







一、分类器制作
1.样本准备
收集好你所需的正样本,和负样本,分别保存在不同文件夹
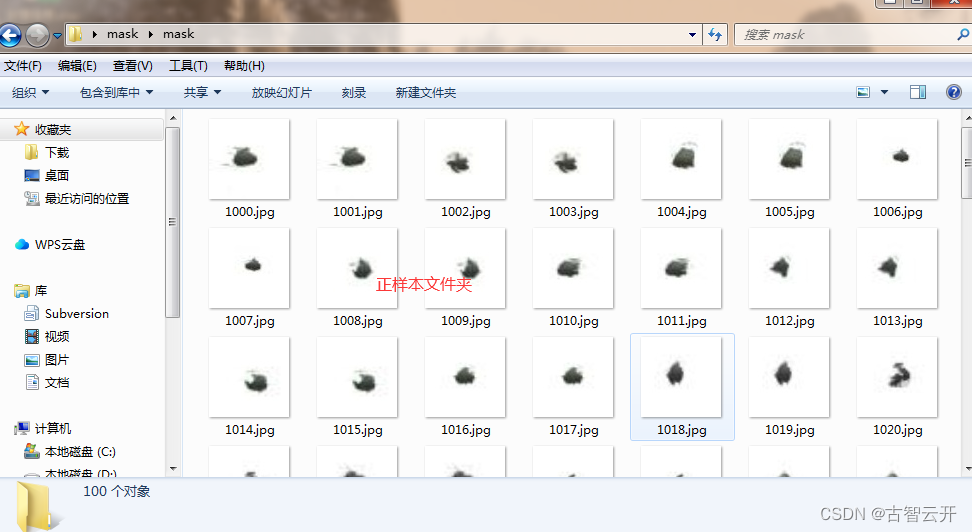
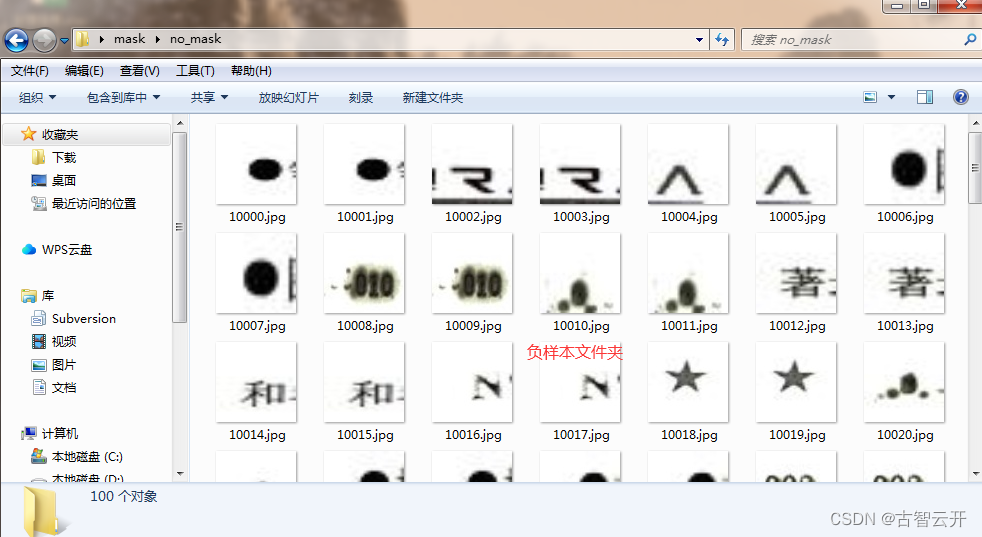
在pycharm新建项目,项目结构如下:has_mask文件夹放置正样本,no_mask文件夹放置负样本
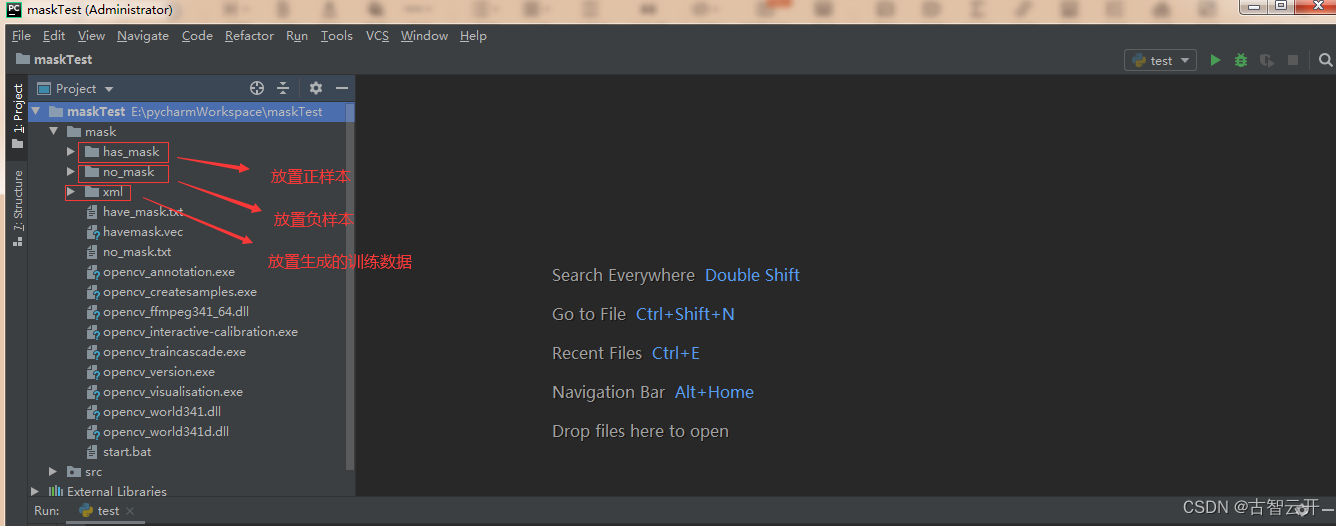
安装opencv,把opencv包里的文件复制到项目mask文件夹下
2.样本制作
(1)图片重命名
方便对样本进行批量处理,我们需要对样本进行重命名,重命名代码如下:
import os
# 正样本的路径
path = r'E:\pycharmWorkspace\maskTest\mask\has_mask'
filelist = os.listdir(path)
# 开始文件名1000.jpg
count = 1000
for file in filelist:
Olddir = os.path.join(path, file)
if os.path.isdir(Olddir):
continue
filename = os.path.splitext(file)[0]
filetype = os.path.splitext(file)[1]
Newdir = os.path.join(path, str(count) + filetype)
os.rename(Olddir, Newdir)
count += 1
# 负样本的路径
path = r'E:\pycharmWorkspace\maskTest\mask\no_mask'
filelist = os.listdir(path)
# 开始文件名10000.jpg
count = 10000
for file in filelist:
Olddir = os.path.join(path, file)
if os.path.isdir(Olddir):
continue
filename = os.path.splitext(file)[0]
filetype = os.path.splitext(file)[1]
Newdir = os.path.join(path, str(count) + filetype)
os.rename(Olddir, Newdir)
count += 1
(2)修改图片像素
将正样本尺寸统一修改为20×20来提高模型训练精度,负样本数据集像素不低于50×50
import cv2
# 代表正数据集中开始和结束照片的数字
for n in range(1000, 1099):
path = r'C:\Users\Administrator\Desktop\mask\mask/' + str(n) + '.jpg'
# 读取图片
img = cv2.imread(path)
img = cv2.resize(img, (20, 20)) # 修改样本像素为20x20
cv2.imwrite(r'C:\Users\Administrator\Desktop\mask\mask/' + str(n) + '.jpg', img)
n += 1
# 代表正数据集中开始和结束照片的数字
for n in range(10000, 10099):
path = r'C:\Users\Administrator\Desktop\mask\no_mask/' + str(n) + '.jpg'
# 读取图片
img = cv2.imread(path)
img = cv2.resize(img, (80, 80)) # 修改样本像素为80x80
cv2.imwrite(r'C:\Users\Administrator\Desktop\mask\no_mask/' + str(n) + '.jpg', img)
n += 1这里用到了python opencv库,在pycharm 控制台下用pip安装,以下命令可以解决opencv库安装速度慢的问题
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python --no-cache-dir
3.生成资源记录文件
在控制台进入has_mask文件夹

