方法和工具。
分为两类:确定的有穷自动机(determinirstic finite automata)和不确定的有穷自动机(nondeterministic finite automata)。
确定和不确定的区别在哪里呢?首先分别看看我们的定义。
确定有穷自动机:
一个确定的有穷自动机M是一个五元组:M=(K, ∑,f,S,Z)其中,
1)K是一个有穷集,他的每个元素称为一种状态。
2) ∑是一个有穷字母表,他的每个元素称为一个输入符号,所以∑称为输入符号表。
3)f是转换函数,是KX∑-->K 上的映像,例如f(ki,a)=kj这就意味着,当前状态为k,输入字符a后,将转换到下一状态kj,我们把kj称为ki的一个后继状态;
4)S属于K,是唯一的一个出态。
5)Z属于K,是一个终态,终态也称为可接受状态或结束状态。
例 如下:
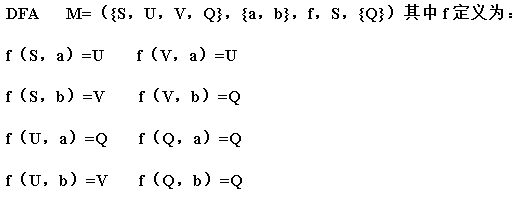
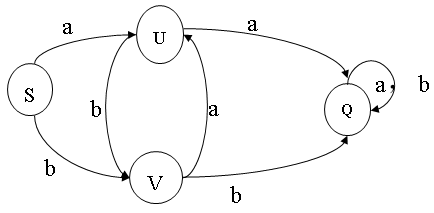
一个DFA可以表示一个状态转换图,如下所示:
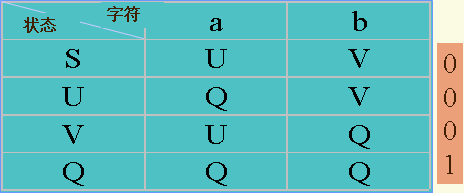
也可以用状态矩阵显示,行表示状态,列表示输入符号,终态在表的右端标1,非终态在表的右边标0。
不确定有穷自动机:
与确定有穷自动机不同:
3)是一个子集映像。
4)S属于K是一个非空出态集;
5)Z属于K是一个终态集。
例如:
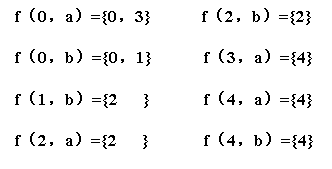
注: 上面的图片中改为 f(0,b)={0}
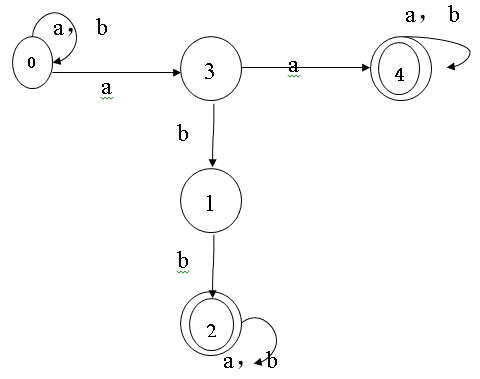
他们有什么不同之处呢?
1)确定有穷自动机状态是唯一的。
2)确定有穷自动机f是单值映射。
确定的有穷自动机就是说当一个状态面对一个输入符号的时候,它所转换到的是一个唯一确定的状态;而不确定的有穷自动机是说当一个状态面对一个输入符号的时候,它所转换到的可能不只一个状态,可以是一个状态集合。这就是两者的主要区别。还有就是DFA的开始状态是唯一的,而NFA的开始状态是一个开始状态集。
我们自己理解,确定和不确定的区别,确定是不怎么变化的,不确定是变化的,无论是变化还是不变化的问题的本质呢?
本篇就介绍到这里,下篇介绍不确定有穷自动机和确定有穷自动机之间的转换和自动机的最小化。
愿开心阅读~~~















 8682
8682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









