







Hadoop及相关组件搭建指导WeChat:h19396218469
在本次操作中使用的软件版本分别为
hadoop-3.1.3
jdk-8u162-linux-x64
hbase-2.2.2-bin
zookeeper-3.4.6
本案例软件包:链接:https://pan.baidu.com/s/1ighxbTNAWqobGpsX0qkD8w
提取码:lkjh(若链接失效在下面评论,我会及时更新)
一、HBase的安装
1、解压HBase安装包
cd Downloads
sudo tar -zxvf hbase-2.2.2-bin.tar.gz -C /usr/local
2、切换到HBase解压的文件夹,修改名字
cd /usr/local
sudo mv hbase-2.2.2 hbase
3、修改HBase文件夹权限
sudo chown -R hadoop /usr/local/hbase
4、配置HBase环境变量
sudo vim /etc/profile
在下面添加
export HBASE_HOME=/usr/local/hbase #这里是HBase的存放目录根据自己情况修改
export PATH=$PATH:$HBASE_HOME/bin
使环境变量生效
source /etc/profile
二、HBase的伪分布式
1、修改hbase-env.sh
cd /usr/local/hbase/conf
sudo vim hbase-env.sh
将里面
export JAVA_HOME=/usr/local/jdk1.8.0/
替换为自己的java版本
export JAVA_HOME=/usr/local/jdk1.8.0_162
修改export HBASE_CLASSPATH=为
export HBASE_CLASSPATH=/usr/local/hbase/conf
将export HBASE_MANAGES_ZK=修改为
export HBASE_MANAGES_ZK=true
将以上改的三行#去掉,即取消注释。
2、修改hbase-site.xml文件
在 其中添加如下信息
