







一:背景
Reduce端连接比Map端连接更为普遍,因为输入的数据不需要特定的结构,但是效率比较低,因为所有数据都必须经过Shuffle过程。
二:技术实现
基本思路
(1):Map端读取所有的文件,并在输出的内容里加上标示,代表数据是从哪个文件里来的。
(2):在reduce处理函数中,按照标识对数据进行处理。
程序运行的结果如下:
Reduce端连接比Map端连接更为普遍,因为输入的数据不需要特定的结构,但是效率比较低,因为所有数据都必须经过Shuffle过程。
二:技术实现
基本思路
(1):Map端读取所有的文件,并在输出的内容里加上标示,代表数据是从哪个文件里来的。
(2):在reduce处理函数中,按照标识对数据进行处理。
(3):然后根据Key去join来求出结果直接输出。
#需求:现有user表和city表,按cityID进行连接
user表:
1 zhangSan 1
2 liSi 2
3 wangWu 1
4 zhaoLiu 3
5 maQi 3
city表:
1 beiJin
2 shangHai
3 guangZhou
注:关于表连接操作,我们可以实现直接打标记的做法,看这里,也可以使用实体bean的方式。这篇文章是采用实体bean的方式实现表连接操作。
实现代码:
UserCity.java:
public class UserCity implements WritableComparable<UserCity>{
//用户ID
private String userNo = "";
//用户名
private String userName = "";
//城市ID
private String cityNo = "";
//城市名称
private String cityName = "";
//用户和城市的标志
private int flag = 0;
public UserCity() {
}
public UserCity(String userNo, String userName, String cityNo, String cityName, int flag) {
this.userNo = userNo;
this.userName = userName;
this.cityNo = cityNo;
this.cityName = cityName;
this.flag = flag;
}
public UserCity(UserCity user) {
this.userNo = user.getUserNo();
this.userName = user.getUserName();
this.cityNo = user.getCityNo();
this.cityName = user.getCityName();
this.flag = user.getFlag();
}
public String getUserNo() {
return userNo;
}
public void setUserNo(String userNo) {
this.userNo = userNo;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getCityNo() {
return cityNo;
}
public void setCityNo(String cityNo) {
this.cityNo = cityNo;
}
public String getCityName() {
return cityName;
}
public void setCityName(String cityName) {
this.cityName = cityName;
}
public int getFlag() {
return flag;
}
public void setFlag(int flag) {
this.flag = flag;
}
@Override
public void readFields(DataInput input) throws IOException {
this.userNo = input.readUTF();
this.userName = input.readUTF();
this.cityNo = input.readUTF();
this.cityName = input.readUTF();
this.flag = input.readInt();
}
@Override
public void write(DataOutput output) throws IOException {
output.writeUTF(this.userNo);
output.writeUTF(this.userName);
output.writeUTF(this.cityNo);
output.writeUTF(this.cityName);
output.writeInt(this.flag);
}
@Override
public int compareTo(UserCity o) {
return 0;
}
@Override
public String toString() {
return "userNo=" + userNo + ", userName=" + userName + ", cityName=" + cityName ;
}
}
UserCityJoinMapReduce.java:
public class UserCityJoinMapReduce {
//定义输入输出路径
private static final String INPATH = "hdfs://liaozhongmin21:8020/reduceJoinFiles";
private static final String OUTPATH = "hdfs://liaozhongmin21:8020/out";
public static void main(String[] args) {
try {
//创建配置
Configuration conf = new Configuration();
//创建FileSystem
FileSystem fileSystem = FileSystem.get(new URI(OUTPATH), conf);
//判断输出文件是否存在,如果存在就进行删除
if (fileSystem.exists(new Path(OUTPATH))){
fileSystem.delete(new Path(OUTPATH), true);
}
//创建Job
Job job = new Job(conf, UserCityJoinMapReduce.class.getName());
