







OpenCV训练分类器制作xml文档(转)
在网上找了中文资料,发现大多都是转载那两篇文章,而且那两篇文章讲的都有误差,经过两天的摸索,我终于训练分类器成功了,在此与大家分享。
参考英文资料网址: http://note.sonots.com/SciSoftware/haartraining.html#e134e74e
整个过程分为两步:
1. 创建样本
2. 训练分类器
现在让我一一讲述。
1. 创建样本
◆ 样本分两种: 正样本与负样本(也有人翻译成:正例样本和反例样本),其中正样本是指待检目标样本(例如人脸,汽车,鼻子等),负样本指其它任意图片。
◆ 所有样本图片都应该有同一尺寸,如20 * 20,并放在相应文件目录下,
◆ 集合文件格式(collection file format)和描述文件格式(description file format)
集合文件格式(collection file format)就是如下形的描述文件:
[filename]
[filename]
[filename]
…
…
描述文件格式(description file format)就是如下形的描述文件:
[filename] [# of objects] [[x y width height] [... 2nd object] ...]
[filename] [# of objects] [[x y width height] [... 2nd object] ...]
[filename] [# of objects] [[x y width height] [... 2nd object] ...]
…
….
(x, y) 指左上角的坐标,width和 height 分别是样本的宽和高,这里我的图片是20*20的,所以两个值都是20
◆ 负样本用集合文件格式描述,正样本用描述文件格式描述!(这点网上很多文章都搞错了!)
▼创建样本步骤:
一. 把所有正样本图片放在posdata的文件夹下,把所有负样本图片放在negdata文件夹下
(这里我以人脸图片样本为例)
(注:以上这些 20*20 的图片均来自MIT人脸库,可以在csdn下载)
二. 分别为正样本和负样本创建描述文件
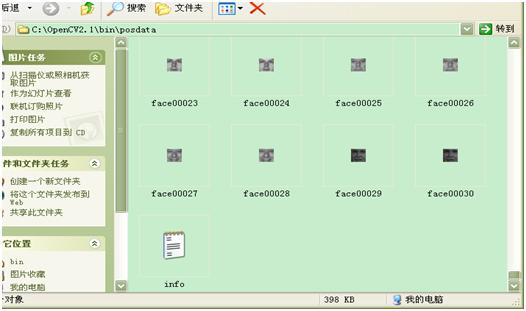
A. 为正样本创建描述文件格式文件info.txt,并且把这个文件放在与样本图片同一目录下,例如我的目录为C:/OpenCV2.1/bin/posdata
a) 在命令行下 输入以下命令: dir /b > info.txt

b) 打开info.txt, 按ctrl+h, 把所有的bmp 换成 bmp 1 0 0 20 20
c) 删除info.txt最后一行的 “info.txt”
d) 结果如下:

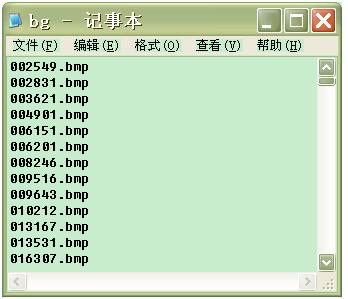
B. 为负样本创建集合文件格式文件bg.txt, 并且把这个文件放在与样本图片同一目录下,例如我的目录为I:/negdata
a) 在命令行下 输入以下命令: dir /b > bg.txt
b) 删除bg.txt最后一行的 “bg.txt”
c) 结果如下:

三. 创建样本。
Opencv 自带有创建样本的exe 文件,在 …/OpenCV2.1/bin 目录下, 这里我创建10个sample:
命令是: opencv_createsamples.exe -info C:/OpenCV2.1/bin/posdata/info.txt -vec a.vec -num 10 -w 20 -h 20
如图:

结果如图:
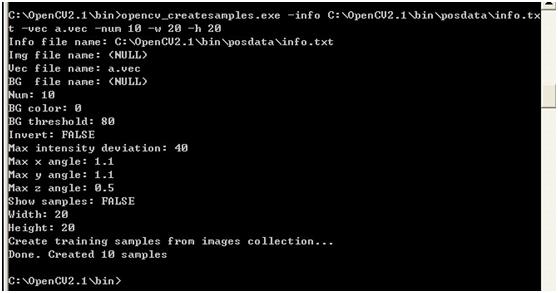
(关于 opencv_createsamples.exe 的参数用法,在参考英文资料网址http://note.sonots.com/SciSoftware/haartraining.html#e134e74e,里有详细介绍;
需要说明的是,我这里用的参数并没有 –bg, 因为根据那份文档,有了 –vec 和 –info 之后,就表示:Create training samples from some (从很多正样本中创建sample, 没有distortions)
经历千辛万苦,我们终于看到sample被创建成功了,接下来的工作就简单多了
▼训练分类器
还是在…/OpenCV2.1/bin目录下,输入命令:
opencv_haartraining.exe -data data -vec C:/OpenCV2.1/bin/a.vec -bg I:/negdata/bg.txt -npos 250 -nneg 800 -nstages 4 -nsplits 2 -mem 512 -nonsym -w 20 -h 20 -minpos 100

回车
(注意:
1. 参数-vec 一定要是刚刚创建样本产生的a.vec,且把完整路径也写上去,我试过用相对路径,但总会训练失败; bg.txt 也要用绝对路径;
2. –w 和 –h 都要写上与样本大小的一致的尺寸
3. 若遇到“内存什么不能read”的问题,很有可能是bg.txt的格式有误,回去
4. 关于 opencv_haartraining.exe 的参数用法,在参考英文资料网址
http://note.sonots.com/SciSoftware/haartraining.html#e134e74e,里有详细介绍
)
结果如下:
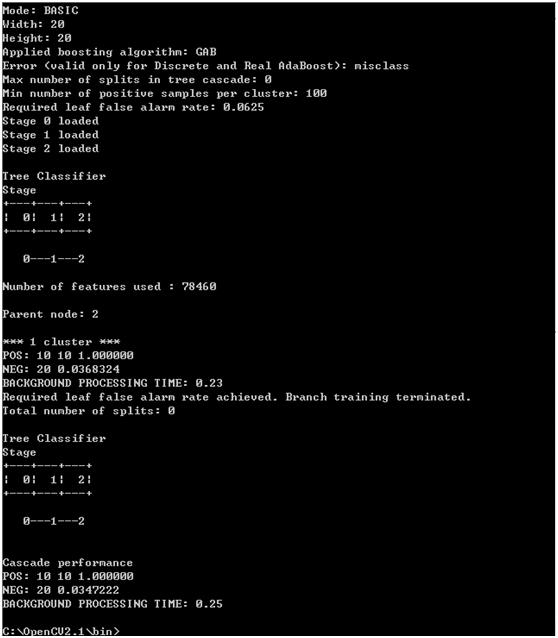
(可能实际结果与上图有出入, 但看到最后的 ,就说明训练成功了。
,就说明训练成功了。
在bin目录会生成一份可爱的data.xml文档,这个就是我们想要的结果了!
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/tyt2222008/archive/2010/08/25/5838389.aspx














 1376
1376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









