







栈式自编码:
一.基本原理
AE的原理是先通过一个encode层对输入进行编码,这个编码就是特征,然后利用encode乘第2层参数(也可以是encode层的参数的转置乘特征并加偏执),重构(解码)输入,然后用重构的输入和实际输入的损失训练参数。
对于我的应用来说,我要做的首先是抽取特征。AE的encode的过程很简单,是这样的:
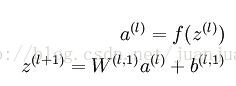
SAE是这样的:
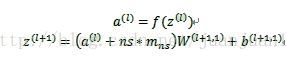
训练过程中,两个SAE分别训练,第一个SAE训练完之后,其encode的输出作为第二个SAE的输入,接着训练。训练完后,用第二层的特征,通过softmax分类器(由于分类器 还是得要带标签的数据来训练,所以,实际应用总,提取特征后不一定是拿来分类),将所有特征分为n类,得到n类标签。训练网络图
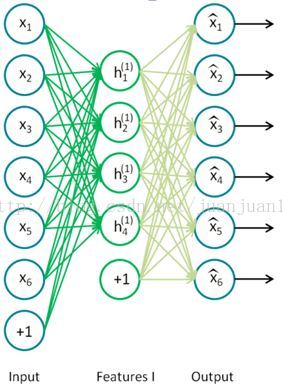
step 1
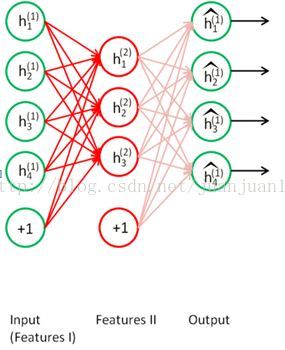
step 2
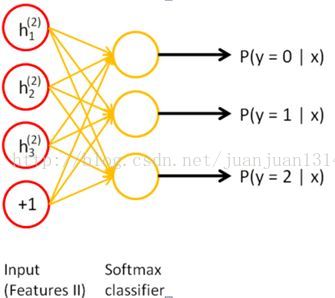
step 3
按照UFLDL的说明,在各自训练到快要收敛的时候,要对整个网络通过反向传播做微调,但是不能从一开始就整个网络调节。
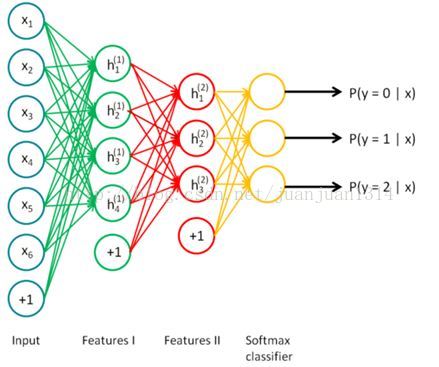
两个SAE训练完后,每个encode的输出作为两个隐层的特征,然后重新构建网络,新网络不做训练,只做预测。网络如下:
from __future__ import division, print_function, absolute_import
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 下载并导入MNIST数据集
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
# 参数
learning_rate = 0.01#学习率
training_epochs = 20#训练的周期
batch_size = 256#每一批次训练的大小
display_step = 1
# 神经网络的参数
n_hidden_1 = 256 # 隐层1的神经元个数
n_hidden_2 = 100 # 隐层2神经元个数
n_input = 784 # MNIST数据集的输出(img shape: 28*28)
n_output=10
# tf Graph input (only pictures)
X = tf.placeholder("float", [None, n_input])
weights = {
'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_1, n_input])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1])),
'softmax_w': tf.Variable(tf.random_normal([n_hidden_2, n_output])),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b1': tf.Variable(tf.random_normal([n_input])),
'decoder_b2': tf.Variable(tf.random_normal([n_hidden_1])),
'softmax_b': tf.Variable(tf.random_normal([n_output])),
}
#************************* 1st hidden layer **************
X = tf.placeholder("float", [None, n_input])
h1_out =tf.nn.sigmoid(tf.add(tf.matmul(X, weights['encoder_h1']),
biases['encoder_b1']))
keep_prob = tf.placeholder("float")
h1_out_drop = tf.nn.dropout(h1_out,keep_prob)
X_1 = tf.nn.sigmoid(tf.matmul(h1_out_drop,weights['decoder_h1'])+biases['decoder_b1'])
loss1 = tf.reduce_mean(tf.pow(X - X_1, 2))
train_step_1 = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss1)
sess=tf.Session()
sess.run(tf.variables_initializer([weights['encoder_h1'],biases['encoder_b1'],
weights['decoder_h1'],biases['decoder_b1']]))
# training
for i in range(training_epochs):
batch_x,batch_y = mnist.train.next_batch(batch_size)
_,c=sess.run([train_step_1,loss1],feed_dict={X:batch_x, keep_prob:1.0})
if i%5==0:
print(c)
#h1_out = tf.nn.sigmoid(tf.add(tf.matmul(X, weights['encoder_h1']),
# biases['encoder_b1']))
#get result of 1st layer as well as the input of next layer
#************************** 2nd hidden layer *************
h2_x = tf.placeholder("float", shape = [None, n_hidden_1])
h2_out = tf.nn.sigmoid(tf.matmul(h2_x,weights['encoder_h2']) + biases['encoder_b2'])
h2_out_drop = tf.nn.dropout(h2_out,keep_prob)
h2_in_decode = tf.nn.sigmoid(tf.matmul(h2_out_drop, weights['decoder_h2']) + biases['decoder_b2'])
