






词法分析程序要实现的功能
词法分析程序(Lexical analyzer,简称Lexer),负责从左到右逐个字符地对源程序进行扫描和分解,根据语言的词法规则识别出一个个的单词符号。
【单词】单词是语言中具有独立意义的最小语法单位。
功能分解
-
从左至右扫描构成源程序的字符流
-
识别出有词法意义的单词
-
返回单词记录,或词法错误信息
-
除以上主要任务外,常伴有如下任务:
滤掉空格,跳过注释、换行符,追踪换行标志,复制出错源程序,宏展开,…也可能包含访问符号表的操作等。
1 扫描
2 识别单词
2.1 描述单词的工具
2.1.1 正规文法
右线性文法:A→aB或A→a
其中,A、B为单个的非终结符,a为单个的终结符。
1 标识符的文法
设l表示a~z中的任何一英文字母,d表示0~9中的任—数字
描述标识符的文法为:
G11[I] : l → lB | l
B → lB | dB | l | d
2 无符号整数和整数的文法
描述无符号整数的文法为:
G[D]: D → dD | d
描述整数的文法为:
G[N]: N → +D | -D
D → dD | d
3 无符号实数的文法
4 其它文法
<运算符> → +|-|*|/|=|>|<......
<界符> → ,|;|(|)|......
2.1.2 正规式
正规表达式(regular expression)是说明单词的模式(pattern)的一种重要的表示法(记号),是定义正规集的工具。
正规式也称正则表达式,也是表示正规集的数学工具。
定义:
1、 Φ(空集)是一个正规式,它所表示的正规集为Φ(空集);
2、 ε 是一个正规式,它所表示的正规集为{ ε } ;
3、 任何a属于字母表,a是字母表上的正规式,正规集为{ a };
4、 设e1和e2分别是正规集L(e1)和L(e2)的正规式。则:
a、e1 | e2 是正规式,表示的正规集为L(e1)∪L(e2);
b、e1 · e2 (·通常省略),即e1e2是正规式,表示的正规集为L(e1)L(e2);
c、e1*是正规式,表示的正规集为(L(e1)*);
三种运算符:
优先级:* > · > |
|读为“或”;
· 读为“连接”;
* 读为“闭包”(即,任意有限次的自重复连接)。
连接符 · 一般可省略不写。它们都是左结合的
| 正规式 | 正规集 |
|---|---|
| a | {a} |
| a I b | {a} U {b} = {a, b} |
| ab | {a}{b} = {ab} |
| (a I b)(a I b) | {a, b}{a, b} = {aa, ab, ba, bb} |
| a* | {a}* = {ε, a, aa, aaa, …任意个a} = {a^n I n>=0} |
运算性质:
1 标识符的正规式
设l表示a~z中的任何一英文字母,d表示0~9中的任—数字
l (l | d)
2 无符号整数的正规式
d*d = d+ = dd*
3 无符号实数的正规式
d*(dd* | ε)( e (+|-|ε) dd* | ε)
4 运算符的正规式
+|-|*|/|(|)|......
2.2 识别单词的工具–有穷自动机FA
有穷自动机FA
有穷自动机(也称有限自动机)作为一种识别装置,它能准确地识别正规集,即识别正规文法所定义的语言和正规式所表示的集合。
引入有穷自动机这个理论,正是为词法分析程序的自动构造寻找特殊的方法和工具。
自动机模型
有穷控制器控制读头从左向右逐个扫描并读入输入符号,并且根据控制器的当前状态和当前输入符号控制转入下一个状态。
接受方式
FA在初始状态下开始读入第一个输入符。
FA接收输入串:终态方式。
→若读头在输入带上最后一个符号时,恰好进入某个终止状态,则宣布接收该输入串;否则,不接收。
1 确定的有穷自动机DFA
DFA定义:
一个确定的有穷自动机(DFA)M是一个五元组:M=(S,∑,f, S0,Z),其中:
– S是一个有穷状态集,每个元素称为一个状态;
– ∑是一个有穷字母表,每个元素称为一个输入符号,所以也称∑为输入符号字母表;
– f是状态转换函数,是定义在S×∑→S上的单值映射,即
若f(q1,a)=q2,表示在当前状态为q1,输入符为a时,将转换为下一个状态q2,q2称作q1的后继状态;
– S0∈S是唯一的初态;
– Z∈s是一个终态集,终态也称可接受状态或结束状态。
1.1 状态转换矩阵
DFA可以用一个矩阵表示:
行:表示状态q;
列:表示输入字符a;
矩阵元素:在q状态下读入输入符a时应转换到的下一个状态,即f(q,a)的值;
| 状态\输入符 | a | b |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 2 |
| 2 | 1 | 3 |
| 3 | 3 | 3 |
1.2 状态转换图
DFA可以用一张(确定的)状态转换图表示:
结点: 表示状态,用圆圈圈起来;

