







kNN(k-nearest neighbor)是一种基本的分类与回归的算法。这里我们先只讨论分类中的kNN算法。
k邻近算法的输入为实例的特征向量,对对应于特征空间中的点;输出为实例的类别,可以取多类,k近邻法是建设给定一个训练数据集,其中的实例类别已定,分类时,对于新的实例,根据其k个最邻近的训练实例的类别,通过多数表决等方式进行预测。所以可以说,k近邻法不具有显示的学习过程。k临近算法实际上是利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”
k值的选择,距离的度量和分类决策规则是k近邻算法的三个基本要素。
这里需要说明的是,对于距离的度量,我们有很多种度量方法可以选择,如欧氏距离(2-范数),曼哈顿距离(1-范数),无穷范数等,根据不同的实例,我们可以选择不同的距离度量方法。
下面给出了利用python和sklearn库实现的kNN算法的过程及部分注释:
# coding=utf-8
# 首先利用sklearn的库进行knn算法的建立与预测
# from sklearn import neighbors
# from sklearn import datasets
#
# knn = neighbors.KNeighborsClassifier() # 调用分类器赋在变量knn上
#
# iris = datasets.load_iris() # 返回一个数据库,赋值在iris上
#
# print iris # 显示这个数据集
#
# knn.fit(iris.data, iris.target) # fit的第一个参数 是特征值矩阵,第二个参数是一维的向量
#
# predictedLabel = knn.predict([[0.1,0.2,0.3,0.4]])
#
# print predictedLabel
# 下面自己写一个程序实现knn算法
import csv
import random
import math
import operator
# filename是指文件名,split是某一个数字,数字前的数据当做训练集,数字后的数据当做测试集
# trainingSet是训练集,testSet是测试集
# 函数作用,加载文件,并将文件通过随机数的方法分为训练集和测试集
def loadDataset(filename, split, trainingSet=[], testSet=[]):
with open(filename, 'rb') as csvfile: # 导入文件为csvfile格式
lines = csv.reader(csvfile) # 读取所有的行 reader函数的作用
dataset = list(lines) # 将所有的行转换为list的数据节后
for x in range(len(dataset)-1): # x在总共的行数中遍历
for y in range(4):
dataset[x][y] = float(dataset[x][y])
if random.random() < split:
trainingSet.append(dataset[x])
else:
testSet.append(dataset[x])
# 函数作用:计算欧氏距离
# 函数的输入是两个实例和他们的维度
def euclideanDistance(instance1, instance2, length):
distance = 0
for x in range(length): # 对于每一个维度内进行一个差的计算,计算出所有维度的平方和
distance += pow((instance1[x] - instance2[x]),2)
return math.sqrt(distance)
# 函数作用:返回最近的k的neightbor
# 也就是返回在trainingSet中距离testInstance最近的k个邻居
def getNeigthbors(trainingSet, testInstance, k):
distances =[] # 距离的容器,用来存放所有的距离值
length = len(testInstance) - 1 # 用来存放testInstance的维度
for x in range(len(trainingSet)):
# 对于每一个x 计算训练集中的数据与实例的距离
dist = euclideanDistance(testInstance,trainingSet[x],length)
distances.append((trainingSet[x],dist))
# 把这些距离从小到大排起来
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k):
neighbors.append(distances[x][0])
return neighbors # 返回最近的邻居
def getResponse(neighbors):
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.iteritems(),key=operator.itemgetter(1),reverse=True)
return sortedVotes[0][0]
# 用来检验预测结果的正确率
def getAccuracy(testSet,predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]: # [-1]值的是最后一个值,也就是每行的最后的值,即为花的分类
correct += 1
return (correct/float(len(testSet))) * 100.00
def main():
# prepare data
trainingSet = []
testSet = []
split = 0.67
loadDataset('irisdata.txt',split,trainingSet,testSet) # r的作用是防止错误字符串意思
print 'Train Set' + repr(len(trainingSet))
print 'Test Set' + repr(len(testSet))
# generate predicitions
predicitions = []
k = 3
for x in range(len(testSet)):
neighbors = getNeigthbors(trainingSet,testSet[x],k)
result = getResponse(neighbors)
predicitions.append(result)
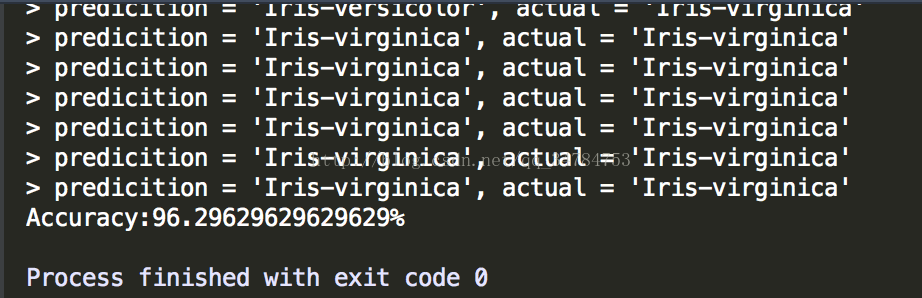
print('> predicition = ' + repr(result) + ', actual = ' +repr(testSet[x][-1]))
accuracy = getAccuracy(testSet,predicitions)
print('Accuracy:' + repr(accuracy) + '%')
main()















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