loss2 = tf.reduce_mean(tf.pow( h2_x- h2_in_decode, 2))
train_step_2 = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss2)
sess.run(tf.variables_initializer([weights['encoder_h2'],biases['encoder_b2'],
weights['decoder_h2'],biases['decoder_b2']]))
for i in range(training_epochs):
#batch_x = numpy.reshape(batch_x,[batch_size,sample_length])
h1_out=[]
batch_x,batch_y = mnist.train.next_batch(batch_size)
temp=tf.nn.sigmoid(tf.add(tf.matmul(batch_x, weights['encoder_h1']),
biases['encoder_b1']))
h1_out.extend(sess.run(temp))
_,c=sess.run([train_step_2,loss2],feed_dict={h2_x:h1_out,keep_prob:1.0})
if i%5==0:
print(c)
#h2_out = tf.nn.sigmoid(tf.matmul(h1_out,weights['decoder_h2']) + biases['decoder_b2'])
#get result of 2nd layer as well as the input of next layer
#************************** softmax layer ****************
y_ = tf.placeholder("float", shape = [None, n_output])
soft_x = tf.placeholder("float", shape = [None, n_hidden_2])
y_out = tf.nn.softmax(tf.matmul(soft_x, weights['softmax_w']) + biases['softmax_b'])
cross_entropy = -tf.reduce_sum(y_ * tf.log(y_out))
train_step_soft = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_out, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess.run(tf.variables_initializer([weights['softmax_w'],biases['softmax_b']]))
for i in range(training_epochs):
h2_out=[]
batch_x,batch_y = mnist.train.next_batch(batch_size)
for i in range(batch_size):
temp=tf.nn.sigmoid(tf.add(tf.matmul(batch_x[i].reshape([1,784]), weights['encoder_h1']),
biases['encoder_b1']))
temp=tf.nn.sigmoid(tf.add(tf.matmul(temp, weights['encoder_h2']),
biases['encoder_b2']))
h2_out.extend(sess.run(temp))
sess.run(train_step_soft,feed_dict={soft_x:h2_out, y_:batch_y, keep_prob:1.0})
if i%5 == 0:
print(sess.run(accuracy, feed_dict={soft_x:h2_out, y_:batch_y, keep_prob:1.0}))
#fine-tuning
print ("************************* fine-tuning ***************************")
h1_out = tf.nn.sigmoid(tf.add(tf.matmul(X_1, weights['encoder_h1']),
biases['encoder_b1']))
h2_out = tf.nn.sigmoid(tf.matmul(h1_out,weights['encoder_h2']) + biases['encoder_b2'])
h2_out_drop = tf.nn.dropout(h2_out,keep_prob)
y_out = tf.nn.softmax(tf.matmul(h2_out_drop, weights['softmax_w']) + biases['softmax_b'])
cross_entropy = -tf.reduce_sum(y_ * tf.log(y_out))
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_out, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
for i in range(training_epochs):
batch_x,batch_y = mnist.train.next_batch(batch_size)
#batch_x = numpy.reshape(batch_x,[batch_size,sample_length])
sess.run(train_step,feed_dict={X:batch_x, y_:batch_y, keep_prob:0.5})
if i%5 == 0:
print (sess.run(accuracy,feed_dict={X:batch_x, y_:batch_y, keep_prob:0.5}))
print (sess.run(accuracy,feed_dict={X:batch_x, y_:batch_y, keep_prob:0.5}))














 113
113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