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
3、测试
首先启动hadoop集群
start-dfs.sh
start-yarn.sh
或者
start-all.sh
如果start-all.sh无法全部启动,可以去我的另一篇博客Hadoop的完全分布式配置下面写了如何写脚本使Hadoop集群一键启动,大家可以根据需要编写
start-hbase.sh
1、使用命令jps查看进程
如图
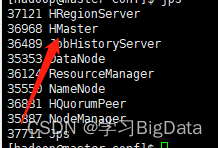 2、用浏览器打开HBase自带的web网站查看
2、用浏览器打开HBase自带的web网站查看
http://192.168.64.133:16010这里使用自己的ip地址
如图所示即为配置成功
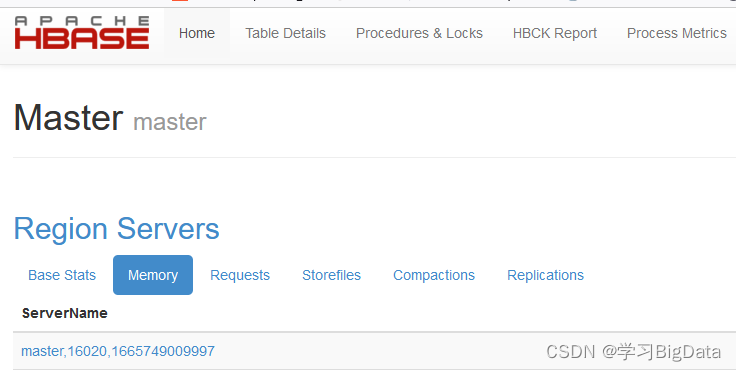
出现HMaster即为HBase的伪分布式配置成功。
三、HBase的完全分布式配置
完成此步骤需要
1、配置独立的外部ZooKeeper集群,不使用HBase内置的ZooKeeper。
2、由于依赖于HDFS存储数据,因此部署HBase的完全分布式之前必须有一个正常运行的HDFS集群。(Hadoop集群)
以上两步没有配置的可以去我的另两篇博客配置Hadoop的完全分布式搭建ZooKeeper的完全分布式搭建
1、首先需要将HBase的压缩包上传到两个从节点slave01和slave02中
这里一定要上传到slave01和slave02中,如果是采用master全部配置完成再复制分发到slave01和slave02中会缺少一些包
使用xftp上传到slave01和slave02的Downloads中,xftp的使用在xftp和xshell的使用中有写。
首先在slave01和slave02中使用命令解压
cd ~
cd Downloads
sudo tar -zxvf hbase-2.2.2-bin.tar.gz -C /usr/local
2、修改HBase名称
cd /usr/local
sudo mv hbase-2.2.2 hbase