箭弧v→:表示状态转移的方向;

上面状态转换矩阵表示的状态转换图:
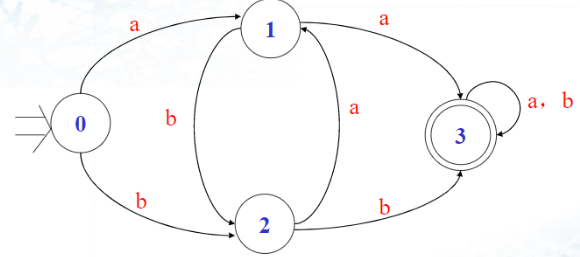
1.3 识别字符串
若存在一条从初态结点到某一终态结点的通路,且这条通路上所有箭弧的标记符连接成的字符串等于α,则称串α为DFAM所识别(读出或接受)。
若M的初态结点同时又是终态结点,则为空字ε可为M所识别。
1.4 语言集
DFA M所能识别的字符串的全体记为L(M).
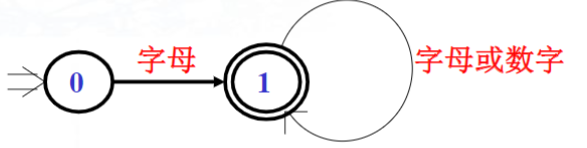
1.标识符的DFA
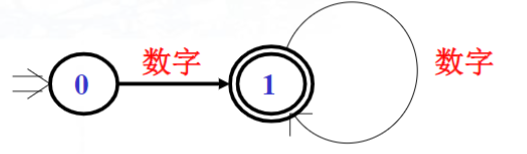
2.无符号整数的DFA
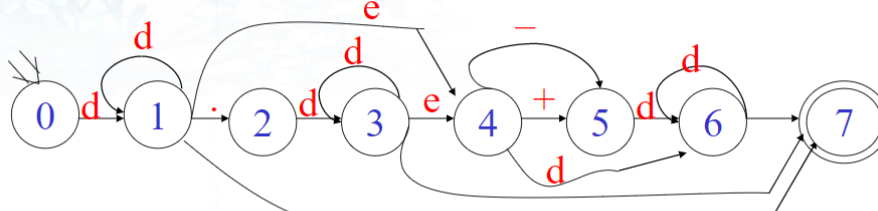
3.无符号实数的DFA
2 不确定的有穷自动机NFA
NFA定义:
不确定的有穷自动机NFA M是一个五元组:M=(S,∑,f, S0,Z),其中:
– S是一个有穷状态集,每个元素称为一个状态;
– ∑是一个有穷字母表,每个元素称为一个输入符号;
– f是状态转换函数,是定义在S×∑→2^S上的多值映射,即
若f(q1,a)={q2, q3},表示在当前状态为q1,输入符为a时,将转换为下一个状态q2和状态q3;
– S0∈S是初态集;
– Z∈s是一个终态集。
1 状态转换矩阵
| 状态\输入符 | a | b |
|---|---|---|
| 1 | {3} | {1, 2} |
| 2 | 空集 | {3} |
| 3 | 空集 | {2} |
2 状态转换图

