







1、首选必须要去了解,目前几种常用的编码方案。其实编码的本质就是系统中存放了一张表,那张表就是一串二进制数到字符的映射。

说明:ASCII编码适合于英文文档的编码。Unicode编码适合于很多语言的编码。Unicode使用32位来表示字符,要求文本中每个字符占4个字节,比较浪费空间。
UTF-8:Unicode Transformation Format-8bit,允许含BOM,但通常不含BOM。是用以解决国际上字符的一种多字节编码,它对英文使用8位(即一个字节),中文使用24位(三个字节)来编码。UTF-8包含全世界所有国家需要用到的字符,是国际编码,通用性强。UTF-8编码的文字可以在各国支持UTF8字符集的浏览器上显示。如,如果是UTF8编码,则在外国人的英文IE上也能显示中文,他们无需下载IE的中文语言支持包。
下面介绍几种常用的编码方式:
GBK是国家标准GB2312基础上扩容后兼容GB2312的标准。GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示,为了区分中文,将其最高位都设定成1。GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBK大。
GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换:
GBK、GB2312<===>Unicode<===>UTF8。这一点非常关键,就是两种不同的编码方式之间的互相转换,要通过Unicode编码作为桥梁。
说明:所有的编码方式都必须通过Unicode编码方式进行转化,Unicode编码是各种编码方式相互进行转化的一种方式。
========================================================================================
我出现的情况:

原始要输出的文本是包含中文的。
在python中输出,显示是乱码:
代码如下:
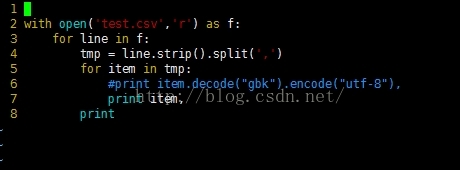
也就是说,中文在ubuntu系统下,采用的是utf-8编码的方式,如果,我们本来的文件采用的是GBK编码的方式,那么肯定是乱码。因为,print c操作的前提,是将文本读入内存,读入中文,也是读入一串二进制数,该二进制数是按照GBK进行编码的,现在print的时候,按照utf-8进行解码,肯定会出错。
查一下,原来的文本文件的编码方式,使用notepad++进行查询。

说明:右下角显示,是采用GBK编码,记住任何一种编码方式,都是要编码所有字符,包括中文,英文字符。
解决方案:其实很简单,就是将字符读入内存后,将GBK编码的结果转换为Unicode编码的结果,然后unicode编码的结果,再转化为utf-8编码。
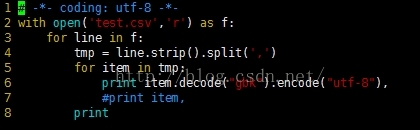















 7845
7845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