3、增加权限
sudo chown -R hadoop:hadoop /usr/local/hbase
4、配置环境变量
sudo vim /etc/profile
在最后一行添加如下信息
export HBASE_HOME=/usr/local/hbase
export PATH=$PATH:$HBASE_HOME/bin
使用命令初始化
source /etc/profile
5、修改hbase-env.sh文件
cd /usr/local/hbase/conf
sudo vim hbase-env.sh
找到其中的export HBASE_MANAGES_ZK=true,将true修改为false
此行为设置HBase启动不使用HBase内部的ZooKeeper
将里面export JAVA_HOME=/usr/local/jdk1.8.0/
替换为自己的java版本
export JAVA_HOME=/usr/local/jdk1.8.0_162
修改export HBASE_CLASSPATH=为
export HBASE_CLASSPATH=/usr/local/hbase/conf
6、修改hbase-site.xml参数
这里的端口号需要注意,如果是按照我的第八篇博客Hadoop的HA模式完全分布式搭建中的内容搭建的Hadoop集群,需要将端口号修改为8020
将 中间修改为如下内容
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave01,slave02</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
hbase.rootdir:用于指定HBase在HDFS的存储路径,此处端口号必须与Hadoop的配置文件core-site.xml中的端口号保持一致
hbase.zookeeper.quorum:对于HBase的完全分布式模式(使用外部的独立ZooKeeper集群),应将该参数的值设为外部的独立ZooKeeper集群的完整主机列表,此时在配置文件hbase-env.sh中的HBASE_MANAGES_ZK参数必须为false