输入以下代码即可创建路径文件
dir /b/s/p/w *.jpg > have_mask.txt此时在have_mask下就会产生一个have_mask.txt文件,并将其放到mask目录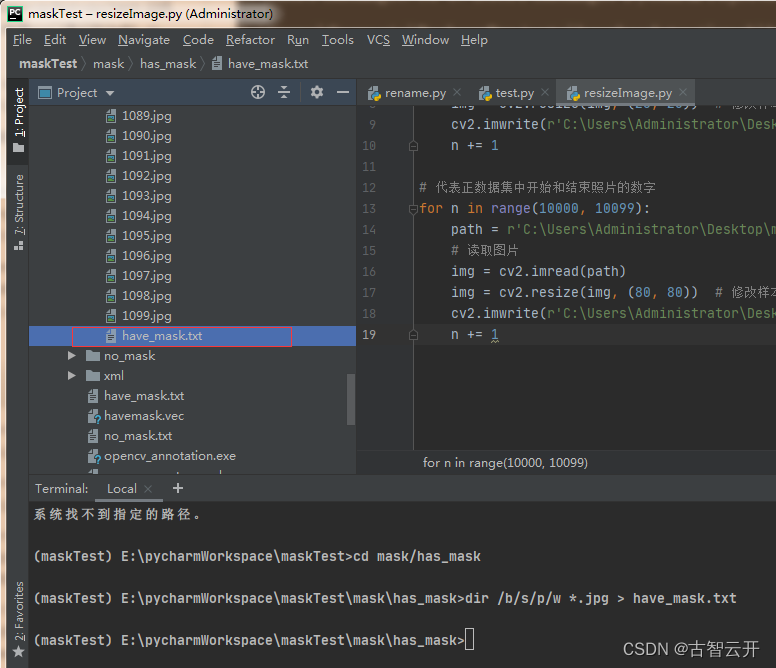
进入no_mask文件夹,重复上述步骤即可
最后结果如下

