









面对五花八门的数据集,各种各样的数据存储形式,刚新手入门的我们在处理这些情况的时候是否会手足无措?反正一路走来,我的经验告诉我,deep learning的实验阶段,数据准备和处理过程往往会让你碰一鼻子灰。明明知道如何搭建网络,还是完成不了实验,究其原因,是数据工程经验的不足。
我打算做这个系列,主要是记录针对不同种类,格式的数据的处理方案。数据预处理的首篇,我为大家展示一种常见情形的处理方法
一.问题背景
问题的背景是面对raw image数据集,但是图片按label为文件夹存放。以Office-31数据集为例。
Office-31数据集是一个用于迁移学习算法性能测试的数据集,我已经上传到网上,下载地址在下面:
domain_adaptation_images.part1.rar
domain_adaptation_images.part2.rar
权限不够,上传了两个分卷。解压完以后出现这个文件
下面又是三个文件,这三个就是不同环境下拍摄的图,我们只需要进amazon即可

最后这个文件夹下有各种各样的类,每一个类文件夹,相当于一个label。
进到具体label下面,则出现各种各样的图片。
描述这样一个问题背景是有意义的,因为实际上很多图片数据集都是以这样的形式来存放。
以此为范例,下面来记录一个这个问题的具体解决方案。
二.解决方案
首先说一下需要用到的辅助工具,前一篇讲到的skimage(【Tensorflow】辅助工具篇——scikit-image介绍),cPickle,matplotlib
鉴于这里有三个domain的数据,我们只做amazon这个文件夹下图片的处理
先上代码。
def build_dataset(data_dir, out_dir, weight=100,hight=100):
data_dir = os.path.join(data_dir,"images")
for _, dirnames, _ in os.walk(data_dir):
for dirname in dirnames:
index = dirnames.index(dirname)
workdir = os.path.join(data_dir, dirname)
#images = io.imread_collection(workdir + '/*.jpg')
processed_images = io.ImageCollection(workdir + '/*.jpg', load_func=process_image, weight=weight,hight=hight)
label = np.full(len(processed_images), fill_value=index, dtype=np.int32)
images = io.concatenate_images(processed_images)
if index == 0:
data = images
labels = label
else:
data = np.vstack((data,images))
labels = np.append(labels,label)
if not os.path.exists(out_dir):
os.makedirs(out_dir)
print "data shape:",data.shape
print "label shape:",labels.shape
save_pickle(data, out_dir+'/'+'amazon_images.pkl')
save_pickle(labels, out_dir+'/'+'amazon_labels.pkl')解决思路还是比较传统的。首先要遍历文件夹,对于每一个文件夹下面的所有图片,用skimage批量读出来
读取的过程是通过imread_collection函数将所有jgp图片读取出来,返回一个类(注意此时这个类并不是np数组,而是skimage中的ImageCollection类,所以他并不能直接使用,我们要通过concatenate_images函数将多个图片连接起来成为一个np数组)
但是我们没有使用imread_collection函数,而是使用了ImageCollection类的构造函数,直接构造一个ImageCollection类,主要是因为如果图像的大小像素不同会导致连接的时候报错(维度不同),所以我们要先完成图像的预处理,处理完了将所有的图resize到相同的大小。构造ImageCollection类的时候可以load进去一个处理函数,在这里是process_image函数:
def process_image(image, weight, hight):
img = io.imread(image)
img = transform.resize(img, (weight,hight), mode='reflect')
return img当然process_image函数里面我们还可以添加其他内容(裁剪,填充等)
另外,如果是可以保证原始图像的像素全部相等,那么我们也可以imread_collection读进来以后统一处理。这里我们主要针对的是更复杂的情况。
最后,使用pkl文件来保存。
def save_pickle(data, path):
with open(path, 'wb') as f:
pickle.dump(data, f, pickle.HIGHEST_PROTOCOL)
print ('Saved %s..' %path)在数据量不大的情况下,pkl是一种常用的保存手段,同时使用gzip来压缩,(我这里为了方便没有用),最常见的mnist就是用的pkl.gz这种后缀。同时cPickle又是pickle的升级版,压缩率好过pickle,大家可以尝试一下。
但是在数据量很大的清况下,我们一般使用hdf5,hdf5在性能方面是好过cPickle很多。这种方法后面会介绍。
当然也可以构造图片预处理的pipeline。这种方法是所有方案的终极版,专门针对超大数据集(ImageNet,CoCo)不可能全部load到内存中使用的,例如用CoCo数据集来做style transfer训练的时候用的就是线程读图片的方式,同时这种方法也是最难去实现的,同样后面也会介绍。
大功告成了!最后看一看结果吧。
同样还是用matplotlib来显示多个图片
import cPickle
from mpl_toolkits.axes_grid1 import ImageGrid
import matplotlib.pyplot as plt
def imshow_grid(images, shape=[2, 8]):
"""Plot images in a grid of a given shape."""
fig = plt.figure(1)
grid = ImageGrid(fig, 111, nrows_ncols=shape, axes_pad=0.05)
size = shape[0] * shape[1]
for i in range(size):
grid[i].axis('off')
grid[i].imshow(images[i]) # The AxesGrid object work as a list of axes.
plt.show()
def load_amazon():
data = cPickle.load(open('prosessed_data/amazon_images.pkl'))
labels = cPickle.load(open('prosessed_data/amazon_labels.pkl'))
return data,labels
data,labels = load_amazon()
print "show image..."
imshow_grid(data[90:106])
print labels[90:106]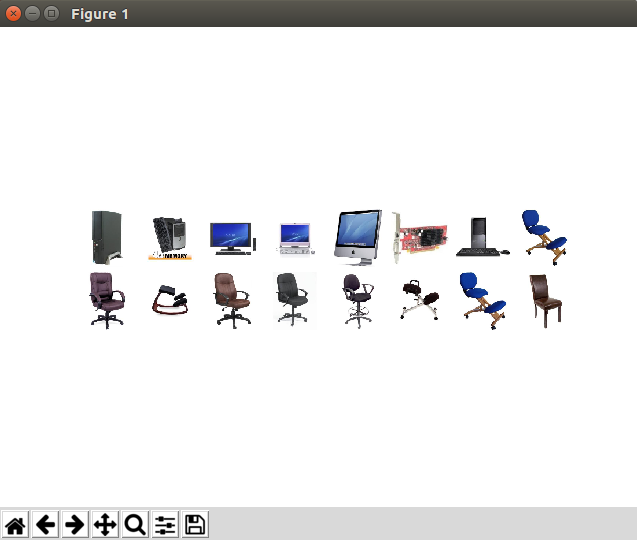
图片和label,看到是可以对上了,然后我们就可以下一步了。
[0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1]不要忘了数据的归一化!!比较简单的做法是计算(像素值-127.5)/127.5,这种做法是归一到-1到1之间,也可以算每个通道的均值,然后每个通道分别归一。
归一化相信大家都会,就不赘述了。
三.实验源码
