







 本文简要介绍了概念主题模型(PTM)中的两个关键模型:PLSA(概率潜在语义分析)和LDA(潜在狄利克雷分配)。PLSA是LSA的改进,解决了LSA的统计学基础问题,而LDA则在PLSA的基础上引入了贝叶斯框架,通过Dirichlet分布作为先验,使得参数估计更精确。文章探讨了这两个模型的原理、优缺点以及它们在自然语言处理中的应用。
本文简要介绍了概念主题模型(PTM)中的两个关键模型:PLSA(概率潜在语义分析)和LDA(潜在狄利克雷分配)。PLSA是LSA的改进,解决了LSA的统计学基础问题,而LDA则在PLSA的基础上引入了贝叶斯框架,通过Dirichlet分布作为先验,使得参数估计更精确。文章探讨了这两个模型的原理、优缺点以及它们在自然语言处理中的应用。
概念主题模型(PTM, probabilitytopical model)在自然语言处理(NLP,natural language processing)中有着重要的应用。主要包括以下几个模型:LSA(latentsemantic analysis)、 PLSA(probability latent semantic analysis)、LDA(latentdirichlet allocation)和HDP(hirerachical dirichlet processing),这里用一张图给出它们的发展历程。此记主要记录PLSA和LDA模型.

PLSA:
PLSA是在LSA的基础上发展起来的,因为LSA有以下缺点:(1)svd奇异值分解对数据的变化较为敏感,同时缺乏先验信息的植入等而显得过分机械。(2)缺乏稳固的数理统计基础(奇异值分解物理意义,如何从数学上推导得出高维降到的低维语义结构空间),此外svd分解比较耗时。基于以上两个原因,提出了PLSA(概率潜在语义结构分析),这样我们就从概率的角度对LSA进行新的诠释,使得LSA有了稳固的统计学基础。
PLSA不关注词和词之间的出现顺序,所以pLSA是一种词袋方法(BOW: 一个文档用一个向量表示,向量中元素就是一个词出现与否或者是出现次数或者TF-IDF,各个词是否出现相互独立),具体说来,该模型假设一组共现(co-occurrence)词项关联着一个隐含的主题类别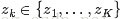
- P(di)表示海量文档中某篇文档被选中的概率。
- P(wj|di)表示词wj在给定文档di中出现的概率。
- 怎么计算得到呢?针对海量文档,对所有文档进行分词后,得到一个词汇列表,这样每篇文档就是一个词语的集合。对于每个词语,用它在文档中出现的次数除以文档中词语总的数目便是它在文档中出现的概率P(wj|di)。
- P(zk|di)表示具体某个主题zk在给定文档di下出现的概率。
- P(wj|zk)表示具体某个词wj在给定主题下出现的概率zk,与主题关系越密切的词,其条件概率P(wj|zk)越大。
利用上述的第1、3、4个概率,我们便可以按照如下的步骤得到“文档-词项”的生成模型:
- 按照概率P(di)选择一篇文档di
- 选定文档di后,从主题分布中按照概率P(zk|di)选择一个隐含的主题类别zk
- 选定zk后,从词分布中按照概率P(wj|zk)选择一个词wj
这样可以根据大量已知的文档-词项信息P(wj|di),训练出文档-主题P(zk|di)和主题-词项P(wj|zk),如下公式所示:
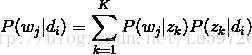
故得到文档中每个词的生成概率为:
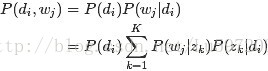
由于P(di)可事先计算求出,而P(wj|zk)和P(zk|di)未知,所以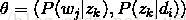
我们使用最大似然估计得到:

这里:n(di,wj)表示词项wj在文档di中词频,n(di)表示文档di中词的总数。M表示文档数量,N表示单词数量
其对数似然估计为:
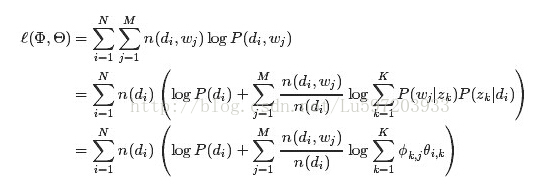
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 44
44

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