hbase.cluster.distributed:设置为true,设置HBase按照完全分布式启动
7、修改regionservers文件
sudo vim regionservers
将其中的内容修改为如下内容:
master
slave01
slave02
8、将Hadoop的配置文件core-site.xml和hdfs-site.xml拷贝到HBase的配置文件目录中(由于HBase依赖于HDFS存储数据)
cp /usr/local/hadoop/etc/hadoop/core-site.xml /usr/local/hbase/conf
cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hbase/conf
9、将master中HBase的多个配置文件远程拷贝到另外两台虚拟机slave01和slave02
scp hbase-env.sh hbase-site.xml core-site.xml hdfs-site.xml regionservers slave01:/usr/local/hbase/conf
scp hbase-env.sh hbase-site.xml core-site.xml hdfs-site.xml regionservers slave02:/usr/local/hbase/conf
10、启动HBase
首先要启动ZooKeeper和Hadoop集群再启动HBase
zkServer.sh start #分别在三台虚拟机执行
start-dfs.sh
start-yarn.sh
start-hbase.sh
(在这里如果ZooKeeper想同时在三台虚拟机启动可以到ZooKeeper的完全分布式配置中翻到下面有脚本编写的方法。
如果Hadoop无法同时启动也可以去Hadoop的完全分布式搭建中查看脚本编写方法)
(1)启动之后执行
jps
查看进程是否启动成功
如图所示进程即为启动成功
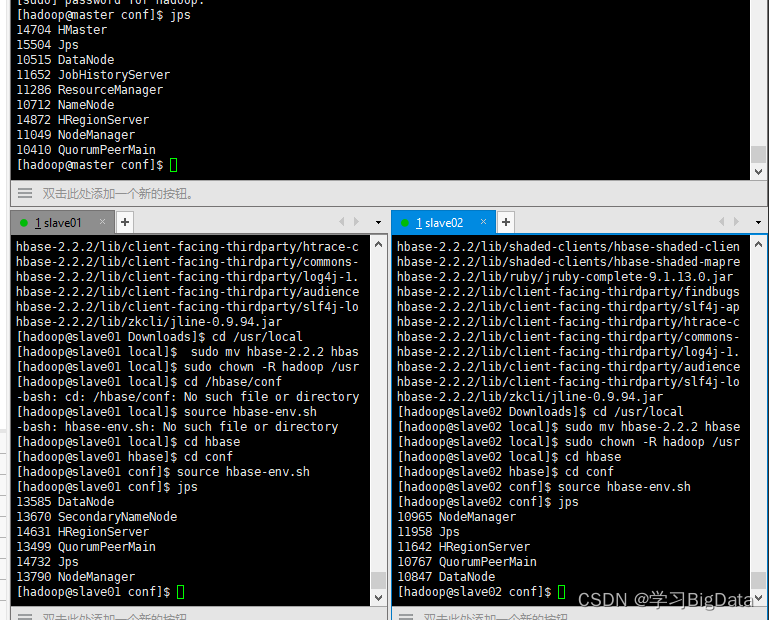