import tensorflow as tf
import tensorflow.contrib.slim as slim
import os
from skimage import io,transform
from mpl_toolkits.axes_grid1 import ImageGrid
import argparse
import numpy as np
import cPickle
import matplotlib.pyplot as plt
parser = argparse.ArgumentParser(description='')
parser.add_argument('--dataset', dest='dataset', default='amazon', help='dataset name')
def save_pickle(data, path):
with open(path, 'wb') as f:
cPickle.dump(data, f, cPickle.HIGHEST_PROTOCOL)
print ('Saved %s..' %path)
def imshow_grid(images, shape=[2, 8]):
"""Plot images in a grid of a given shape."""
fig = plt.figure(1)
grid = ImageGrid(fig, 111, nrows_ncols=shape, axes_pad=0.05)
size = shape[0] * shape[1]
for i in range(size):
grid[i].axis('off')
grid[i].imshow(images[i]) # The AxesGrid object work as a list of axes.
plt.show()
def process_image(image, weight, hight):
img = io.imread(image)
img = transform.resize(img, (weight,hight), mode='reflect')
return img
def build_dataset(data_dir, out_dir, name,weight=100,hight=100):
data_dir = os.path.join(data_dir,"images")
for _, dirnames, _ in os.walk(data_dir):
for dirname in dirnames:
index = dirnames.index(dirname)
workdir = os.path.join(data_dir, dirname)
#images = io.imread_collection(workdir + '/*.jpg')
processed_images = io.ImageCollection(workdir + '/*.jpg', load_func=process_image, weight=weight,hight=hight)
label = np.full(len(processed_images), fill_value=index, dtype=np.int32)
images = io.concatenate_images(processed_images)
if index == 0:
data = images
labels = label
else:
data = np.vstack((data,images))
labels = np.append(labels,label)
if not os.path.exists(out_dir):
os.makedirs(out_dir)
print("data shape:")
print(data.shape)
print("label shape:")
print(labels.shape)
save_pickle(data, out_dir+'/'+name+'_images.pkl')
save_pickle(labels, out_dir+'/'+name+'_labels.pkl')
def load_amazon():
images = cPickle.load(open('prosessed_data/amazon/amazon_images.pkl'))
labels = cPickle.load(open('prosessed_data/amazon/amazon_labels.pkl'))
images = images*2 - 1
print ('finished loading amazon image dataset..!')
return images,labels
def load_dslr():
images = cPickle.load(open('prosessed_data/dslr/dslr_images.pkl'))
labels = cPickle.load(open('prosessed_data/dslr/dslr_labels.pkl'))
images = images * 2 - 1
print ('finished loading dslr image dataset..!')
return images,labels
def load_webcam():
images = cPickle.load(open('prosessed_data/webcam/webcam_images.pkl'))
labels = cPickle.load(open('prosessed_data/webcam/webcam_labels.pkl'))
images = images * 2 - 1
print ('finished loading webcam image dataset..!')
return images, labels
args = parser.parse_args()
def main():
print "make dataset..."
if args.dataset == 'amazon':
build_dataset("domain_adaptation_images/amazon","prosessed_data/amazon",args.dataset,weight=64,hight=64)
print "read dataset..."
images,label = load_amazon()
print "show image..."
imshow_grid((images[90:106]+1)/2)
print label[90:106]
elif args.dataset == 'dslr':
build_dataset("domain_adaptation_images/dslr", "prosessed_data/dslr",args.dataset, weight=64, hight=64)
print "read dataset..."
images, label =load_dslr()
print "show image..."
imshow_grid((images[90:106]+1)/2)
print label[90:106]
elif args.dataset == 'webcam':
build_dataset("domain_adaptation_images/webcam", "prosessed_data/webcam",args.dataset, weight=64, hight=64)
print "read dataset..."
images, label =load_webcam()
print "show image..."
imshow_grid((images[90:106]+1)/2)
print label[90:106]
else:
raise Exception("wrong args!!")
print "loading successful!"
if __name__ == "__main__":
main()














 6470
6470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









