







前言
自然正交分解(EOF),主成分分析(PCA)原来是一种方法,或者说是比较相似的方法。因为专业的原因,气象上用到EOF的时候比较多,而大学期间参加数模又接触到了主成分分析,可是那是的我从来没想到这是一种方法,哎,看算法原理没有看仔细。直到后来参加研究生赛的时候,学姐告诉我真相,这原来是一种方法啊。最近气象统计也主要讲这块,所以我就亲自实践了一下来惩罚我的不认真。
EOF&PCA 前提准备
X是经过减去时间距平处理后的数据,即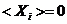
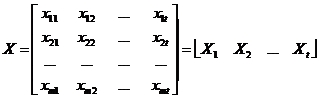
X是由m个格点的场形成t个时刻的时间序列
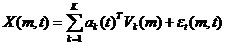
X可以被m个两两正交(模为特征值)的时间序列和m个两两正交的单位空间序列完全表达。此时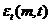
其中 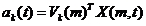
这里的V相当于坐标旋转系数,比如,对于一个二维空间,原来的基坐标是i=[1,0]和j=[0,1].有一个场向量是v=5i+6j, 下一时刻变为v2=7i+3j, 那么x可以表示为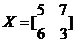
还有一点我觉得比较重要的是时间系数和各个模态分量的性质:
空间场:正交,单位向量(模为1); 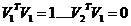
时间上,正交,模为特征值,(如果除以总特征值的和,代表的是对于原场时间序列解释的方差贡献率)。 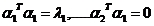
求证部分的思路:
1.任意向量的m维投影

得到
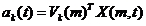
1.场的总误差:

可以看到场的误差是求一个场各个格点的时间的平均误差
2.第一特征向量的下的E1的表达式:
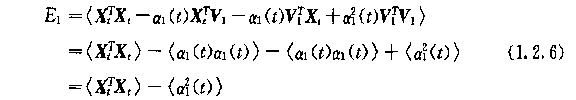
第一项为场的原始方差,后一项为模态V1代表误差,即第一时间序列的方差,算出来就是V1特征向量对应的特征值。可以理解为原来场的方差减去第一模态能解释的方差。我们当然希望能解释的越多越好,所以E1越小越好。
3.怎么求v1

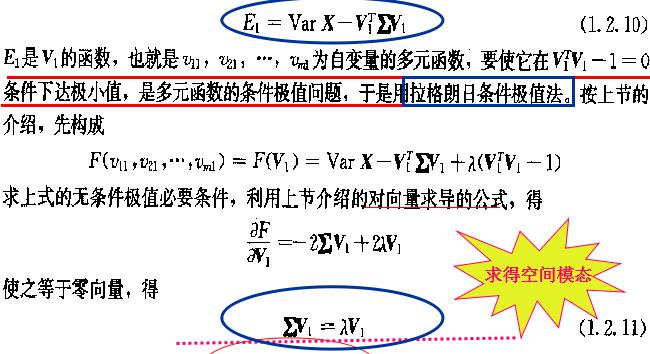
上面的拉格朗日求极值就是把限制条件加入到函数中来去掉限制条件。(不太明白为什么可以这么做,这是变成柔性边界了),但可以看定的是lamda肯定不为0,之后我们可以得到
做多模态只能是m和t中最小的一个,因为X的秩决定这特征值的数量,也就是lamda的数量。
根据上面求导可以知道,lamda就是X协方差的一个特征值。

为了使E1最小,就取特征值最大的了,特征值也是模态方差贡献率。
附向量求导的方法:
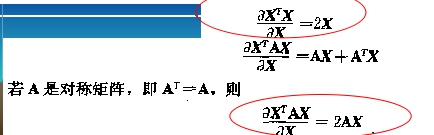
附拉格朗日乘数法则:

