







一、kNN算法分析
K最近邻(k-Nearest Neighbor,KNN)分类算法可以说是最简单的机器学习算法了。它采用测量不同特征值之间的距离方法进行分类。它的思想很简单:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
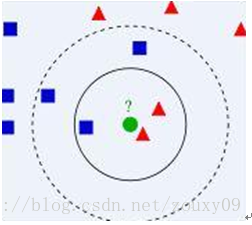
比如上面这个图,我们有两类数据,分别是蓝色方块和红色三角形,他们分布在一个上图的二维中间中。那么假如我们有一个绿色圆圈这个数据,需要判断这个数据是属于蓝色方块这一类,还是与红色三角形同类。怎么做呢?我们先把离这个绿色圆圈最近的几个点找到,因为我们觉得离绿色圆圈最近的才对它的类别有判断的帮助。那到底要用多少个来判断呢?这个个数就是k了。如果k=3,就表示我们选择离绿色圆圈最近的3个点来判断,由于红色三角形所占比例为2/3,所以我们认为绿色圆是和红色三角形同类。如果k=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。从这里可以看到,k的值还是很重要的。
KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。因此可以采用权值的方法(和该样本距离小的邻居权值大)来改进。该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分[参考机器学习十大算法]。
总的来说就是我们已经存在了一个带标签的数据库,然后输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似(最近邻)的分类标签。一般来说,只选择样本数据库中前k个最相似的数据。最后,选择k个最相似数据中出现次数最多的分类。其算法描述如下:
1)计算已知类别数据集中的点与当前点之间的距离;
2)按照距离递增次序排序;
3)选取与当前点距离最小的k个点;
4)确定前k个点所在类别的出现频率;
5)返回前k个点出现频率最高的类别作为当前点的预测分类。
二、Python实现
对于机器学习而已,Python需要额外安装三件宝,分别是Numpy,scipy和Matplotlib。前两者用于数值计算,后者用于画图。安装很简单,直接到各自的官网下载回来安装即可。安装程序会自动搜索我们的python版本和目录,然后安装到python支持的搜索路径下。反正就python和这三个插件都默认安装就没问题了。
2.1、kNN基础实践
一般实现一个算法后,我们需要先用一个很小的数据库来测试它的正确性,否则一下子给个大数据给它,它也很难消化,而且还不利于我们分析代码的有效性。
首先,我们新建一个kNN.py脚本文件,文件里面包含两个函数,一个用来生成小数据库,一个实现kNN分类算法。代码如下:
from numpy import *
"""
构造数据集
dataSet:数据集 多维数组表示(矩阵)
label:数据相应列标
"""
def createDataSet():
dataSet=array([[1.0, 0.9], [1.0, 1.0], [0.1, 0.2], [0.0, 0.1]])
label=['A','A','B','B']
return dataSet,label
"""
kNN算法实现
传入参数:
testData:需要计算出列标的数据
dataSet:训练集
labels:相应列标
k:指定k值
"""
def kNNClassify(testData,dataSet,labels,k):
samplesNum=shape(dataSet)[0]
"""
首先创建与训练集同样规模的 测试机矩阵 便于后面计算欧式距离
rows:samplesNum
"""
diff=tile(testData,(samplesNum,1))-dataSet
squareSum=sum(diff**2,axis=1)
sqrt=squareSum**0.5
"""
将得到的距离进行排序
利用argsort()排序得到 相应顺序的下标
"""
indices=argsort(sqrt)
"""
取前k个数据 进行统计
"""
classCount={}
for i in range(k):
voteLabel=labels[indices[i]]
classCount[voteLabel]=classCount.get(voteLabel,0)+1
maxNum=0
for label,num in classCount.items():
if(num>maxNum):
maxNum=num
maxLabel=label
return maxLabel
输出为:
Your input is: [ 1.2 1. ] and classified to class: A
Your input is: [ 0.1 0.3] and classified to class: B
2.2、kNN进阶
这里我们用kNN来分类一个大点的数据库,包括数据维度比较大和样本数比较多的数据库。这里我们用到一个手写数字的数据库,可以到这里下载。这个数据库包括数字0-9的手写体。每个数字大约有200个样本。每个样本保持在一个txt文件中。手写体图像本身的大小是32x32的二值图,转换到txt文件保存后,内容也是32x32个数字,0或者1,如下:
数据库解压后有两个目录:目录trainingDigits存放的是大约2000个训练数据,testDigits存放大约900个测试数据。
这里我们还是新建一个kNN.py脚本文件,文件里面包含四个函数,一个用来生成将每个样本的txt文件转换为对应的一个向量,一个用来加载整个数据库,一个实现kNN分类算法。最后就是实现这个加载,测试的函数。
具体代码:
from numpy import *
import kNN
import os
"""
将每张图片转换成多维数组的形式
即读取每个文件--> vector
"""
def img2vec(filename):
rows=32
cols=32
imgvec=zeros((1,1024))
fp=open(filename)
for row in xrange(rows):
lines=fp.readline()
for col in xrange(cols):
imgvec[0,row*32+col]=int(lines[col])
return imgvec
"""
加载训练集和测试集
traingDataDir:训练集目录
testDataDir:测试机目录
"""
def loadDataSet(traingDataDir,testDataDir):
print 'loading traing files...'
trainfiles=os.listdir(traingDataDir)
traingNum=len(trainfiles)
print 'the num of traing files is: ',traingNum
print 'loading test files...'
testfiles=os.listdir(testDataDir)
testNum=len(testfiles)
print 'the num of test files is: ',testNum
traingData=zeros((traingNum,1024))
traingLabels=[]
testData=zeros((testNum,1024))
testLabels=[]
for i in xrange(traingNum):
filename=trainfiles[i]
traingData[i,:]=img2vec(traingDataDir+'\\'+filename)
traingLabels.append(filename.split('_')[0])
for i in xrange(testNum):
filename=testfiles[i]
testData[i,:]=img2vec(testDataDir+'\\'+filename)
testLabels.append(filename.split('_')[0])
return traingData,traingLabels,testData,testLabels
"""
计算预测准确率
"""
def predict(traingDataDir,testDataDir):
traingData,traingLabels,testData,testLabels=loadDataSet(traingDataDir,testDataDir)
k=10
print 'start predict...'
testNum=testData.shape[0]
corNum=0
for i in xrange(testNum):
voteLabel=kNN.kNNClassify(testData[i],traingData,traingLabels,k)
if voteLabel==testLabels[i]:
corNum+=1
precison=float(corNum)/testNum
print 'the testNum is: %d, the correctNum is: %d ' %(testNum,corNum)
print 'the precision is: %.2f %%' %(precison*100)
测试:
handWritingClassifier.predict(‘D:\python_study\KNN\trainingDigits’,’D:\python_study\KNN\testDigits’)
输出:
loading traing files…
the num of traing files is: 1934
loading test files…
the num of test files is: 946
start predict…
the testNum is: 946, the correctNum is: 926
the precision is: 97.89 %















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