//设置输入文件的输入格式
job.setInputFormatClass(TextInputFormat.class);
//设置输入目录
FileInputFormat.setInputPaths(job, new Path(INPATH));
//设置自定义Mapper
job.setMapperClass(UserCityJoinMapper.class);
//设置Mapper输出的Key和Value
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(UserCity.class);
//设置分区
job.setPartitionerClass(HashPartitioner.class);
//设置Reducer的个数
job.setNumReduceTasks(1);
//设置自定义的Reducer
job.setReducerClass(UserCityJoinReducer.class);
//设置输出的格式化类
job.setOutputFormatClass(TextOutputFormat.class);
//设置输出目录
FileOutputFormat.setOutputPath(job, new Path(OUTPATH));
//设置输出的key和value
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
//提交任务
System.exit(job.waitForCompletion(true) ? 1 : 0);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class UserCityJoinMapper extends Mapper<LongWritable, Text, IntWritable, UserCity>{
//定义输出的key和value
private IntWritable outKey = new IntWritable();
private UserCity user = null;
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, IntWritable, UserCity>.Context context) throws IOException,
InterruptedException {
//获取行文本内容
String line = value.toString();
//对行文本内容进行切分
String[] splits = line.split("\t");
//对字符串数组进行判断
if (splits.length == 2){//如果长度为2就表示城市信息
//创建对象
user = new UserCity();
//设置属性
user.setCityNo(splits[0]);
user.setCityName(splits[1]);
user.setFlag(0);
//设置输出的key
outKey.set(Integer.parseInt(splits[0]));
//把结果写出去
context.write(outKey, user);
} else if (splits.length == 3){//如果长度为3就表示是User对象
//创建对象
user = new UserCity();
//设置属性
user.setUserNo(splits[0]);
user.setUserName(splits[1]);
//不要忘记设置关联属性
user.setCityNo(splits[2]);
//设置标志:1表示用户
user.setFlag(1);
//设置输出去key(城市ID)
outKey.set(Integer.parseInt(splits[2]));
//把结果写出去
context.write(outKey, user);
}
}
}
/**
* 城市和用户是一对多(一个城市对应多个用户),也就是说相同key传过来之后的结果就是一个城市和多个用户(这个至关重要!)
* 问题:多对多怎么搞?
* @author 廖钟民
*2015年4月6日下午9:40:17
*/
public static class UserCityJoinReducer extends Reducer<IntWritable, UserCity, NullWritable, Text>{
//定义输出的value
private Text outValue = new Text();
//城市对象(用于存储唯一的城市)
private UserCity city = null;
//定义集合用于存储对象
private List<UserCity> userCities = new ArrayList<UserCity>();
@Override
protected void reduce(IntWritable key, Iterable<UserCity> values, Reducer<IntWritable, UserCity, NullWritable, Text>.Context context) throws IOException,
InterruptedException {
//使用list集合之前,要清空上一次的数据。
userCities.clear();
//遍历values,把结果装到List集合中
for (UserCity u : values){//这个values集合中只有一个城市对象,多个用户对象
if (u.getFlag() == 0){//如果标志为0表示城市对象,这个是唯一的City对象
city = new UserCity(u);
} else {//除了唯一的City对象外,其他的都是用户对象,把这些用户对象都添加到集合里
userCities.add(new UserCity(u));
}
}
//遍历集合(把用户对象的城市信息都给填补上)
for (UserCity user : userCities){
//给用户对象设置城市信息
user.setCityName(city.getCityName());
//设置写出去value
outValue.set(user.toString());
//把结果写出去
context.write(NullWritable.get(), outValue);
}
}
}
}
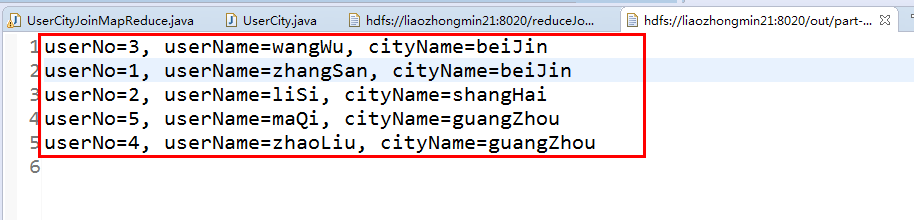
程序运行的结果如下:















 286
286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