程序实现:
机器学习实战里面的程序:
'''
Created on Jun 1, 2011
@author: Peter Harrington
'''
from numpy import *
def loadDataSet(fileName, delim='\t'):
fr = open(fileName)
stringArr = [line.strip().split(delim) for line in fr.readlines()]
datArr = [map(float,line) for line in stringArr]
return mat(datArr)
def pca(dataMat, topNfeat=9999999):
meanVals = mean(dataMat, axis=0)
meanRemoved = dataMat - meanVals #remove mean
covMat = cov(meanRemoved, rowvar=0)
eigVals,eigVects = linalg.eig(mat(covMat))
# print 'V',eigVects[:,0].T*eigVects[:,1]
eigValInd = argsort(eigVals) #sort, sort goes smallest to largest
eigValInd = eigValInd[:-(topNfeat+1):-1] #cut off unwanted dimensions
redEigVects = eigVects[:,eigValInd] #reorganize eig vects largest to smallest
# print redEigVects
lowDDataMat = meanRemoved * redEigVects#transform data into new dimensions
# print 'T',lowDDataMat[:,0].T*lowDDataMat[:,1]
reconMat = (lowDDataMat * redEigVects.T) + meanVals
return lowDDataMat, reconMat
def replaceNanWithMean():
datMat = loadDataSet('secom.data', ' ')
numFeat = shape(datMat)[1]
for i in range(numFeat):
meanVal = mean(datMat[nonzero(~isnan(datMat[:,i].A))[0],i]) #values that are not NaN (a number)
datMat[nonzero(isnan(datMat[:,i].A))[0],i] = meanVal #set NaN values to mean
return datMat我自己编的程序:
################################
# File Name: PCA.py
# Author: Trichtu
# Email: 996553232@qq.com
# Created Time: April 20th 2016
##################################
#coding=utf-8
import numpy as np
def PCA(mat,value,mode):
'rows are time or something and columns are variablea and '
'mode = 1, value is percent,such as 0.99 0.95 0.9'
'mode = 0, value is number ,such as 3 4 no more than len(matp[1,:])'
meanval = np.mean(mat,axis=0)
mat_abnormal = mat-meanval# every column minus average
covMat=np.cov(mat_abnormal,rowvar=0)
eigval,eigvec = np.linalg.eig(np.mat(covMat))# eigvalue is descending ranked
attribution=np.cumsum(eigval)/sum(eigval)
if mode==1:
number=[i for i in range(len(attribution)) if attribution[i]>=value][0]+1
elif mode==0:
number=value
Z=eigvec[:,:number]#each columns reprsent a eig vector
y=mat_abnormal*Z #the component
remat=y*Z.T+meanval
return remat,Z,y,attribution用一个二维数据1000时次的数据做实验,发现时间系数的模是1e-13,并不是完美的0,模态的模是0。用机器学习实战书中的代码和python里面sklearn包的PCA接口程序作对比如下:
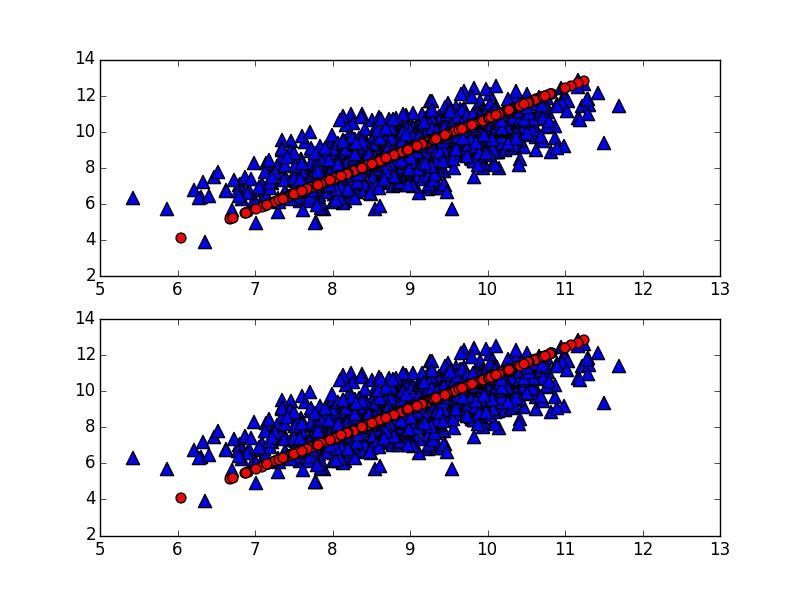
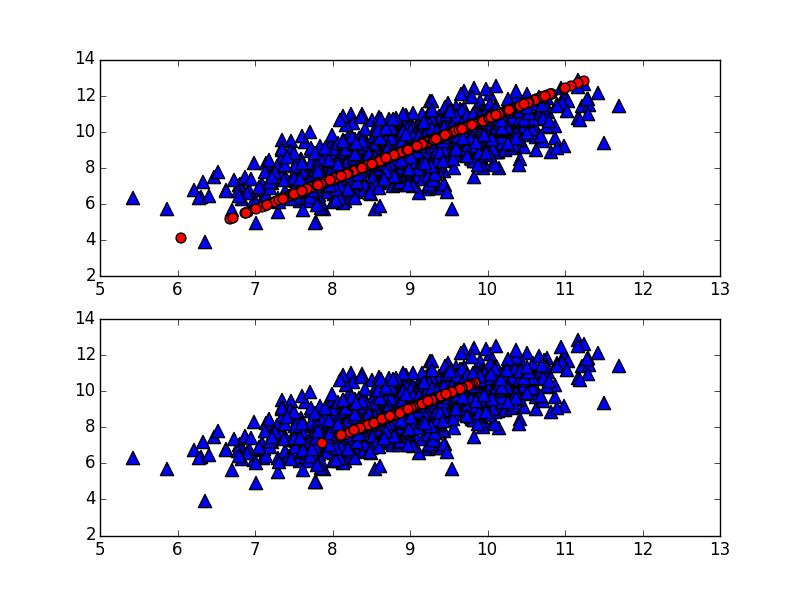
第二张图下面是sklearn里面的whiten选项为True的时候情况,不知道是怎么做的。正常情况下whiten=False时,两个程序一样。红线是主成分和载荷向量(模态)重构之后的情况。














 3107
3107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