之后要对正样本进行预处理,在have_mask.txt末尾加入1 0 0 20 20执行以下代码即可
#后缀
Houzhui=r" 1 0 0 20 20"
filelist = open(r'E:\pycharmWorkspace\maskTest\mask\have_mask.txt','r+',encoding = 'utf-8')
line = filelist.readlines()
for file in line:
file=file.strip('\n')+Houzhui+'\n'
print(file)
filelist.write(file)
filelist = open(r'E:\pycharmWorkspace\maskTest\mask\no_mask.txt','r+',encoding = 'utf-8')
line = filelist.readlines()
for file in line:
file=file.strip('\n')+Houzhui+'\n'
print(file)
filelist.write(file)
4.生成vec文件
在terminal控制台进入到 mask 文件夹,然后输入如下命令
opencv_createsamples.exe -vec havemask.vec -info have_mask.txt -num 400 -w 20 -h 20opencv_createsamples.exe参数的说明:
-vec <vec_file_name>
输出文件,内含用于训练的正样本。他应该有一个.vec文件扩展名。
-info <file_name>
这是指定输入示例集合的文件的名字,包括文件名和在图像中示例目标的位置(例如自己创建的.dat
文件)。
-img <image_file_name>
这是-info的替代(必须提供其中一个)。使用-img,你可以提供单个裁剪的正向示例。在使用-img的
模式中,将产生多个输出,且都来自于这一个输入。
-bg <background_file_name>
背景图像的描述文件,文件中包含一系列的图像文件名,这些图像将被随机选作物体的背景。
-num <number_of_samples>
生成的正样本的数目。
-bgcolor <background_color>
背景颜色(目前为灰度图);背景颜色表示透明颜色。因为图像压缩可造成颜色偏差,颜色的容差
可以由 -bgthresh 指定。所有处于 bgcolor-bgthresh 和 bgcolor+bgthresh 之间的像素都被设置为
透明像素。
-bgthresh <background_color_threshold>
-inv
如果指定该标志,前景图像的颜色将翻转。
-randinv
如果指定该标志,颜色将随机地翻转。
-maxidev <max_intensity_deviation>
前景样本里像素的亮度梯度的最大值。
-maxxangle <max_x_rotation_angle>
X轴最大旋转角度,必须以弧度为单位。
-maxyangle <max_y_rotation_angle>
Y轴最大旋转角度,必须以弧度为单位。
-maxzangle <max_z_rotation_angle>
Z轴最大旋转角度,必须以弧度为单位。
-show
很有用的调试选项。如果指定该选项,每个样本都将被显示。如果按下 Esc 键,程序将继续创建样
本但不再显示。
-w <sample_width>
输出样本的宽度(以像素为单位)。
-h <sample_height>
输出样本的高度(以像素为单位)。

得到havemask.vec文件
5.训练模型
在当前文件夹下新建start.bat文件加入以下代码
opencv_traincascade.exe -data xml -vec havemask.vec -bg no_mask.txt -numPos 100-numNeg 100-numStages 20 -w 20 -h 20 -mode ALL
pause

在terminal执行start.bat
训练完成后在xml文件下即可看到以下文件,第一个文件即为我们训练好的分类器
二、检验分类器
输入以下代码
import cv2
#加载分类器
mask_detector = cv2.CascadeClassifier(r'E:\pycharmWorkspace\maskTest\mask\xml\cascade.xml')
img = cv2.imread(r'D:\0001.jpg')
#转成灰度图片
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#进行预测
mask_face = mask_detector.detectMultiScale(gray, 1.1, 5, cv2.CASCADE_SCALE_IMAGE, (50,50), (200, 200))
for (x2, y2, w2, h2) in mask_face:
cv2.rectangle(img, (x2, y2), (x2 + w2, y2 + h2), (0, 255, 0), 2)
cv2.putText(img, "have_mask", (x2, y2), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow('mask', img)
cv2.imshow('mask', img)
cv2.imwrite(r'D:/test.jpg', img)
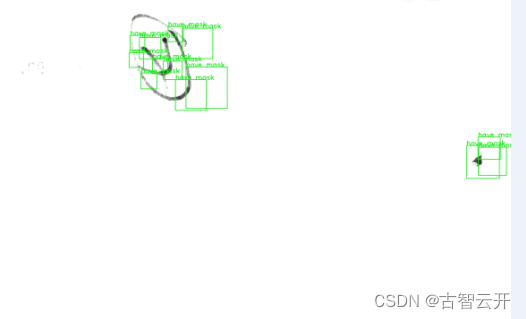
cv2.waitKey()得到如下测试结果 ,效果不是很好
















 3586
3586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