3 识别
若存在一条从初态结点到某一终态结点的通路,且这条通路上所有箭弧的标记符连接成的字符串等于α,则称串α为DFAM所识别(读出或接受)。
4 语言集
上面状态转换图所识别的语言集为:
L(M) = b*(b|ab)(bb)*
1 标识符的NFA
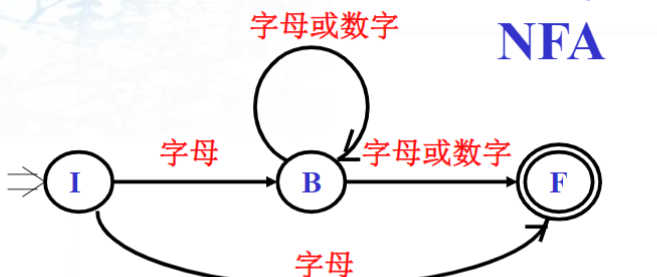
3 DFA与NFA的异同
- DFA是NFA的特例。
- 对于每个NFA M都一定存在一个DFA M’,使L(M)=L(M’)。即:对每个NFAM存在着与之等价的DFA M’。
- 与某一NFA等价的DFA不唯一。
2.3 用FA识别正规式–等价转换
(1)对于∑上的一个正规式r,可以构造一个∑上的NFA M,使得L(M)=L®。
(2)对于∑上的NFA M,可以构造一个∑上的正规式r ,使得L®=L(M)。
词法分析程序自动构造的典型过程:
正规式 —转换–> NFA --确定化–>DFA --化简–> 最小DFA
2.3.1 正规式转换为NFA
1、对于正规式空集Φ,所构造的NFA为:
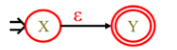
 2、对于正规式ε,所构造的NFA为:
2、对于正规式ε,所构造的NFA为:
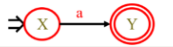
3、对于正规式a,所构造的NFA为:
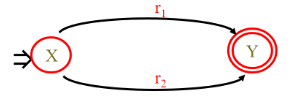
4、对于正规式r1r2,所构造的NFA为:

5、对于正规式r1|r2,所构造的NFA为:
6、对于正规式r1*,所构造的NFA为:
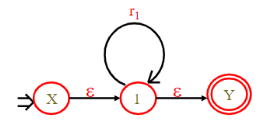
2.3.2 NFA转换为DFA
基本思路是:DFA的每一个状态对应NFA的一组状态。DFA使用它的状态去记录在NFA读入一个输入符号后可能达到的所有状态。
确定化方法∶状态子集法。
1 状态子集I的ε-闭包: ε-Closure(I)
(1) 若q∈I,则q∈ε-Closure(I);
(2)若q∈I,则从q出发经任意条ε弧而能到达的任何状态q’都属于ε-Closure(I)。
2 状态子集Ia = ε-Closure(J)
其中I是NFA M的一个状态子集,a∈∑,J是那些可从l中的某一状态结点出发经过一条a弧而到达的状态结点的全体。
3 NFA M’ 确定化为 DFA M
例

