







hadoop3.0高可用HA大数据平台架构硬件和部署方案(一)
http://blog.csdn.net/lxb1022/article/details/78389836
http://blog.csdn.net/lxb1022/article/details/78389836
hadoop3.0高可用HA大数据平台架构软件和部署方案(二)
http://blog.csdn.net/lxb1022/article/details/78399462
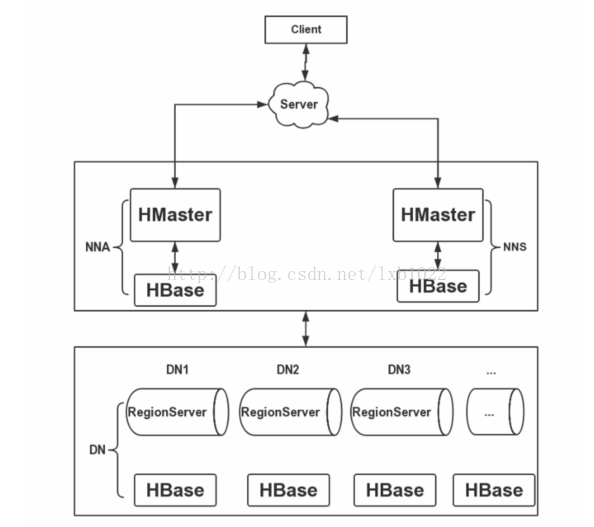
在搭建HBase高可用集群时,将HBase的RegionServer部署在HDFS的N个DataNode节点上,HBase的HMaster服务部署在HDFS的2个NameNode(Active和Standby)节点上,部署2个HMaster保证集群的高可用性,防止单点问题。这里使用了独立的ZooKeeper集群,未使用HBase自带的ZooKeeper。下面给出HBase的集群搭建架构图:
1、到官网下载hbase-2.0.0-alpha3-bin.tar.gz
https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/2.0.0-alpha-3/
2、复制到安装目录/opt/,并解压
tar -zxvf hbase-2.0.0-alpha3-bin.tar.gz
3、修改环境变量:/opt/hbase-2.0.0-alpha3/conf/hbase-env.sh
export JAVA_HOME=/opt/jdk1.8.0_144
export HADOOP_HOME=/opt/hadoop-3.0.0-beta1
export HADOOP_CONF_DIR=/opt/hadoop-3.0.0-beta1/etc/hadoop
export HBASE_MANAGES_ZK=false
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
<description>设置HRegionServers共享目录</description>
</property>
<property>
<name>hbase.master</name>
<value>60000</value>
<description>设置HMaster的rpc端口</description>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
<description>设置HMaster的http端口</description>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/opt/hbase-2.0.0-alpha3/tmp</value>
<description>指定缓存文件存储的路径</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>开启分布式模式</description>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>zookeeper1:2181,zookeeper2:2181,zookeeper:2181</value>
<description>指定ZooKeeper集群位置</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/zookeeper-3.5.3-beta/data</value>
<description>指定Zookeeper数据目录,需要与ZooKeeper集群上配置相一致</description>
</property>
</configuration>
5、配置:/opt/hbase-2.0.0-alpha3/conf/regionservers
datanode1
datanode2
datanode37、启动zookeeper,hdfs,hbase集群
/opt/zookeeper-3.5.3-beta/bin/zkServer.sh start
/opt/hadoop-3.0.0-beta1/sbin/start-all.sh
/opt/hbase-2.0.0-alpha3/bin/start-hbase.sh #namdenode1,namdenode2都要启动namenode1,nanenode2进程
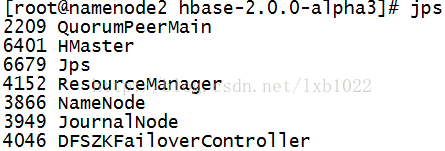
datanode的进程

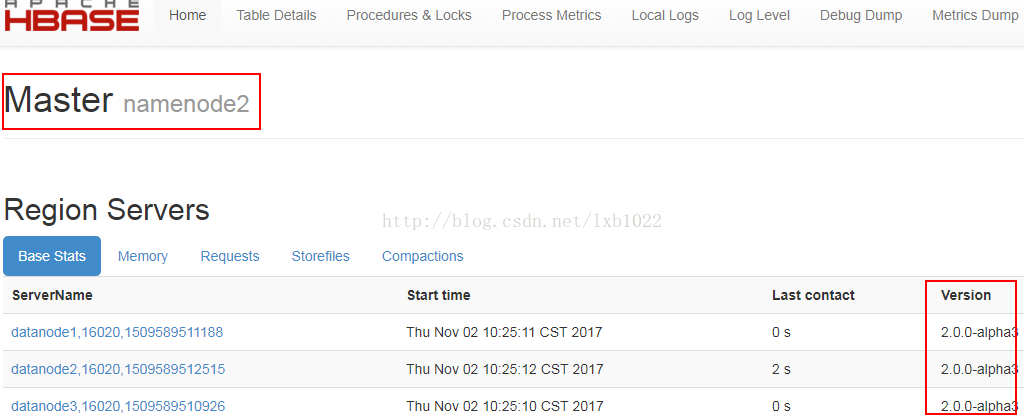
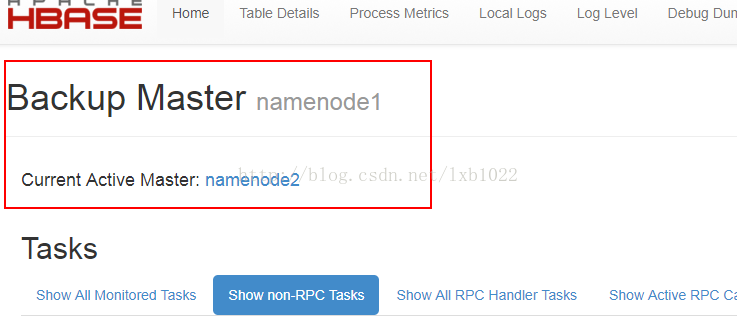
9、查看web界面:














 796
796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