(2)使用浏览器访问HBase自带的web配置网站http://192.168.64.133:16010出现如下页面即为访问成功
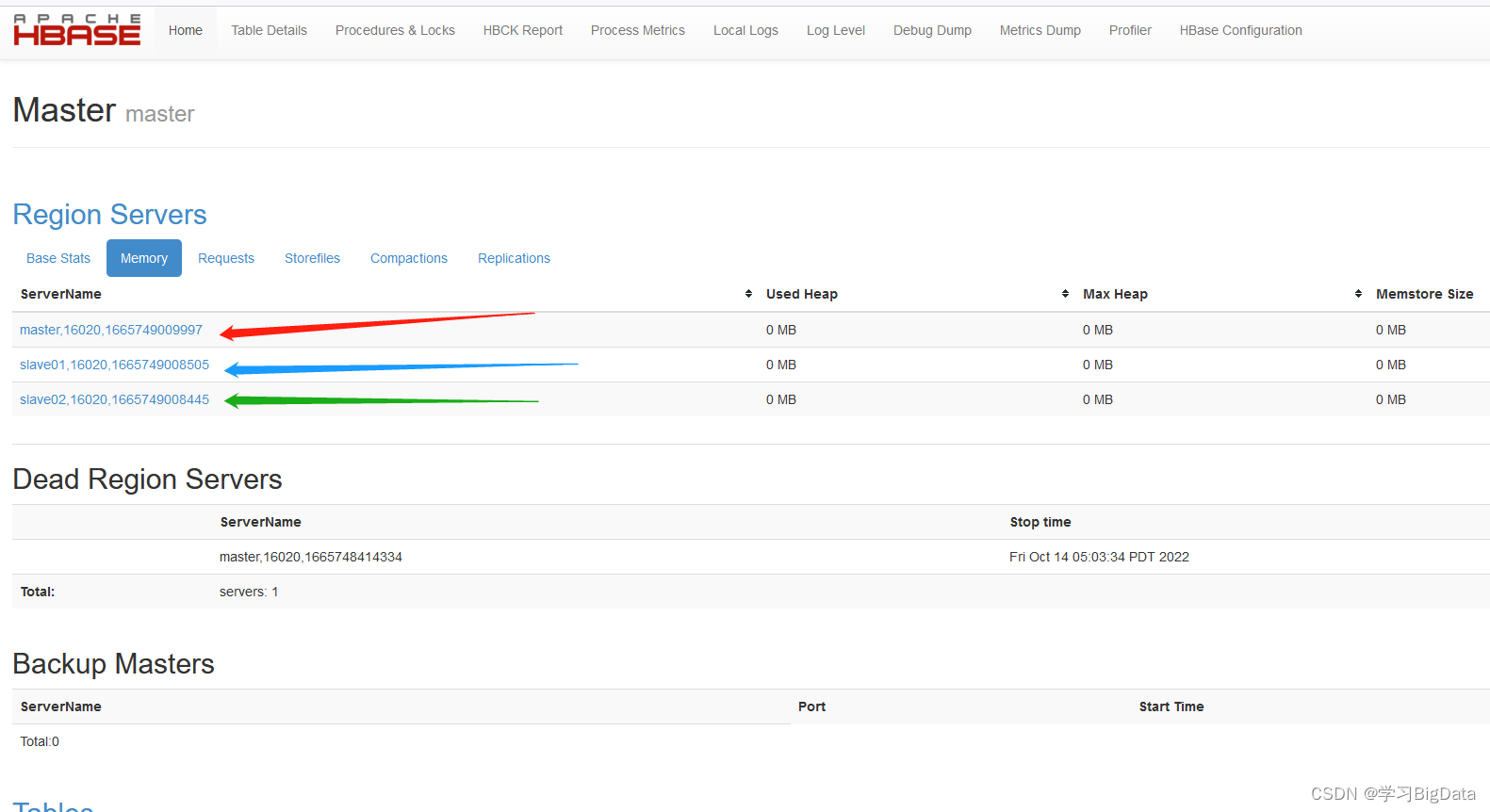 (3)检测一下HBase是否成功连接HDFS
(3)检测一下HBase是否成功连接HDFS
hadoop fs -ls /
检查是否存在hbase子目录
(4)进入hbase shell环境查看
hbase shell
使用如下命令查看状态
status
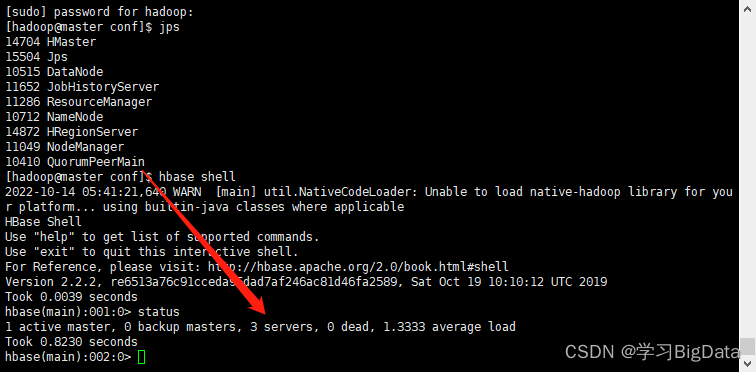 三台虚拟机配置三个节点。
三台虚拟机配置三个节点。
自此HBase完全分布式配置成功。
四、HBase的HA模式
1、首先停止HDFS集群和HBase集群
stop-hbase.sh
stop-dfs.sh
stop-yarn.sh
2、master主机创建配置文件backup-master
cd /usr/local/hbase/conf
sudo vim backup-masters
在其中添加
slave01
3、测试
(1)启动Zookeeper,Hadoop集群和HBase(启动命令前面提过很多次不再赘述)
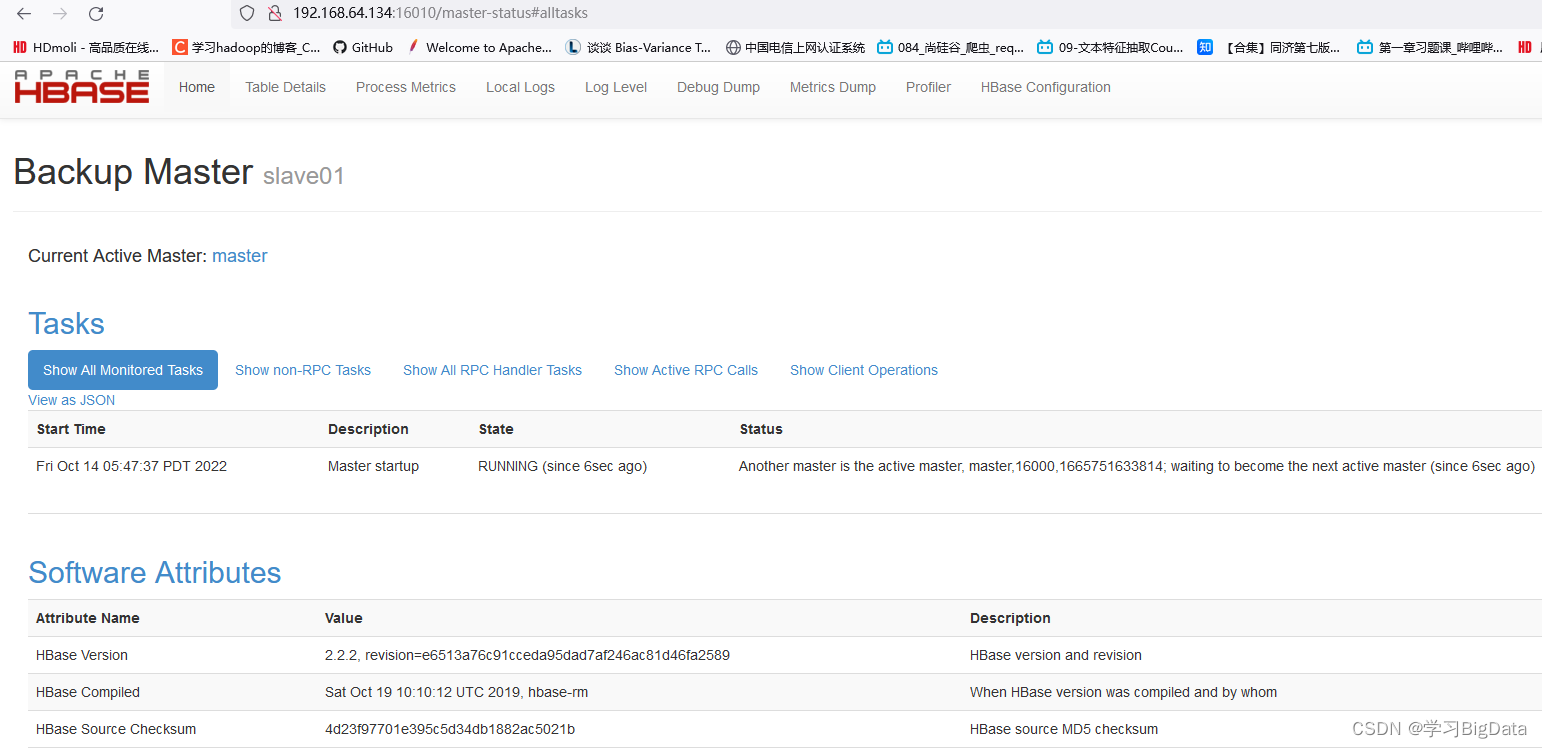
(2)使用浏览器查看HBase自带的web配置网站
http://192.168.64.133:16010
http://192.168.64.134:16010 此行为slave01的ip地址
出现如下图所示即为配置成功

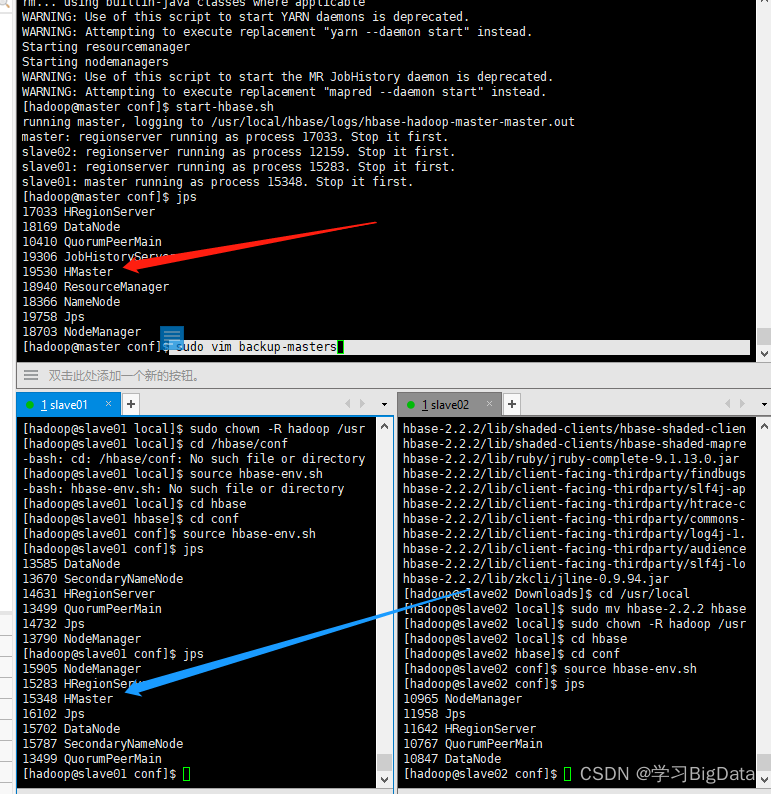
(3)分别在三台虚拟机执行jps,在master和slave01都出现了Hmaster进程,即为配置成功。
五、注意
在使用HBase时要先启动ZooKeeper再启动Hadoop最后启动HBase,
在关闭时要先关闭HBase再关闭Hadoop最后关闭ZooKeeper。
















 1516
1516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