(a | b)*abb
1、求DFA的初态
I0 = ε-Closure({NFA的初态})
= ε-Closure({X})
= {X, 1, 2}
2、用状态子集法,求DFA M的状态集I中的其它状态,及状态转换函数f。
2.1 因为∑ = {a, b},所以只需要求Ia,Ib即可。
2.2 子集Ia,Ib,得到的新状态将添加到DFA的状态集l中;如此继续,直至不再产生新的状态为止。即可得到DFA的全部状态l和状态转换函数f。
//1 对初态I0 求状态子集
//{X, 1, 2} 通过a弧可以达到{1, 3}
//{1, 3}通过任意ε弧可以到达{1, 2, 3}
f(I0, a) = Ia = {X, 1, 2}a = ε-Closure({1, 3}) = {1, 2, 3}
//{X, 1, 2} 通过b弧可以达到{1}
//{1}通过任意ε弧可以到达{1, 2}
f(I0, b) = Ia = {X, 1, 2}b = ε-Closure({1}) = {1, 2}
所得{1,2,3}与{1,2}均是异于l0的新状态,因此将它们加入DFA的状态集Ⅰ中。
再继续对新状态{1,2,3} 与{1,2}利用状态子集法求其它的状态。
//2 对{1,2,3}求状态子集
//{1, 2, 3} 通过a弧可以达到{1, 3}
//{1, 3}通过任意ε弧可以到达{1, 2, 3}
{1, 2, 3}a = ε-Closure({1, 3}) = {1, 2, 3}
//{1, 2, 3} 通过b弧可以达到{1, 4}
//{1, 4}通过任意ε弧可以到达{1, 2, 4}
{1, 2, 3}b = ε-Closure({1, 4}) = {1, 2, 4}
所得{1,2,4}是新状态,因此将它加入DFA的状态集Ⅰ中。
//3 对{1, 2}求状态子集
//{1, 2} 通过a弧可以达到{1, 3}
//{1, 3}通过任意ε弧可以到达{1, 2, 3}
{1, 2}a = ε-Closure({1, 3}) = {1, 2, 3}
//{1, 2} 通过b弧可以达到{1}
//{1}通过任意ε弧可以到达{1, 2}
{1, 2}b = ε-Closure({1}) = {1, 2}
没有新状态
//4 对{1, 2, 4}求状态子集
//{1, 2, 4} 通过a弧可以达到{1, 3}
//{1, 3}通过任意ε弧可以到达{1, 2, 3}
{1, 2, 4}a = ε-Closure({1, 3}) = {1, 2, 3}
//{1, 2, 4} 通过b弧可以达到{1, Y}
//{1, Y}通过任意ε弧可以到达{1, 2, Y}
{1, 2, 4}b = ε-Closure({1, Y}) = {1, 2, Y}
所得{1,2,Y}是新状态,因此将它加入DFA的状态集Ⅰ中。
//5 对{1, 2, Y}求状态子集
//{1, 2, Y} 通过a弧可以达到{1, 3}
//{1, 3}通过任意ε弧可以到达{1, 2, 3}
{1, 2, Y}a = ε-Closure({1, 3}) = {1, 2, 3}
//{1, 2, Y} 通过b弧可以达到{1}
//{1}通过任意ε弧可以到达{1, 2}
{1, 2, Y}b = ε-Closure({1}) = {1, 2}
没有新状态产生,结束
以上五步如下图:

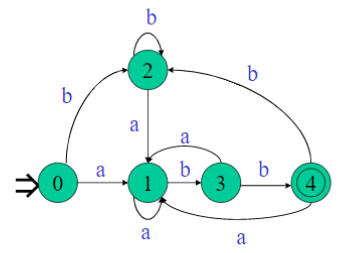
3、重新命名 以及确定终态集
包含原NFA的终态的子集都是DFA的终态。
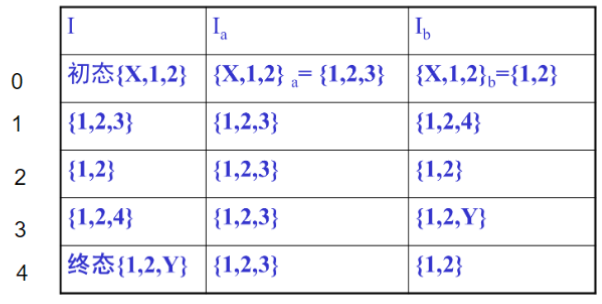
得到状态转换矩阵:

