







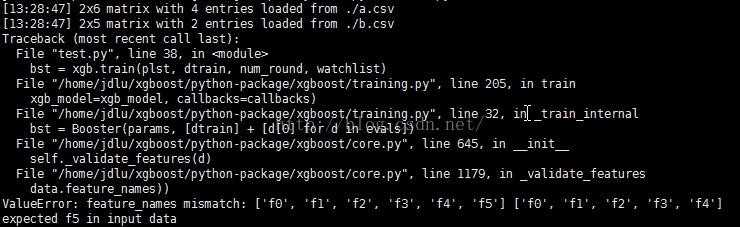
feature_names mismatch 的错误就是训练集和测试集的特征个数不一致导致的。
一、
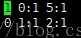
a.csv:最大小标是5。所以,训练集的特征维数就是6
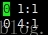
b.csv:最大小标是4。所以,训练集的特征维数就是5
所以,就是训练集和测试集的训练特征的维数不一致,就会报错。
二、
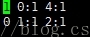
a.csv:最大小标是4。所以,训练集的特征维数就是5
b.csv:最大小标是5。所以,训练集的特征维数就是6
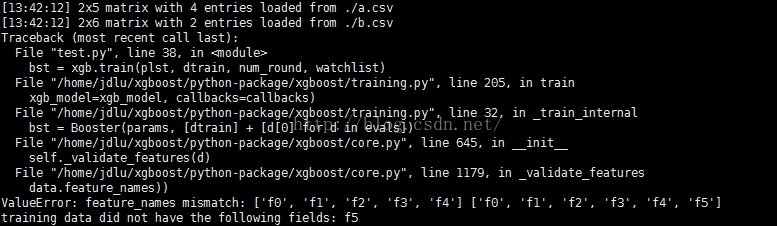
所以,对于XGBoost的训练数据和测试数据,要能够保证训练数据的特征数,也即特征编号的最大值跟测试数据的特征数一致。
说明:解决该错误的方法就是扩展,让训练集和测试集特征的最大编号一样,比如说,我们可以在每条训练样本的最后都假设"5000:0",前提是5000大于训练集和测试集特征的最大编号。那么,就需要分析,增加了5000:0对性能有影响吗,做了个小实验。
原始数据:
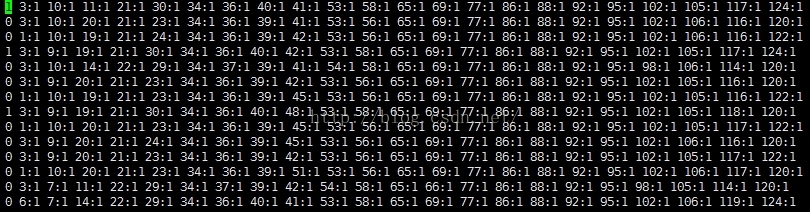
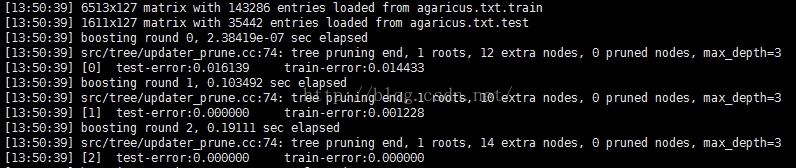
实验结果:
在末尾增加了10000:0后的数据:
实验结果:
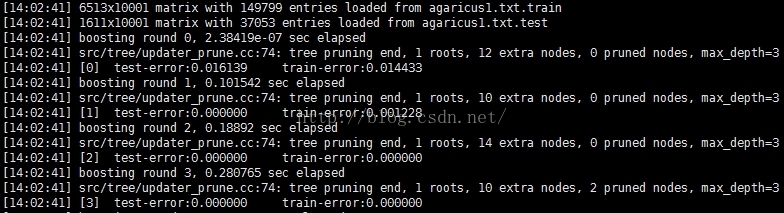
说明:增加了10000:0之后,训练过程并没有受到任何影响,该方法可行。















 4539
4539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