由状态转换矩阵,即得到DFA M:
2.3.3 DFA的化简
- 确定有穷自动机M的化简是指︰寻找一个状态数比DFAM少的DFA M’,使得L(M)= L(M‘)。
- 一个有穷自动机是化简了的,即是它没有多余状态,并且它的状态中没有两个是互相等价的。
- 一个有穷自动机可以通过消除多余状态和合并等价状态而转换成一个最小的与之等价的有穷自动机。
DFA的最小化就是寻求最小状态DFA
1 最小状态DFA的含义
-
没有多余状态(死状态)
(多余状态指:从有穷自动机的初态出发,
任何输入串也不能到达的那个状态;
或者从这个状态没有通路到达终态。) -
没有两个状态是互相等价的(不可区别)
2 两个状态s和t可区别
- 兼容性——同是终态或同是非终态
- 传播性——从s出发读入某个a(ae>)和从 t出发读入某个a到达的状态等价。
3 DFA的最小化过程:分割法
确定有限自动机M的化简的过程也就是其状态最少化过程︰
一个DFA M的状态最少化过程是指将M的状态集分割成一些不相交的子集,使得任何不同的两子集中的状态都是可区别的,而同一子集中的任何两个状态都是等价的。最后,在每个子集中选出一个代表,同时消去其它等价状态。
例:
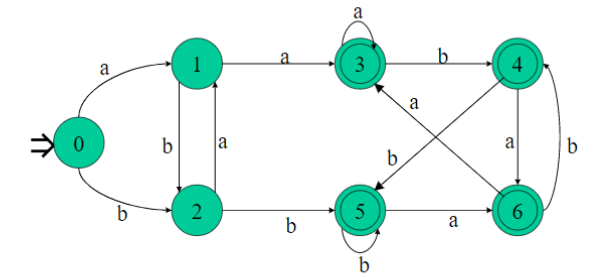
DFA的状态集k ={0,1,2 ,3,4,5,6}
1、首先把M的状态K分为两组:
终态集K1={3,4,5,6}
非终态集K2={0,1,2}
显然K1与K2不等价。
2、分割状态集
然后,试图K1,K2在中寻找一个子集和一个输入符号使得这个子集中的状态可区别的﹔若可区别,则再分割;继续,一直到不能再分割为止。
//1 讨论终态集K1={3,4,5,6}是否可分割:
{3,4,5,6}a ⊂ K,
{3,4,5,6}b ⊂ K1
所以状态3,4,5,6均等价,因此K,不能再分割。
//2 讨论非终态集K,={0,1,2}是否可分割︰
{0, 1, 2}a = {1, 3}
它既不属于K2={0, 1, 2},也不属于K= {3, 4, 5, 6},因此应将其一分为二:
{0, 2}a = {1}
{1}a = {3}
由于1态经a弧到达3态,而且状态0,2经a弧到达1态,所以将1状态分出来,形成
K21={1}
K22={0,2}
//3 再讨论K2={0,2}是否可分割:
{0, 2}b = {2, 5}
而它未包括在K1,K21与K22中,故{0,2}应一分为二∶
K221={0}
K222={2}
所以K分为四组{3,4,5,6},{0},{1},{2}。每个组都不可再分。
3、最后,在每个子集中选出一个代表,同时消去其它等价状态
令状态3代表{3,4,5,6}。把原来到达4,5,6的弧都导入3,并删除4,5,6状态。即可得到化简后的DFA。
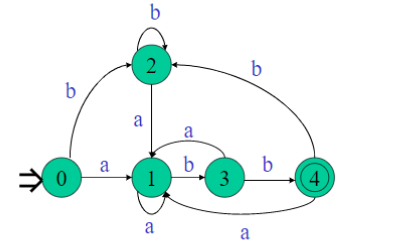
2.4 用FA识别正规文法–等价转换
对于正规文法G和有穷自动机FA M,如果L(G)=L(M),则称G和M等价。
2.4.1 正规文法转换为NFA
右线性文法的转换方法
- 引入一个终态F。
//设右线性文法
G = ( Vn, Vt, P, S),
//则相应的自动机为
M = (Vn U {F}, Vt, f, S, {F)。
//状态转换函数f由以下规则定义︰
1.P中形如A→aB的产生式,则有f(A,a)=B;
2.P中形如A→a的产生式,则有f(A,a)=F ;
3.对Vt中的每个a,都有f(F,a)= 空集。
例
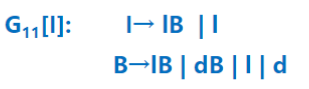


2.4.2 NFA确定化为DFA
同上
2.4.3 化简DFA
同上















 244
244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









